Recognize authors style using the Gutenberg plugin¶
DSS comes with the great possibility to extend DSS yourself and benefits from extensions written by the community. Plugins enable you to write your own custom recipes and datasets.
This tutorial is going to be less technical since we are just going to use a ready-to-use plugin. The Gutenberg plugin enables you to retrieve and parse books from the Project Gutenberg website directly into your DSS instance. However this tutorial assumes that you are already a little bit familiar with DSS.
Prerequisites¶
We assume that you are already familiar with the basic concepts behind DSS. If not, please refer to the documentation or to the Basics courses.
Install the Plugin¶
You can download and install the Gutenberg plugin directly from the Plugin Store bundled in DSS. Go to the Application menu, choose Plugins, click on store, find the Gutenberg plugin and click on Install. Choose to build the new code environment when prompted.
You can find the full code of the plugin on the dataiku-contrib public repository.
Retrieve a Book¶
Create a new project and a create your first Gutenberg dataset:
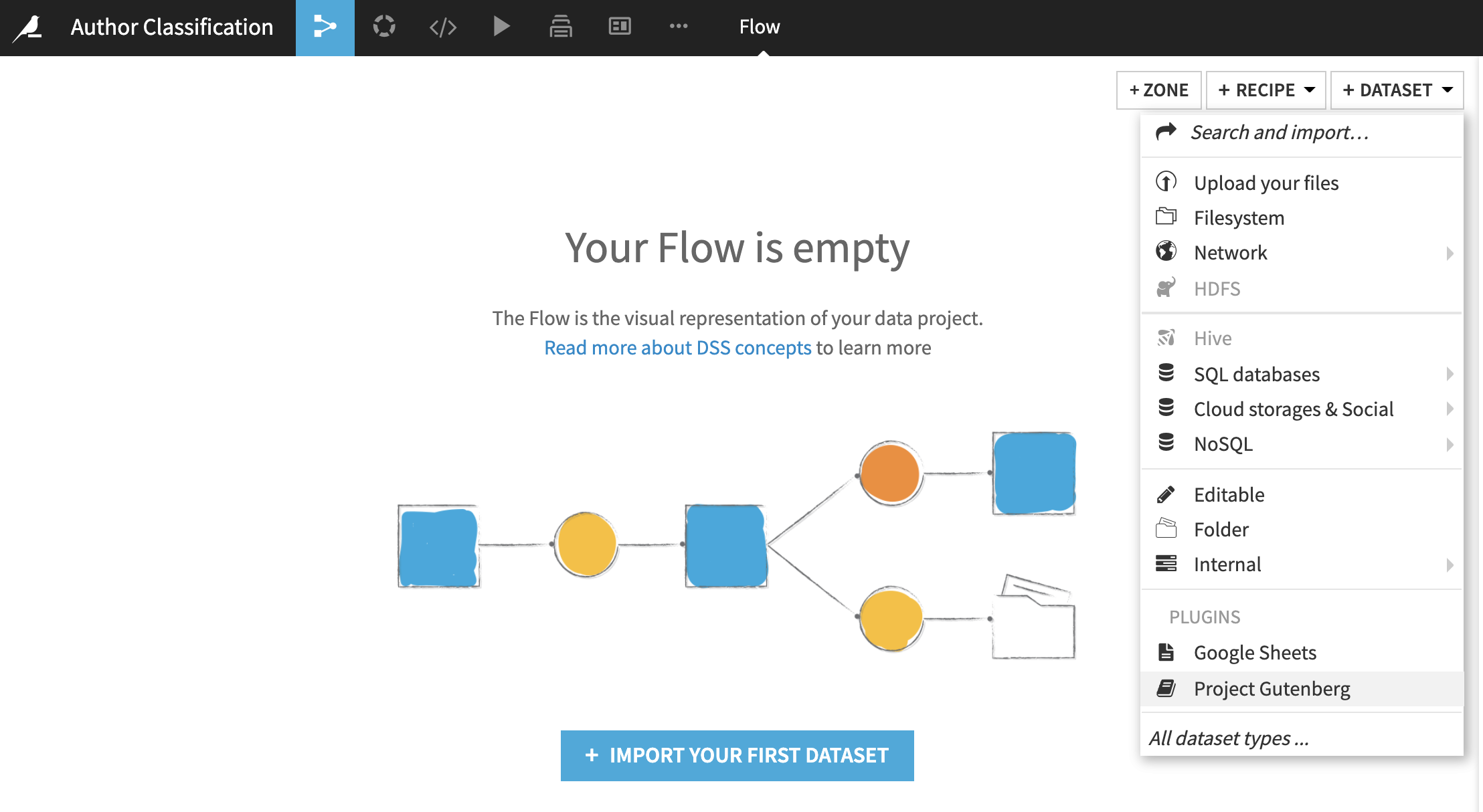
Project Gutenberg assigns an id to each book. First go to their search engine to find a book you would like to download. Once you have found the book of your choice you can figure out the id by looking at the end of the URL or by looking at the preamble of the book. You may change the mirror to a closer location from where you are.
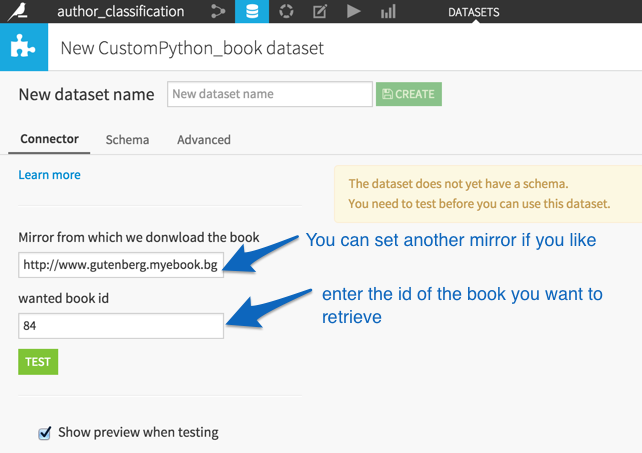
Once you have entered a valid book id, click on Test, then on Create.
Building Train and Test sets¶
We are going to use books from two authors and see if a predictive model can tell by which author a given paragraph is written.
We chose to work with Charles Dickens and Mark Twain books because they are contemporary authors and wrote about similar subjects (rueful poor orphan kids). Feel free to use other books. Indeed, it would be interesting to see how the model performance vary with the chosen authors.
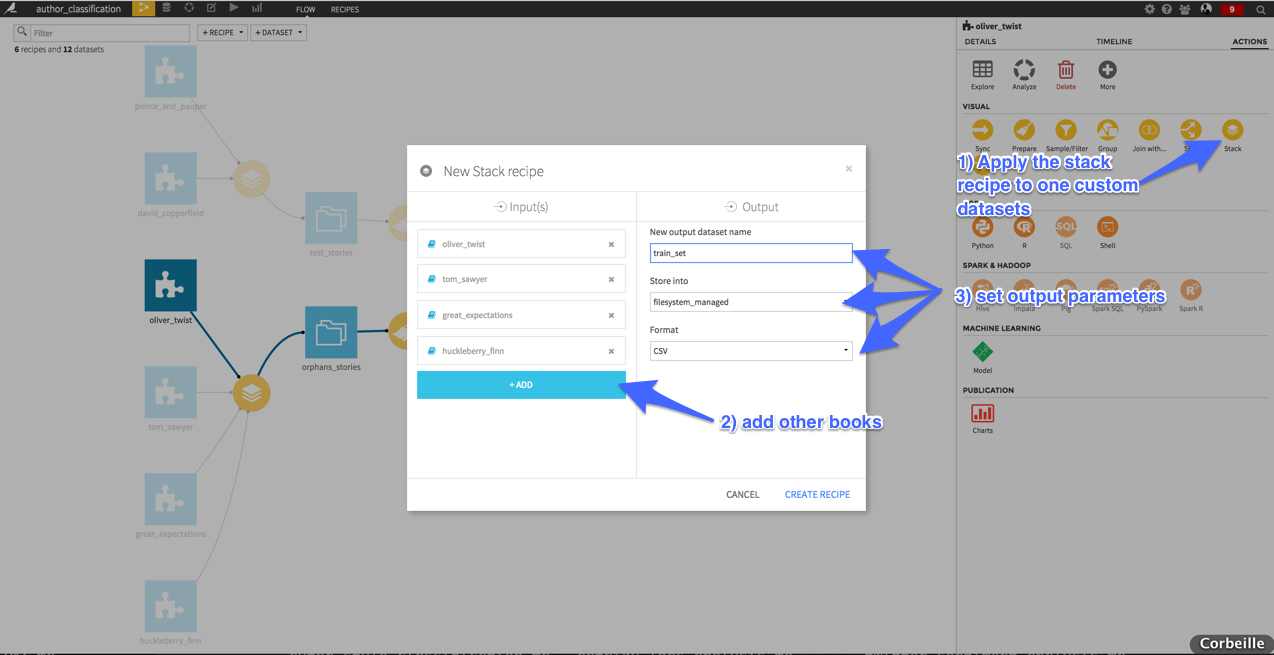
We constructed a train dataset with two books written by Charles Dickens (Oliver Twist and Great Expectations) and two written by Mark Twain (Tom Sawyer and Huckleberry Finn). The test set is composed of David Copperfield and The Prince and the Pauper from Charles Dickens and Mark Twain respectively. To do so we created a custom dataset “book” and set the id for each book. Then we use a stack recipe to compile the books of the train and the books test set.
First Naïve Model¶
Let’s build a first model on the train test. We are going to use the built-in DSS tools to extract features from text, namely the count vectorizer and the logistic regression. We will use paragraphs text as feature. Your features settings should look like that:
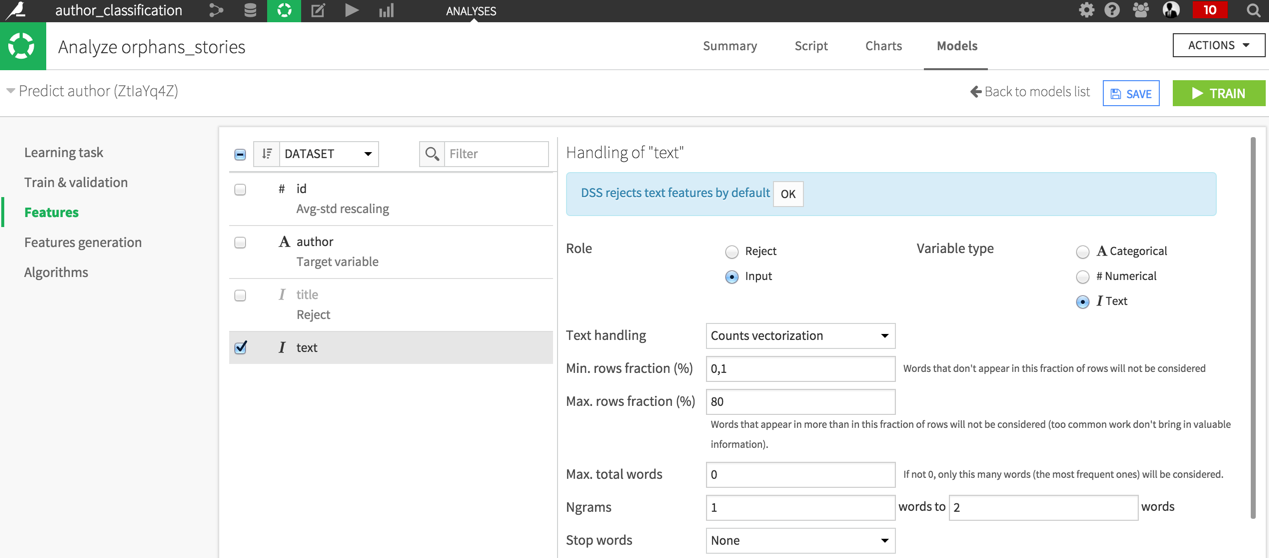
The performance of the model is very high when computed on a random sample of the train set:
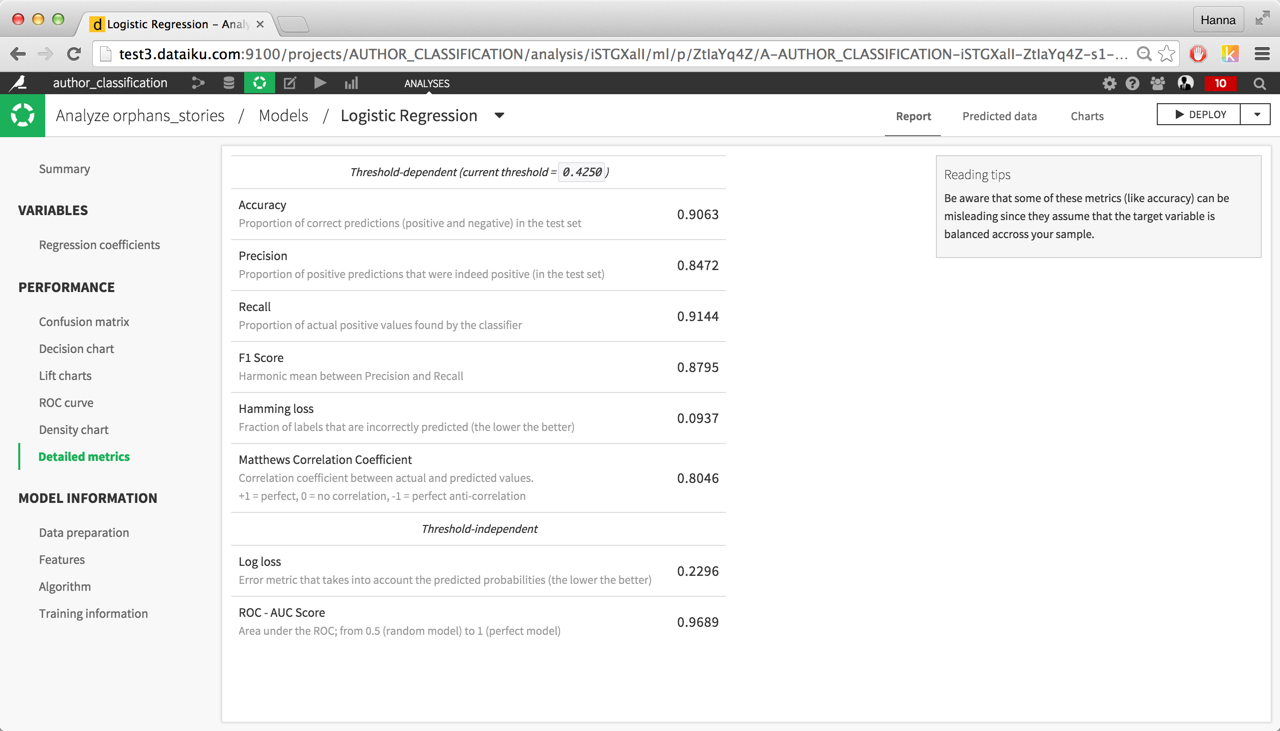
If we check the logistic regression coefficients, we immediately see that the most important ones are characters names. Indeed, on the train set, using presence of a main character’s name in the paragraph is a very good way to determine the author of the paragraph. However, it won’t generalize well. Indeed character names will be completely useless on another book with different protagonists. Besides, these coefficients don’t tell us anything interesting about the authors’ style.
To properly evaluate our model we have to use different books for the test set. DSS offer the possibility to evaluate a model with an explicitly defined test set. Go to the model settings, then to the train and validation tab and explicitly set the train and the test set.
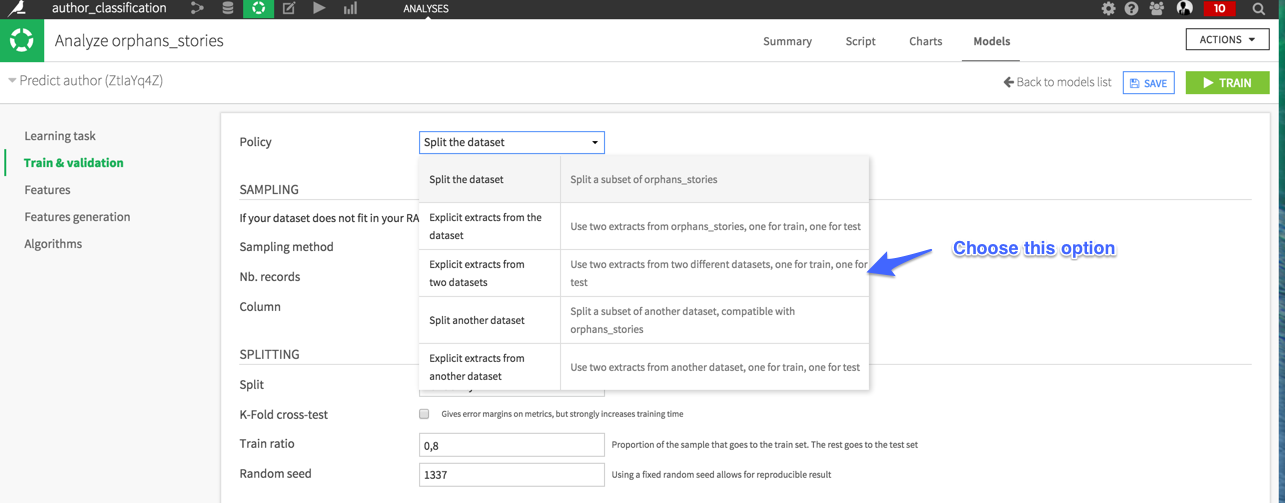
Train the model, and check the performance. Scores are still good but much lower than with the random split of the train set. The random split of the train set is the simplest way to construct a test set however, as we have seen, it can give an over-optimistic evaluation of the model performance. It happens when the model overfits a peculiarity of the train set.
Our model overfitted the character presence and didn’t learn enough about the author’s style. We are going to refine our text features to improve our style recognizer and try to avoid train set overfitting.
Feature Engineering on Text¶
Create a preparation script on your train set. First of all we would like to avoid overfitting by learning on character presence. So we are going to replace characters names by the neutral pronoun “he”. To do so, use the “Find and Replace” processor, with matching mode set to “Regular Expression” and “Normalization mode” to Lowercase. Here is the regular expression to insert in the “find” pattern:
\btom\b|\bhuck\b|\boliver\b|\bfagin\b|\bherbert\b|\bpip\b|\bjim\b|\binjun\b|
\bjoe\b|\bcompeyson\b|\bhavisham\b|\bnoah\b|\bsharley\b|\bmary\b|\bestella\b
Basically, it recognizes every occurrence of a full character name. If you didn’t use the same set of books, you can retrieve character names overfitted by the model by looking at the largest logistic regression coefficients.
It is well known that some author fancy long sentences, You can have forgotten the beginning of a sentence of the In Search of Lost Time by Proust by the time you reach the end. Whereas other author have punchy short sentences like Bukowsky. It is of course very simplistic to summarize an author style by the length of the sentences he uses. However alongside with the document-term matrix it is an interesting information to retrieve. We are going to compute a feature counting the number of sentences by paragraph and a feature that compute the mean length of sentences by paragraph. Guess what! With DSS, we can easily apply custom Python code in the preparation script to create complex features from other columns (using the “Custom Python” processor):
Here is the code to to evaluate paragraphs length:
import re
def process(row):
return len(re.split('[.?!]',row['text_without_characters']))
To compute sentence length:
import re
def process(row):
return len(re.split('[.?!]',row['text_without_characters']))
You could create as many features as you can imagine. Why not count punctuation signs for instance?
Once you have carefully cleaned and completely finished creating your features, you can copy the preparation script and apply it to your test set. Remove all character names replacements on the test because it doesn’t make any sense on other books.
Retrain the model on the text_without_character columns, You should reach an AUC of 0.931, which is fairly satisfying with 90% of paragraph correctly classified (Accuracy).
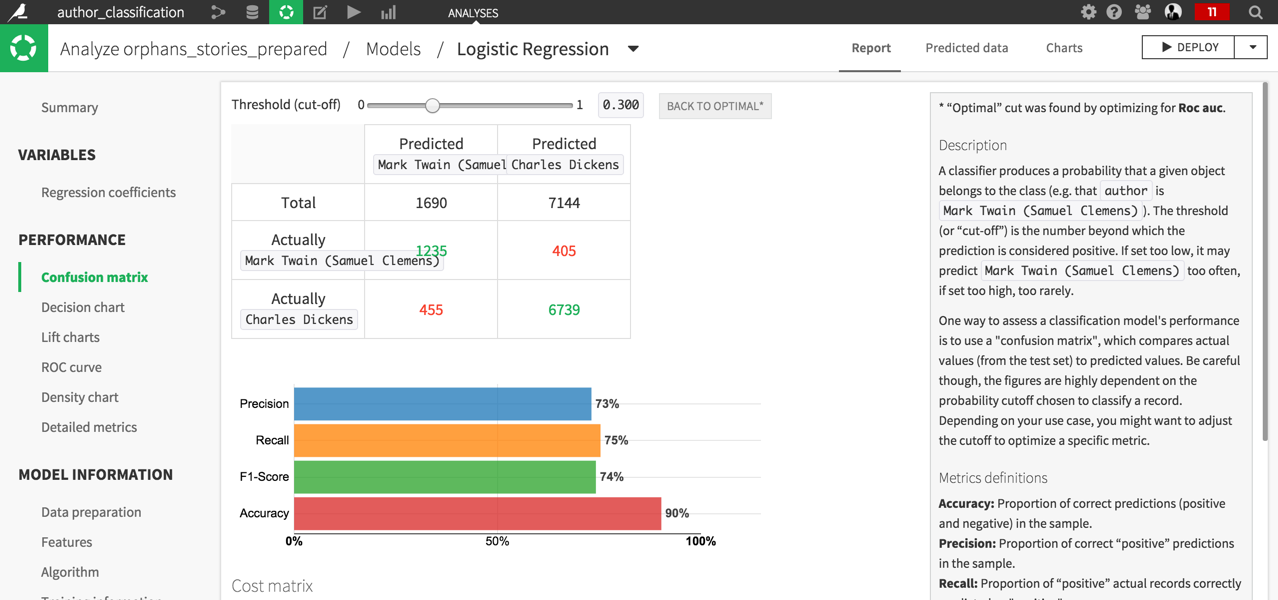
Once you have obtained a satisfying model and correctly tested it, you can deploy it in a retrainable model (you could for instance add books at the beginning of the flow) and apply it to the test set or to another book. See the Machine Learning Basics course to learn how to deploy and apply models.
Models Interpretation¶
We can now analyze regression coefficients to find insights on author’s style. Since Mark Twain has arbitrarily been taken as the positive classes, the negative coefficients means that the highest the word count the likelihood of the paragraph being written by Charles Dickens whereas positive coefficients denote words more likely to be used by Mark Twain.
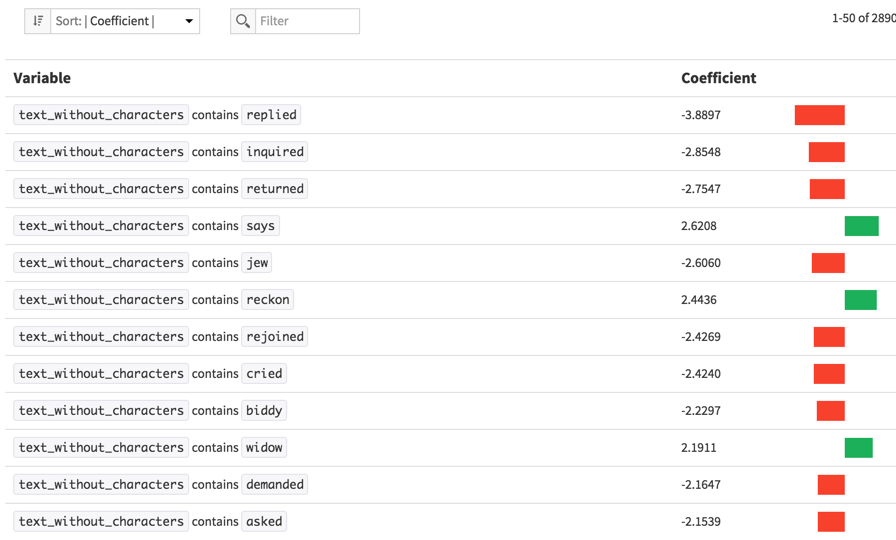
First remark, Charles Dickens avoids the use of “say” by employing numerous synonyms whereas Twain does use it. The model captures colloquial tournures used by Charles Dickens to make his writing more lively (like chap, ma am). We also see that words that capture “geographic” features associated to the United States like “dollars” and “buck” are of course more likely used by Twain than Dickens.
Conclusion: Could an algorithm identify unknown pen names?¶
Interestingly, a simple model is able to classify paragraph between two authors. Today’s telling if a document has been written by the same author as another set of documents is an active research subject
To go further, we could add more complex features by using a part of speech tagger for instance. We could also n-grams of higher order and manage the very high number of features by using the hashing trick.