Overview¶
Business Case¶
A “smart city” initiative has received data from the Washington DC bike sharing system. They want to use this data to gain a better understanding of the usage patterns across the city. Any discovered patterns can be used to improve the bike sharing system for customers and the city’s overall transit efforts.
As a first step towards this goal, we will try to identify clusters of “similar” bike stations. Station similarity will be based on the types of users beginning trips from each station.
Supporting data¶
This use case incorporates the following data sources:
Trips
Capital Bikeshare provides data on each bike trip, including an index of the available data. We will use a Download recipe in the walkthrough to create datasets from 2016 and 2017 files.
Bike Stations
Capital Bikeshare provides an XML file with the list of bike stations and associated information about each station. We will use a Download recipe in the walkthrough to create a dataset from this file.
Demographics
We can use US census data to enrich the bike stations dataset with demographic information at the “block group” geographic level. Its archive can be downloaded here.
Workflow Overview¶
The final Dataiku DSS pipeline appears below. You can also find a completed version of the project in the Dataiku gallery.
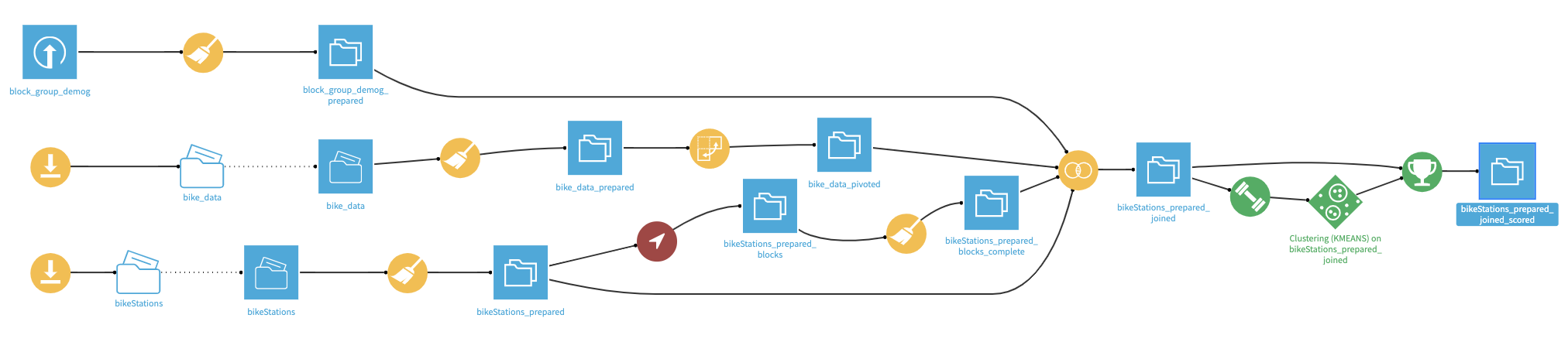
The Flow has the following high-level steps:
Collect the data to form the input datasets
Clean the datasets
Join the datasets based on census blocks and station IDs
Create and deploy a clustering model
Update the model based upon new data
Prerequisites¶
You should be familiar with:
The Basics courses,
The Pivot recipe,
Machine Learning in Dataiku DSS
Technical Requirements¶
The Get US census block plugin is required to enrich the bike station data with its US census block, so that it can be joined with the per-block demographic information.