Using the Model¶
Let’s use this Random Forest model to generate predictions on the unlabelled scoring dataset. Remember, the goal is to assign the probability of a car’s failure.
From within the Lab, select the Model page and find the Deploy button near the top right.
Because we created this visual analysis from the training dataset, it should already be selected as the Train dataset in the “Deploy prediction model” window.
In the same window, you might change the default Model name to
Prediction of failure on training data. Click Create.In the Flow, select the model we just created. Initiate a Score recipe from the right sidebar.
Select scoring as the input dataset and Prediction of failure on training data as the Prediction Model. Name the output dataset
scored.Create and run the recipe with the default settings.
Note
There are multiple ways to score models in Dataiku DSS. For example, in the Flow, if selecting a model first, you can use a Score recipe (if it’s a prediction model) or an Apply model (if it’s a cluster model) on a dataset of your choice. If selecting a dataset first, you can use a Predict or Cluster recipe with an appropriate model of your choice.
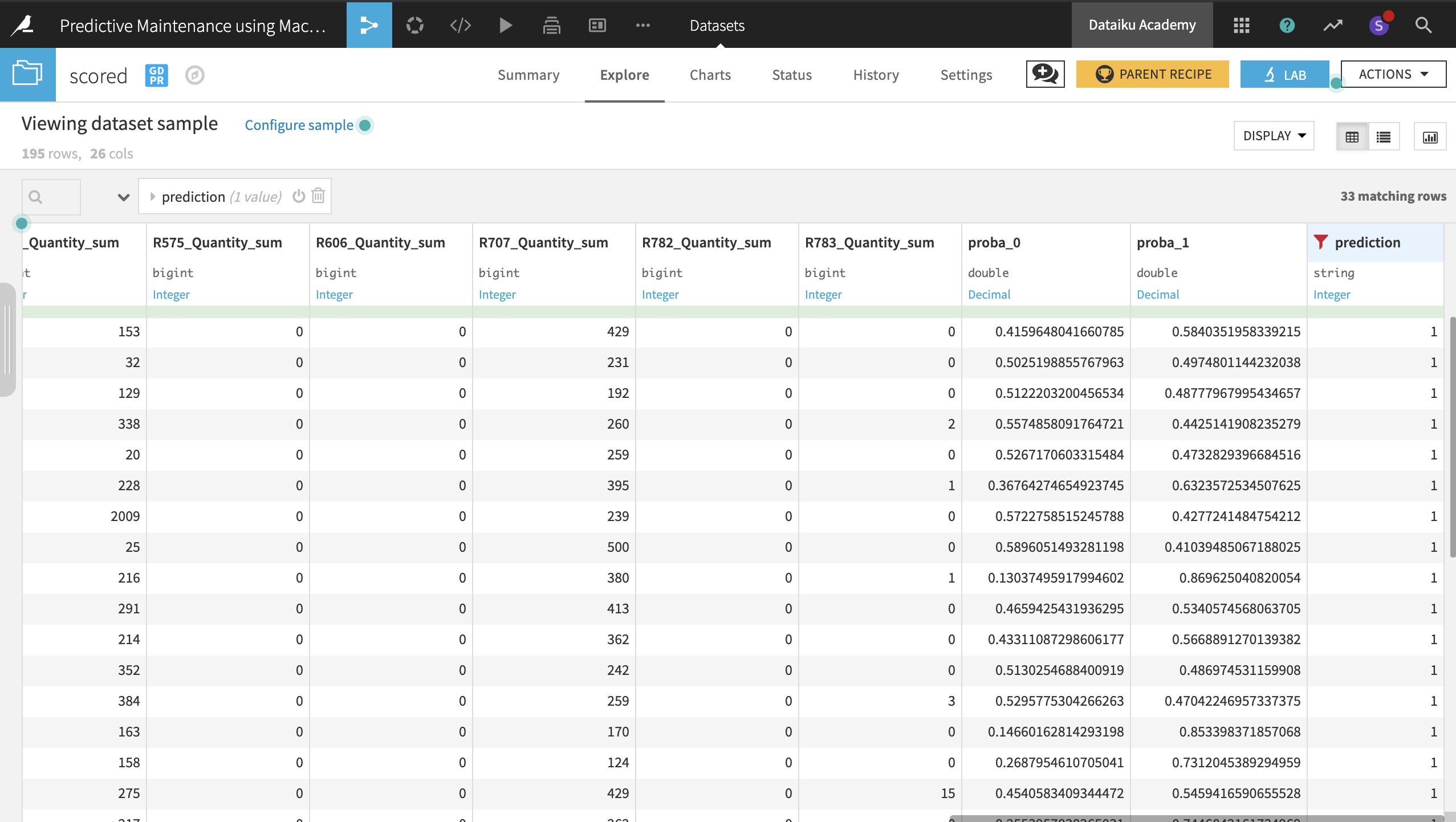
The resulting dataset now contains three new columns:
proba_1: probability of failure
proba_0: probability of non-failure (1 - proba_1)
prediction: model prediction of failure or not (based on probability threshold)