Preparing the Maintenance Dataset¶
The maintenance dataset documents activity that has occurred with respect to a given Asset, organized by Part (what was repaired) and Time (when it was repaired). A Reason variable codifies the nature of the problem.
As we did for the usage dataset, we want to organize the maintenance dataset to the level of unique vehicles. For the usage dataset, we achieved this with the Group recipe. Here, we’ll use the Pivot recipe.
While the current dataset has many observations for each vehicle, we need the output dataset to be “pivoted” at the level of each vehicle; that is, transformed from narrow to wide.
Note
Data transformation from narrow to wide is a common step in data preparation. Different statistical software packages and programming languages have their own terms to describe this transformation. Wide and narrow is one standard, but there are of course others.
As done for the usage dataset, infer storage types so that the variables Time and Quantity are no longer stored as strings.
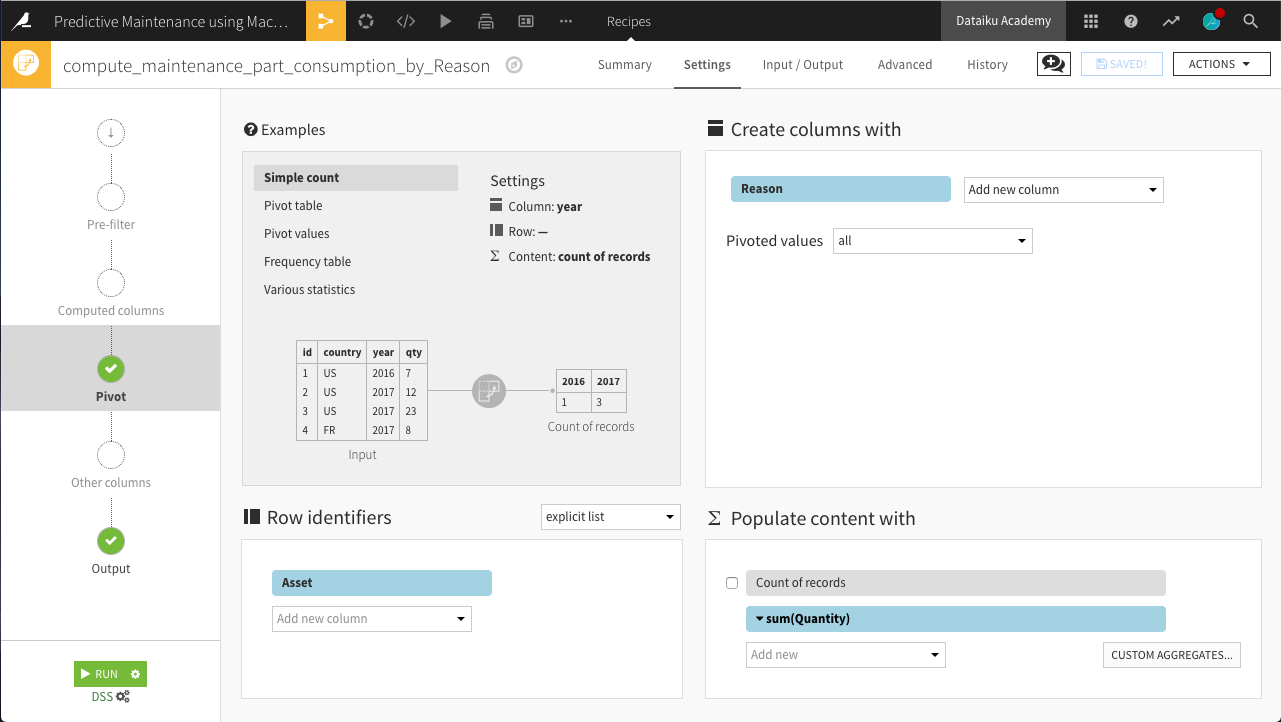
Next, use the Pivot recipe to restructure the dataset at the level of each vehicle. In detail:
With maintenance chosen as the input dataset, choose to Pivot By Reason.
Keep the default output dataset name
maintenance_by_Reasonand Create Recipe.At the Pivot step, select Asset as the row identifier.
Reason should already be selected under Create columns with. Although it should make no difference in this case, change Pivoted values to all so that all values of Reason are pivoted into columns.
Populate content with the sum of Quantity. Deselect Count of records.
Run the recipe.
Note
More detailed information on the Pivot recipe can be found in the reference documentation or the Visual Recipes Overview.