Score New Data¶
Once you have a model deployed to the Flow, you can use it to generate predictions on new, unseen data. This new data, however, first needs to be prepared in a certain way because the deployed model expects a dataset with the exact same set of features as the training data.
Copy Recipes¶
Although there are more sophisticated ways of preparing a dataset for scoring (such as using the Stack and Split recipes), let’s keep things simple and send the new data through the same pipeline by copying recipes.
Note
You can copy recipes from the Flow for use in the same project or another one on the instance. You can also copy individual steps from a Prepare recipe for use elsewhere.
From the Flow, select both the Join and Prepare recipes. (On a Mac, hold Shift to select multiple objects).
From the Actions sidebar, choose Copy.
From the Flow View menu, choose Copy To.
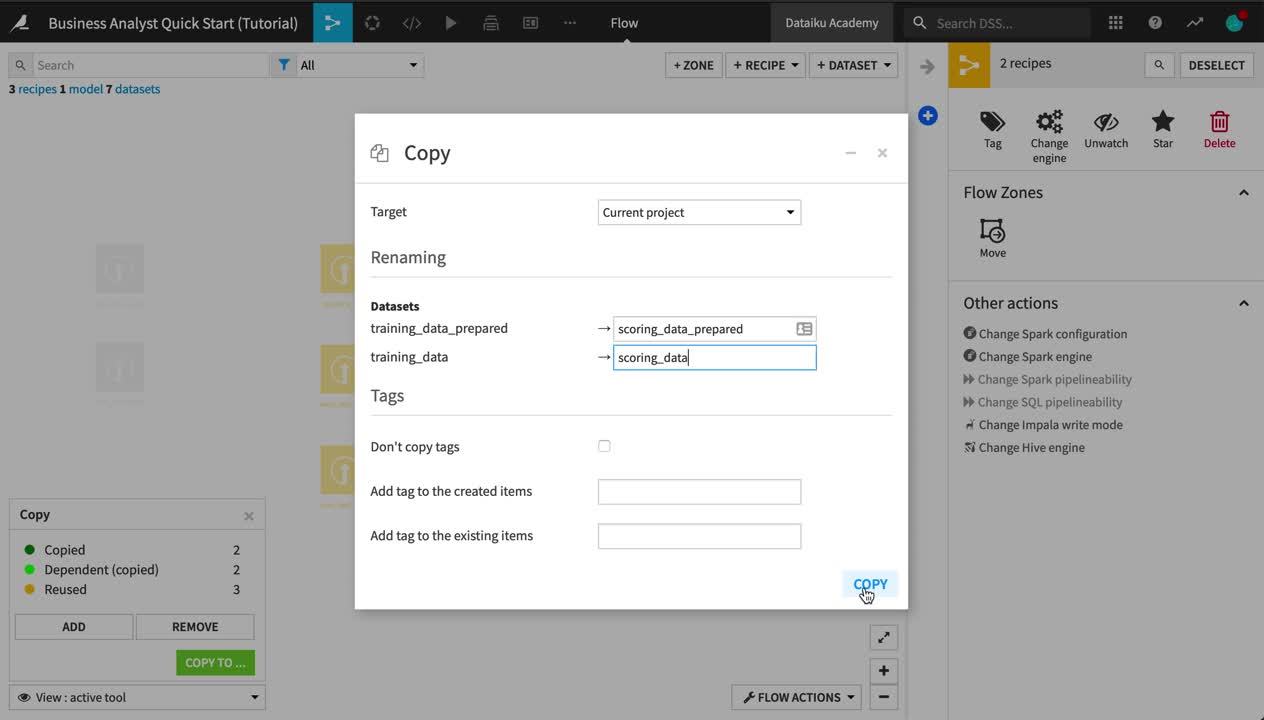
Rename training_data_prepared_1 as
scoring_data_prepared.Rename training_data_1 as
scoring_data.Click Copy.
The recipes have been copied to the Flow, but the inputs need to change.
Open the copied Join recipe (compute_training_data_1).
Replace the input datasets:
Click on web_last_year, and choose web_this_year as the replacement.
Click on crm_last_year, and choose crm_this_year as the replacement.
Instead of running the recipe right away, click Save, and update the schema.
Return to the Flow to see the pipeline for the scoring data.
Warning
When designing a Flow under normal circumstances, a better practice would be to build the dataset after copying the Join recipe by itself. If you open the copied Prepare recipe, you’ll notice errors due to the schema changes. This is done only to introduce the concept below.
Build a Pipeline¶
Now you have a pipeline created for the scoring data, but the datasets themselves are empty (note how they are transparent with a blue dotted outline). Let’s instruct Dataiku DSS to build the prepared scoring data, along with any upstream datasets needed to make that happen.
Note
When you make changes to recipes within a Flow, or if there is new data arriving in your source datasets, you will want to rebuild datasets to reflect these changes. There are multiple options for propagating these changes.
A non-recursive option builds only the selected dataset using its parent recipe.
Various recursive options, such as smart reconstruction, check upstream for changes in the Flow and rebuild only those datasets necessary to produce the requested output.
From the Flow, open the outlined scoring_data_prepared dataset.
Dataiku DSS tells you that it is empty. Click Build.
Choose Recursive instead of the default Non-recursive option.
Leave “Smart reconstruction” as the Build mode, but choose Preview instead of “Build Dataset”, just for the purpose of demonstration.
Clicking Preview computes job dependencies and shows the Jobs menu.
Note
Actions in Dataiku DSS, such as running a recipe or training a model, generate a job. You can view ongoing or recent jobs in the Jobs menu from the top menu bar or using the shortcut G+J.
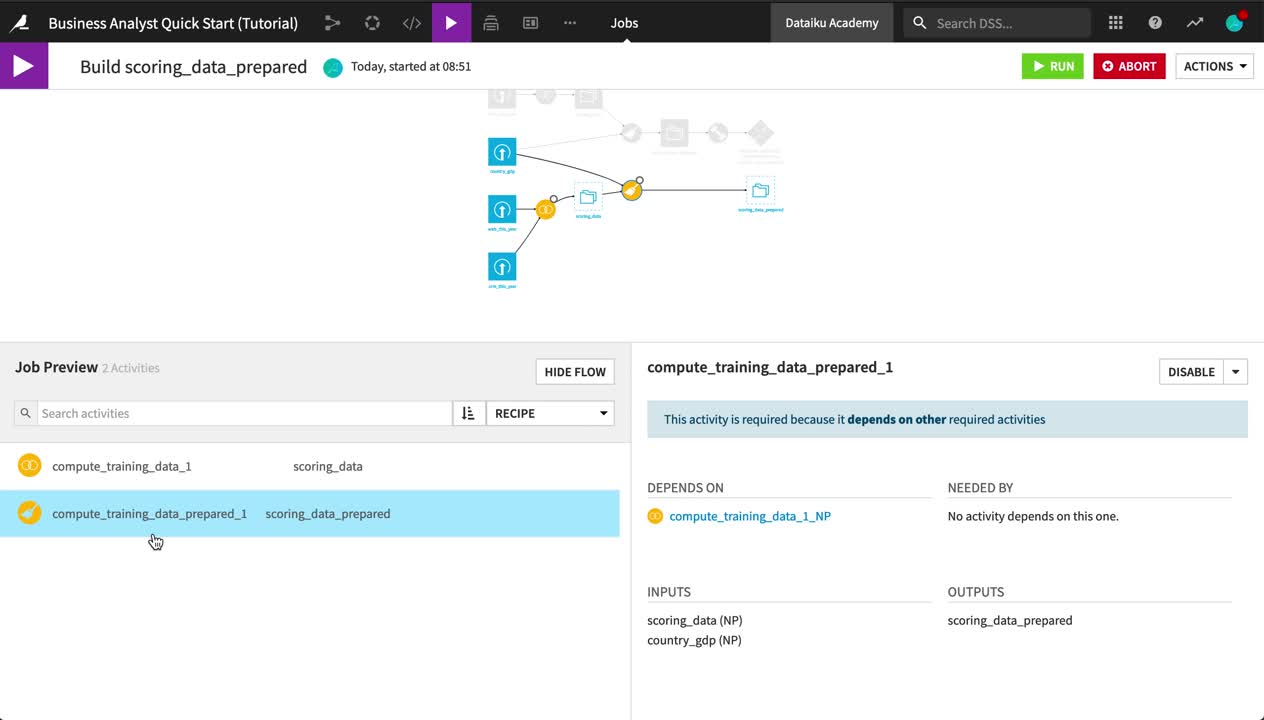
Examine the two activities in this job:
One runs the copied Join recipe.
Another runs the copied Prepare recipe.
At the top right, click Run to initiate the job that will first build scoring_data and then scoring_data_prepared.
When the job has finished, view the scoring_data_prepared dataset.
Return to the Flow to see the previously outlined pipeline now fully built.
Tip
The system of dependencies between objects in the Flow, teamed with these various build strategies, makes it possible to automate the process of rebuilding datasets and retraining models using scenarios.
Apply a Score Recipe¶
You now have a dataset with the exact same set of features as the training data. The only difference is that, in the data ready to be scored, the values for the churn column, which is the target variable, are entirely missing, as we do not know which new customers will churn.
Let’s use the model to generate predictions of whether the new customers will churn.
From the Flow, select the scoring_data_prepared dataset.
From the sidebar, click on the schema button. Observe how it is the same schema as the training_data_prepared dataset.
Open the scoring_data_prepared dataset. Observe how the churn column is empty as expected.
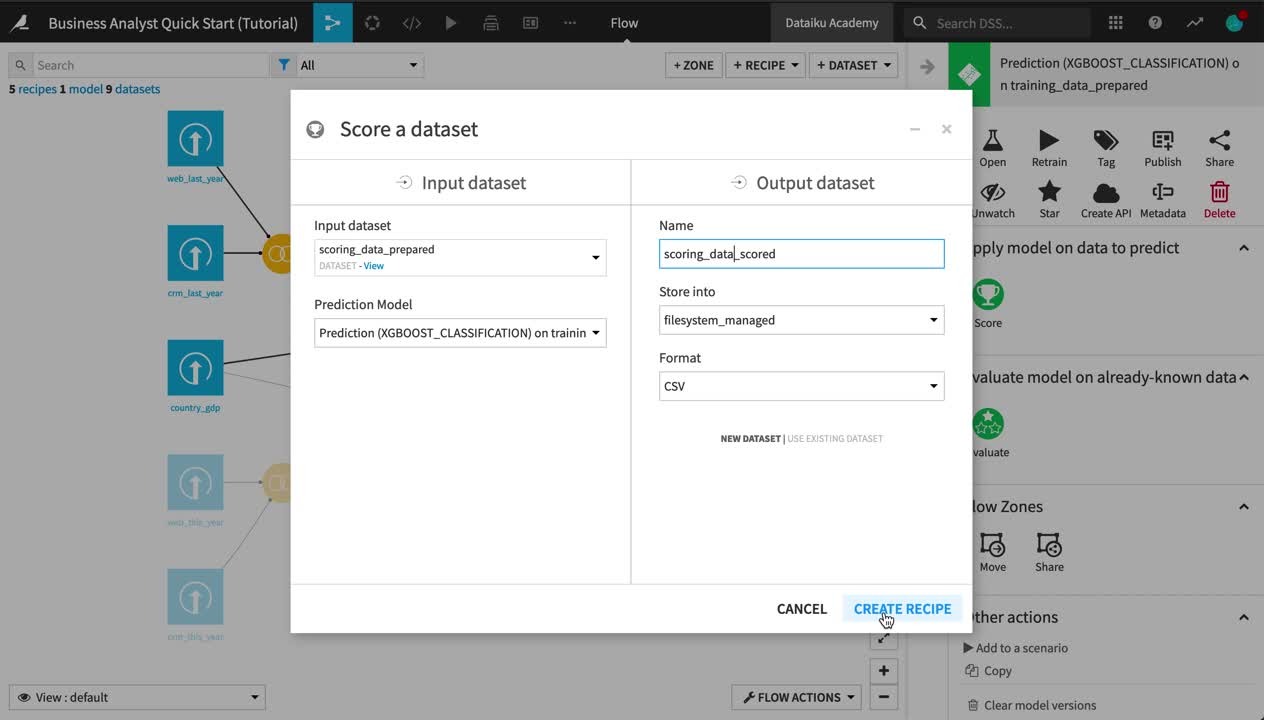
From the Flow, select the deployed prediction model, and add a Score recipe from the Actions sidebar.
Choose scoring_data_prepared as the input dataset.
Name the output scoring_data_scored.
Click Create Recipe.
Leave the default recipe settings, click Run, and then return to the Flow.
Inspect the Scored Data¶
Let’s take a closer look at the scored data.
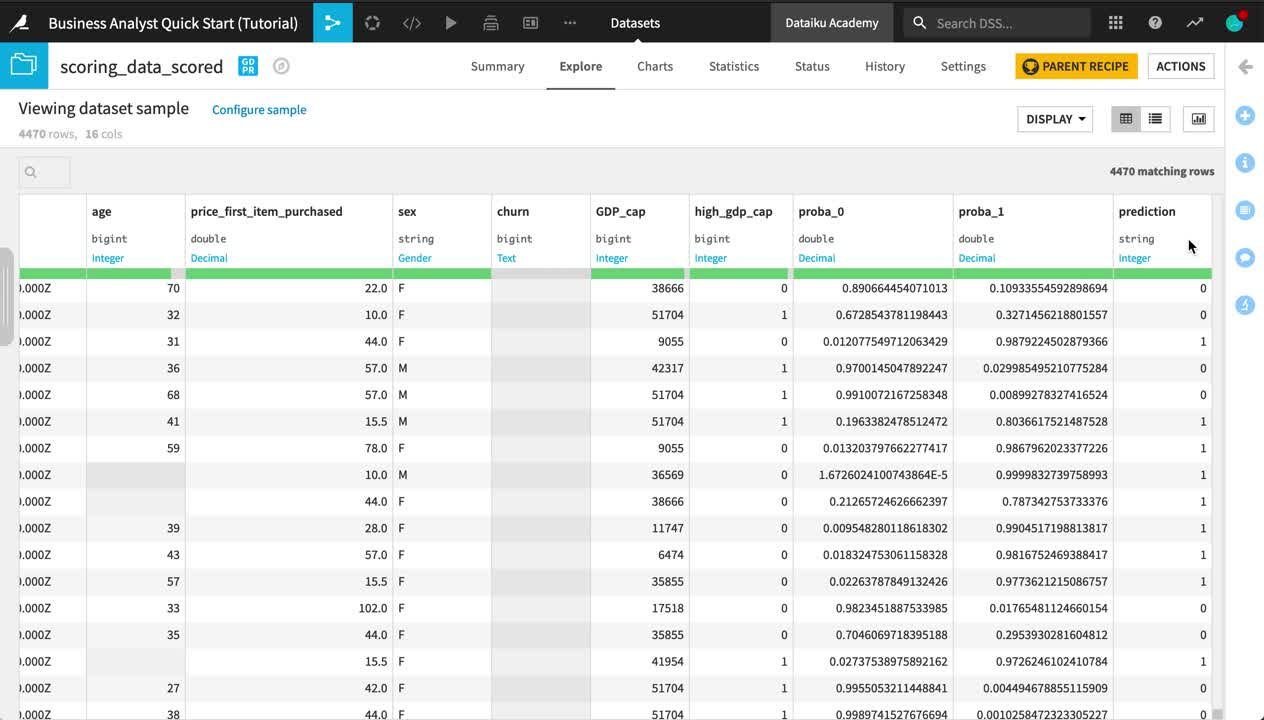
Open the scoring_data_scored dataset, and observe the three new columns appended to the end:
proba_0 is the probability a customer remains.
proba_1 is the probability a customer churns.
prediction is the model’s prediction of whether the customer will churn.
Use the Analyze tool on the prediction column to see what percentage of new customers the model expects to churn.
Hint
How does the predicted churn rate on the new data compare to the churn rate observed in the training data?