Hands-On: Resampling Time Series Data¶
In the previous hands-on exercise, we inspected a time series dataset and explored it by building a few charts. During our inspection, we noticed that the timestamps occurred at irregular intervals.
Let’s fix this irregularity with the Resampling recipe of the Time Series Preparation plugin.
Equally Space Timestamps¶
Here is our starting Flow.
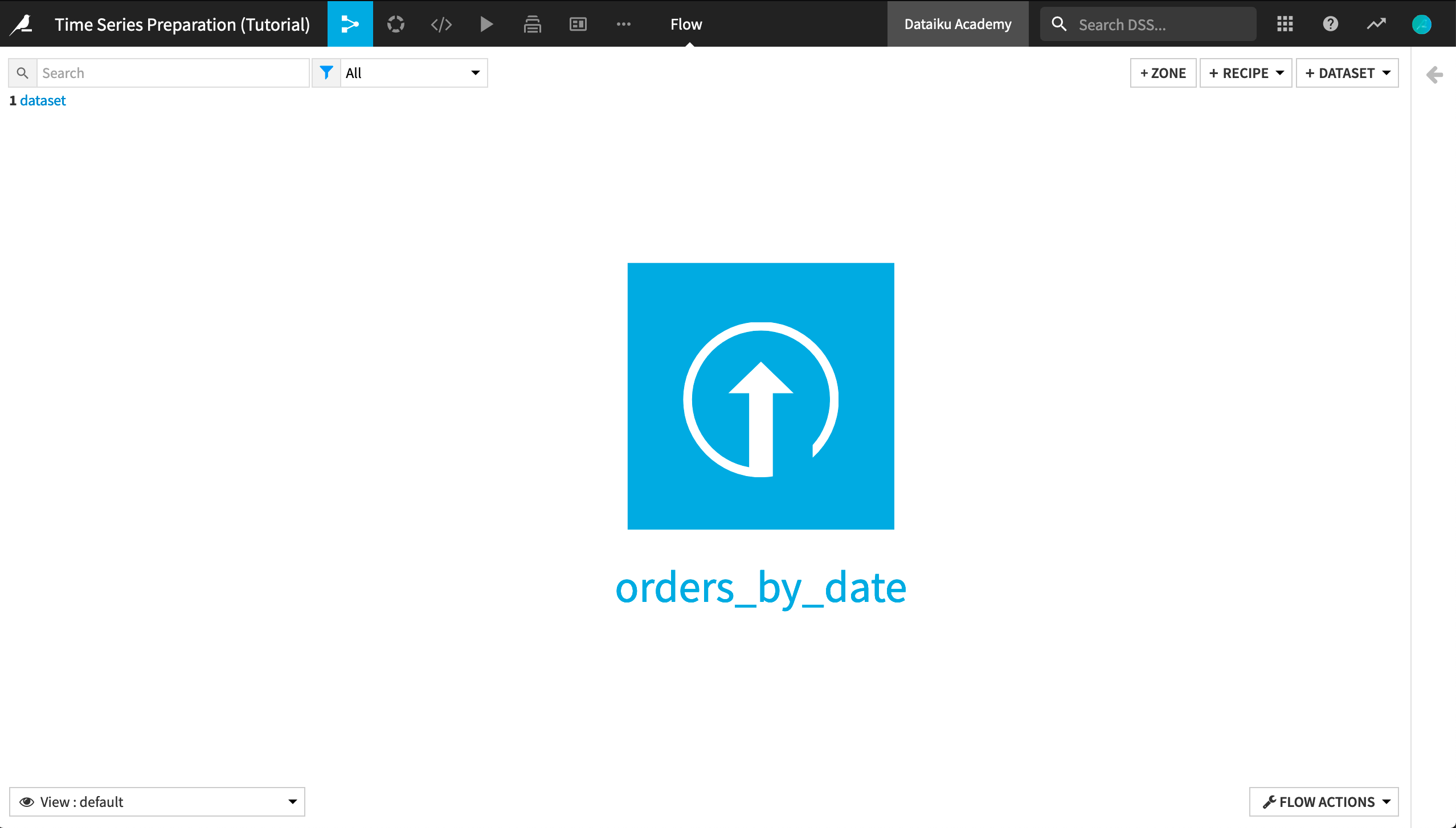
Observe that the orders_by_date dataset contains daily records. However, these records appear in irregular time intervals. To begin, we will use the Resampling recipe to transform the dataset into equispaced data.
With the orders_by_date dataset open or selected, click the Time Series Preparation plugin from the Actions sidebar.
Select the Time series resampling recipe from the window that appears.
Keep the default “Input time series” as orders_by_date and name the output dataset
orders_resampled.Then create the output dataset.
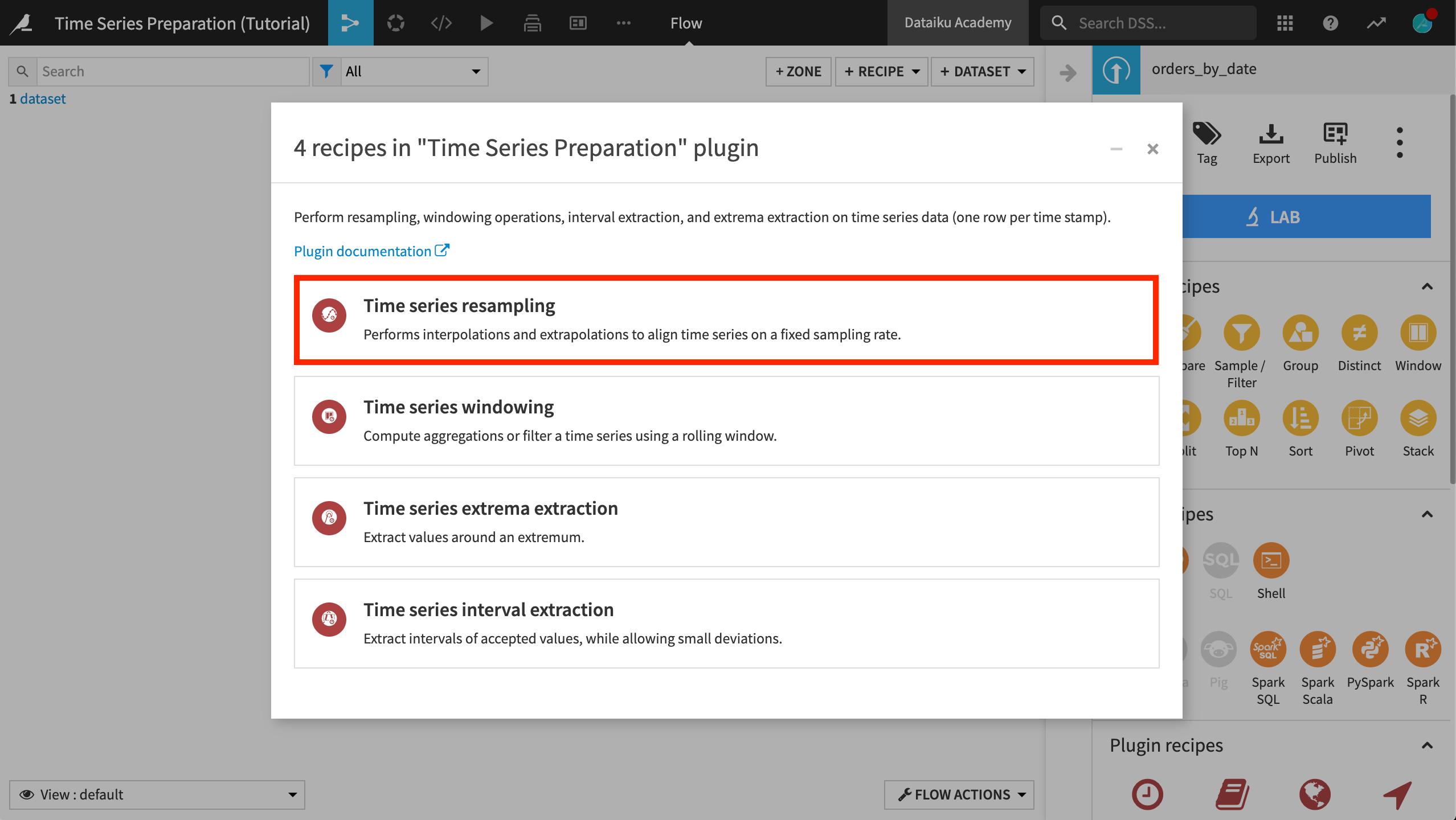
In the Resampling recipe dialog,
Set the value of the “Time column” to order_date. A parsed date column (such as order_date), is required.
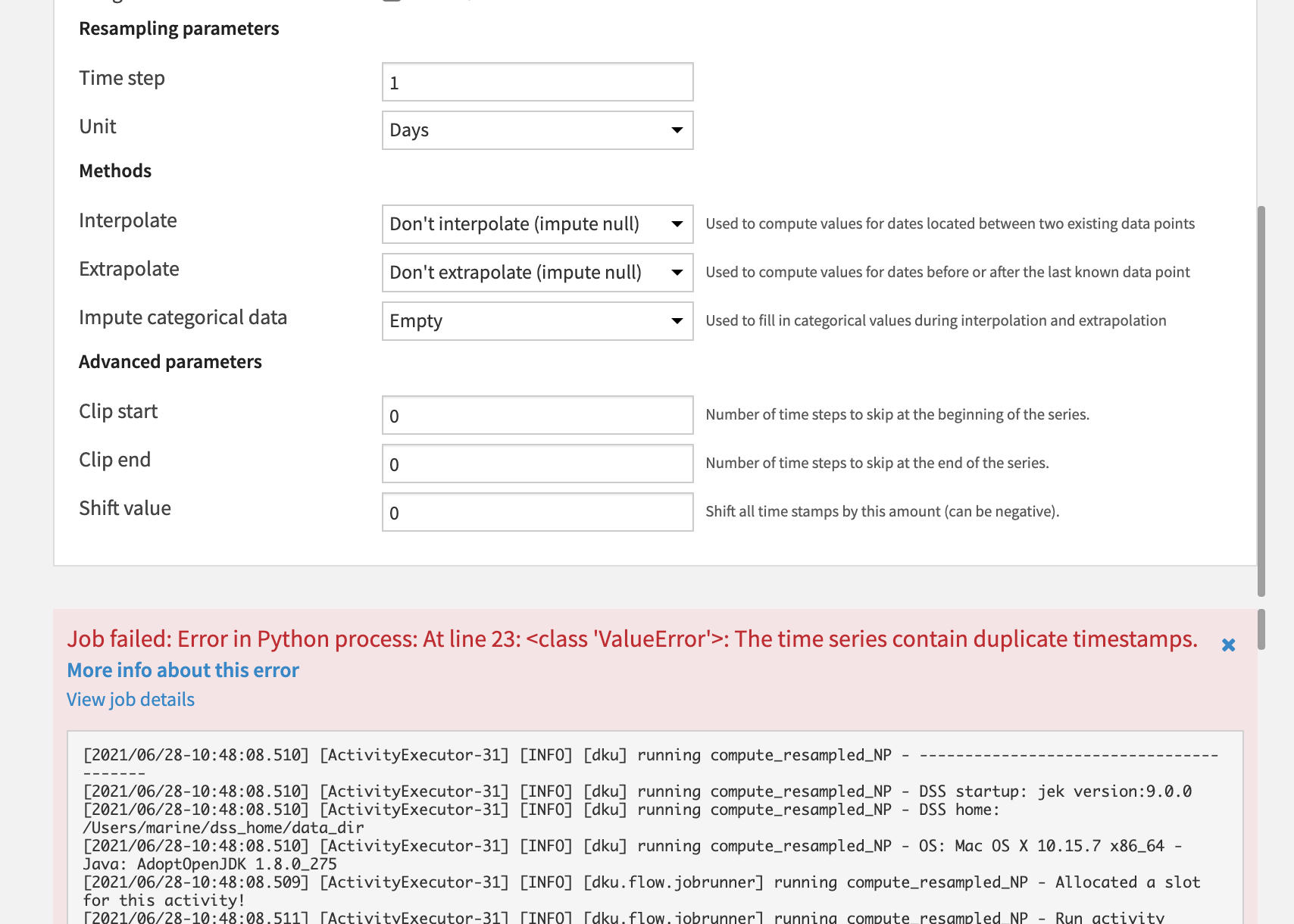
For the Resampling Parameters, specify “Time step”:
1and “Unit”: Days.For now, set the Interpolation method to Don’t interpolate (impute null) and the Extrapolation method to Don’t extrapolate (impute null).
Keep the default values of
0in the “Advanced parameters” section.Although our data is in long format, leave the “Long format” box unchecked and run the recipe to observe the results.
Dataiku DSS throws an error complaining about duplicate timestamps. With multiple time series in the dataset, we have many rows with the same timestamp and different values for amount_spent or tshirt_quantity because they belong to different tshirt_category groups.
Returning to the same recipe dialog, let’s now check the “Long format” box, and specify tshirt_category as the “Time series identifiers” parameter. Run the recipe again and open the output dataset.
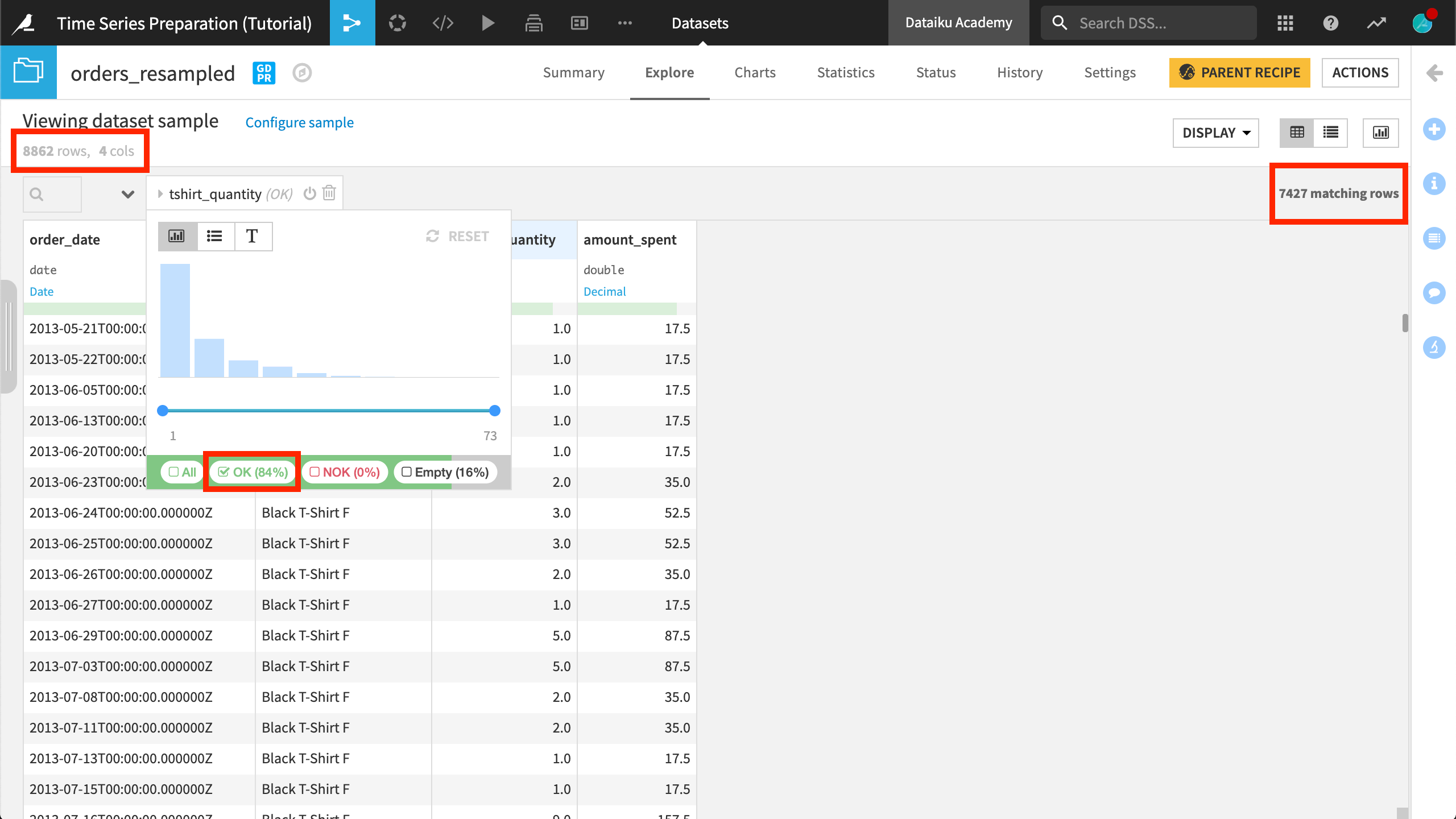
Let’s observe the output. Notice that the order_date column of the orders_resampled dataset now consists of equispaced daily samples. No dates are missing from the time series.
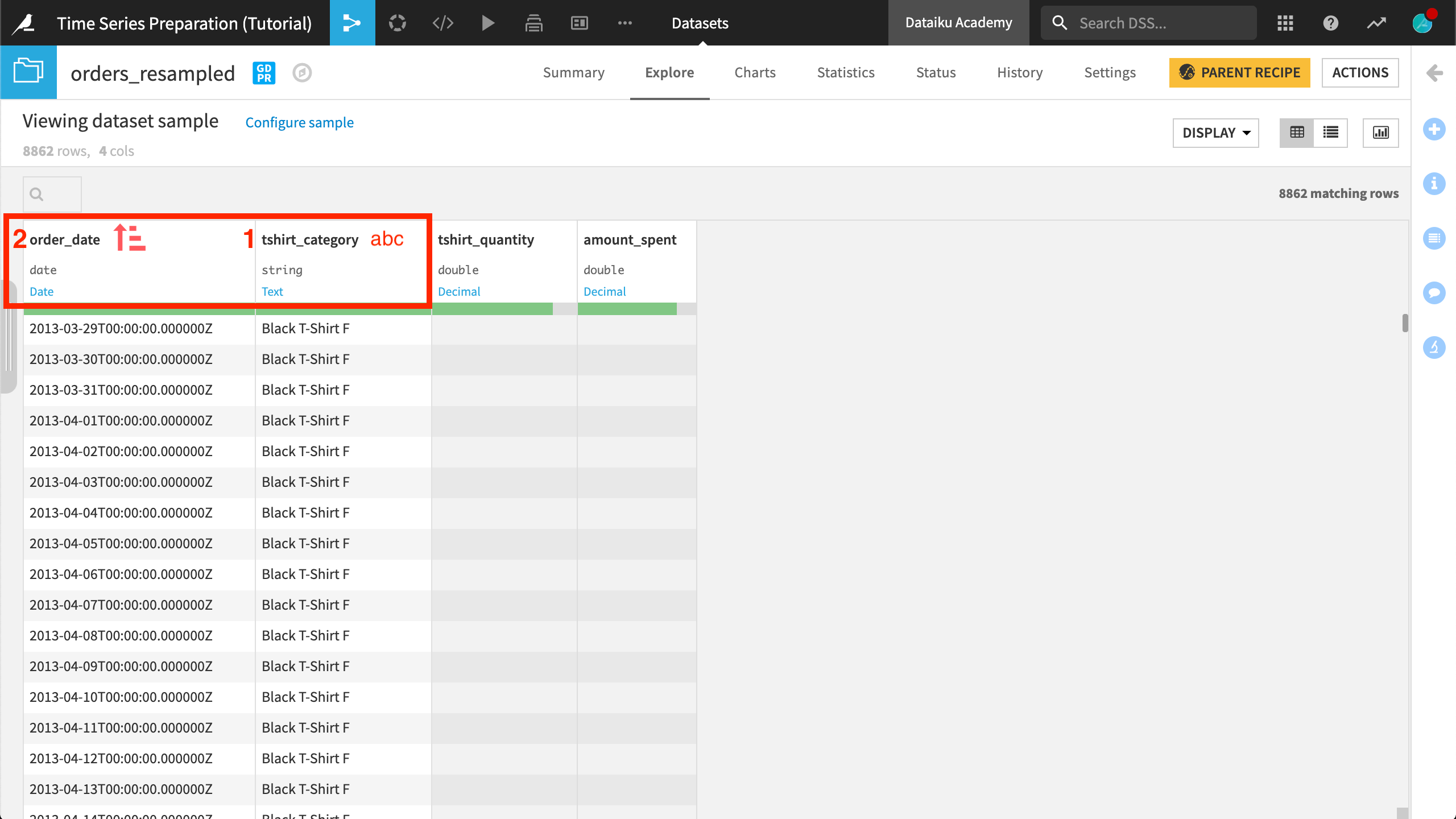
The arrangement or order of rows has also changed. The input dataset was arranged by increasing values of the order_date column (chronological order). After resampling, the output dataset is first sorted alphabetically by tshirt_category, and then chronologically by the order_date column.
Because we chose not to interpolate or extrapolate values for the missing timestamps, the recipe returns their rows with empty values for the tshirt_quantity and amount_spent columns.
We can confirm this fact by filtering the data on either the tshirt_quantity or amount_spent column for “OK” values and observing the reduction in the number of rows returned.
Interpolate Values¶
We now have equispaced timestamps, but what values should can we infer (or interpolate) for the new timestamps? The answer depends on the type of data at hand and the assumptions we’re willing to make about it.
For example, we may choose a very different interpolation method for a continuous quantity, such as temperature, than a non-continuous quantity like daily sales figures.
Let’s assume that an empty value of daily sales figures means no sales of that category were made that day.
Return to the parent recipe of orders_resampled.
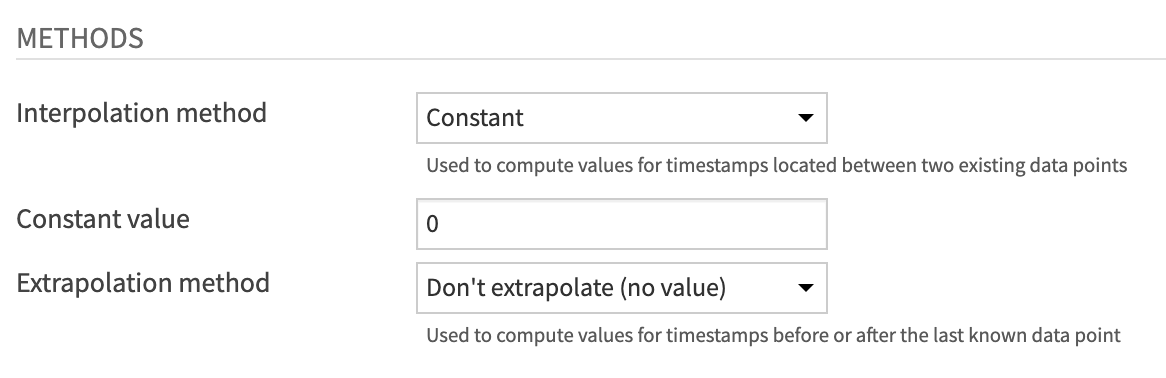
Change the Interpolation method from “Don’t interpolate (impute null)” to Constant. Leave the default constant value as
0.Leave the Extrapolation method as “Don’t extrapolate (impute null)” and run the recipe.
When we inspect orders_resampled again, values belonging to the “Black T-Shirt F” time series before its first true data point remain empty.
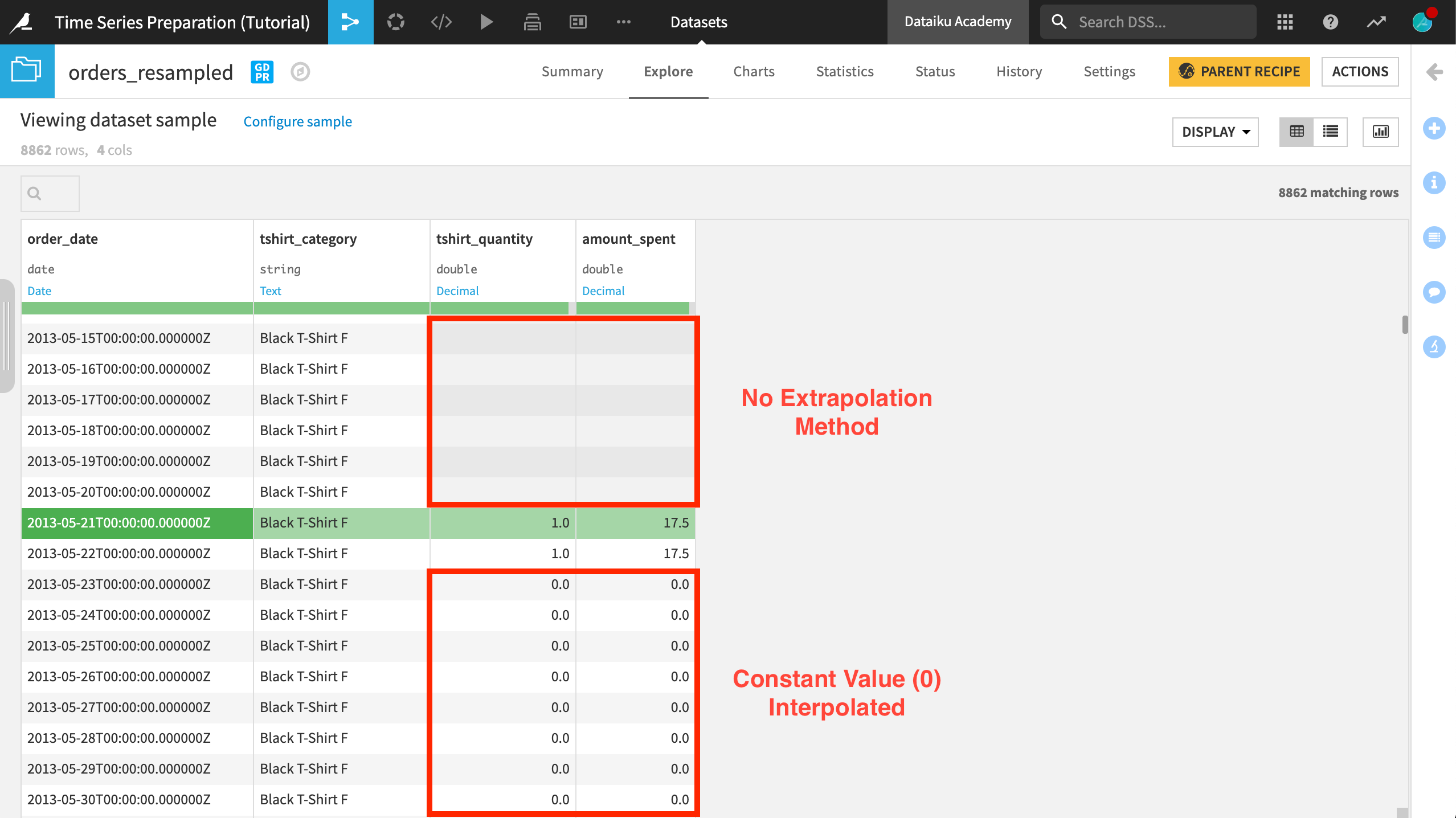
On the other hand, all values after the first true data point in their respective time series are now filled with values of 0.
For the “Black T-Shirt F” category for example, the first observation in the time series is “2013-05-21”, whereas the first observation of any time series in the dataset is “2013-03-29”.
Values before “2013-05-21” remain empty because no extrapolation method was chosen. Values after “2013-05-21” are either are an original true value or have been interpolated with a constant value of 0.
Note
Values were interpolated for both tshirt_quantity and amount_spent. We never needed to specify those columns in the recipe dialog. Interpolation (or extrapolation as we’ll see) is applied to all numerical columns in the dataset.
Tip
On your own, explore using other interpolation strategies to observe differences in the results.
Extrapolate Values¶
We still have empty values at the beginning of the dataset because we have not chosen an extrapolation method.
For example, the first order for any time series in the dataset was “2013-03-29”, but the first order for the “Black T-Shirt F” time series was not until “2013-05-21”.
The Extrapolation method allows us to fill in values at the beginning of any time series in the dataset to the earliest timestamp in the data. Conversely, the Extrapolation method allows us to fill in values at the end of time series, to extend them to the latest timestamp in the data.
Return to the parent recipe of orders_resampled.
Change the Extrapolation method from “Don’t extrapolate (impute null)” to Same as interpolation.
Run the recipe.
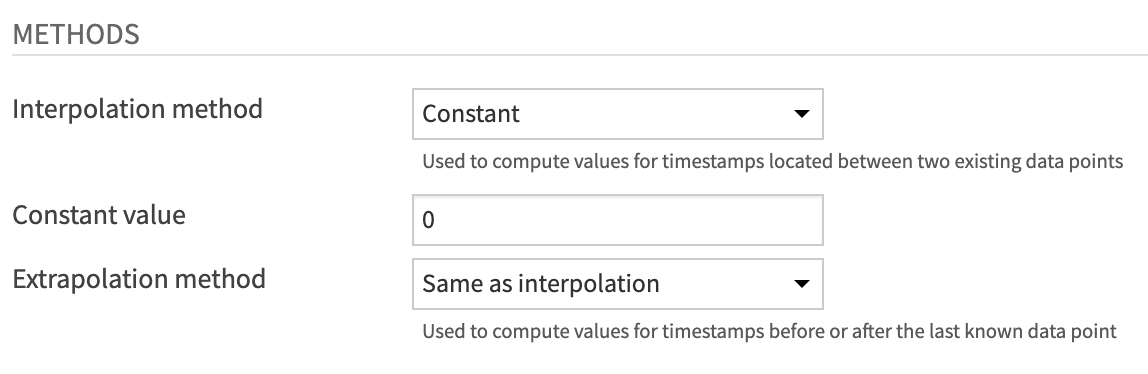
Observe the output dataset once more and notice that all empty values have been replaced with zeroes.
Advanced parameters¶
In some cases, we may want to edit the time series themselves. For example in a manufacturing setting, perhaps our instruments take a few seconds before they record proper readings.
In this case, we have very few sales in the first month. Perhaps we want to clip the series.
Increase the “Clip start” parameter in the Edit Series section of the recipe dialog from
0to31.Run the recipe.
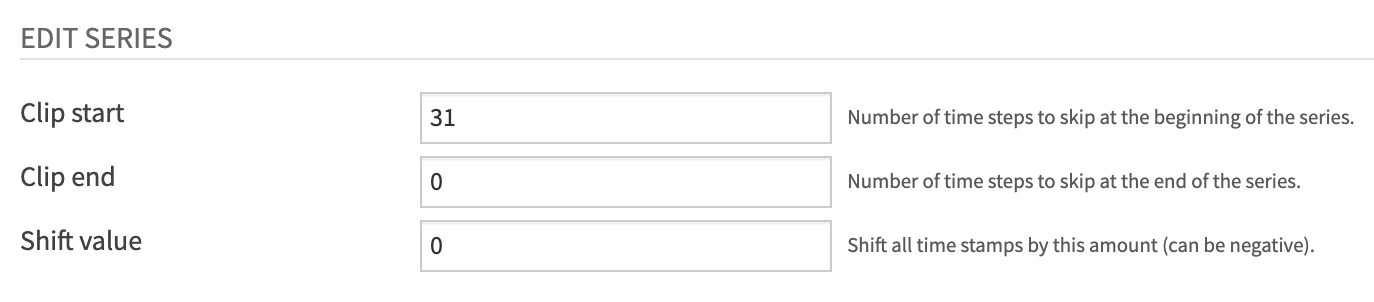
Instead of the first timestamp in the dataset being “2013-03-29”, it is now “2013-04-29”, 31 days later than before.
For use in later tutorials in this series, return to the parent recipe again, adjust the “Clip start” parameter back to 0, and run the recipe once more.
What’s next?¶
Congratulations! You now have an understanding of how to use the Resampling recipe to equally-space, interpolate, extrapolate, and clip time series data in Dataiku DSS.
Now that the time series are equispaced, and a constant value of 0 has been used for interpolating and extrapolating missing values, we can proceed to safely apply the other recipes in the plugin.
First up will be the Interval Extraction recipe!