Enrich the Station Dataset with Demographics and Trip Data¶
We now have three sources of data needing to be joined into a single dataset:
Bike station-level data about the stations
Bike station-level data aggregated from individual trips
Block group-level demographic data.
Get US Census Block Plugin¶
We have geographic coordinates of bike stations, but we do not know in which block groups they are located. Accordingly, in order to enrich the bike station data with the demographic (block group) data, we need to map the geographic coordinates (lat, lon) of each bike station to the associated block group ID from the US census.
We can do this mapping with a Plugin recipe.
From the Flow, select + Recipe > Get US census block > From Dataset - get US census block_id from lat lon.
Choose bikeStations_prepared as the input dataset and name the output dataset
bikeStations_prepared_blocks. Create the recipe.In the recipe, select lat and long as the latitude and longitude columns.
Under Options, choose “Use an id column” as the param_strategy. Select station_name as the “Input Column ID:”. Adding this will retain station_name in the output dataset, making it easier to identify than geographic coordinates.
Run the recipe.
Note
As the plugin utilizes a free API, it may take several minutes (+10) to complete. To avoid rebuilding any dataset by mistake, you can write-protect it. With a dataset open, navigate to Settings > Advanced. Under Rebuild behavior, select Write-protected to instruct the dataset to never be rebuilt, even when explicitly asked.
Due to recent changes in the API, columns like county and state names are no longer returned. However, because we still have their numeric codes, we can easily fix this with a quick Prepare recipe.
Create a Prepare recipe with bikeStations_prepared_blocks as the input dataset. Name the output bikeStations_prepared_blocks_complete.
Remove the four empty columns: block_id, county_name, state_code, and state_name.
Use the Find and replace processor on the state_id column to create a new column, state_name according to the table below.
Current
Replacement
11
District of Columbia
24
Maryland
51
Virginia
Use the same processor on the county_id column to create a new column, county_name according to the table below.
Current
Replacement
001
District of Columbia
013
Arlington
031
Montgomery
059
Fairfax
510
Alexandria
033
Caroline
610
Falls Church
Edit the schema as necessary so that columns are stored appropriately. block_group should be a string. lat and lon should be double.
Note
The red highlighting in county_id are because Dataiku has predicted a meaning of US State. In this case, it does not apply. When this happens, feel free to change the meaning to Text to remove the warning.
Run the recipe, updating the schema to nine columns. Note that in the output dataset, we now know, for each unique bike station, the corresponding geographic coordinates, block group, county, and state.
Join all data¶
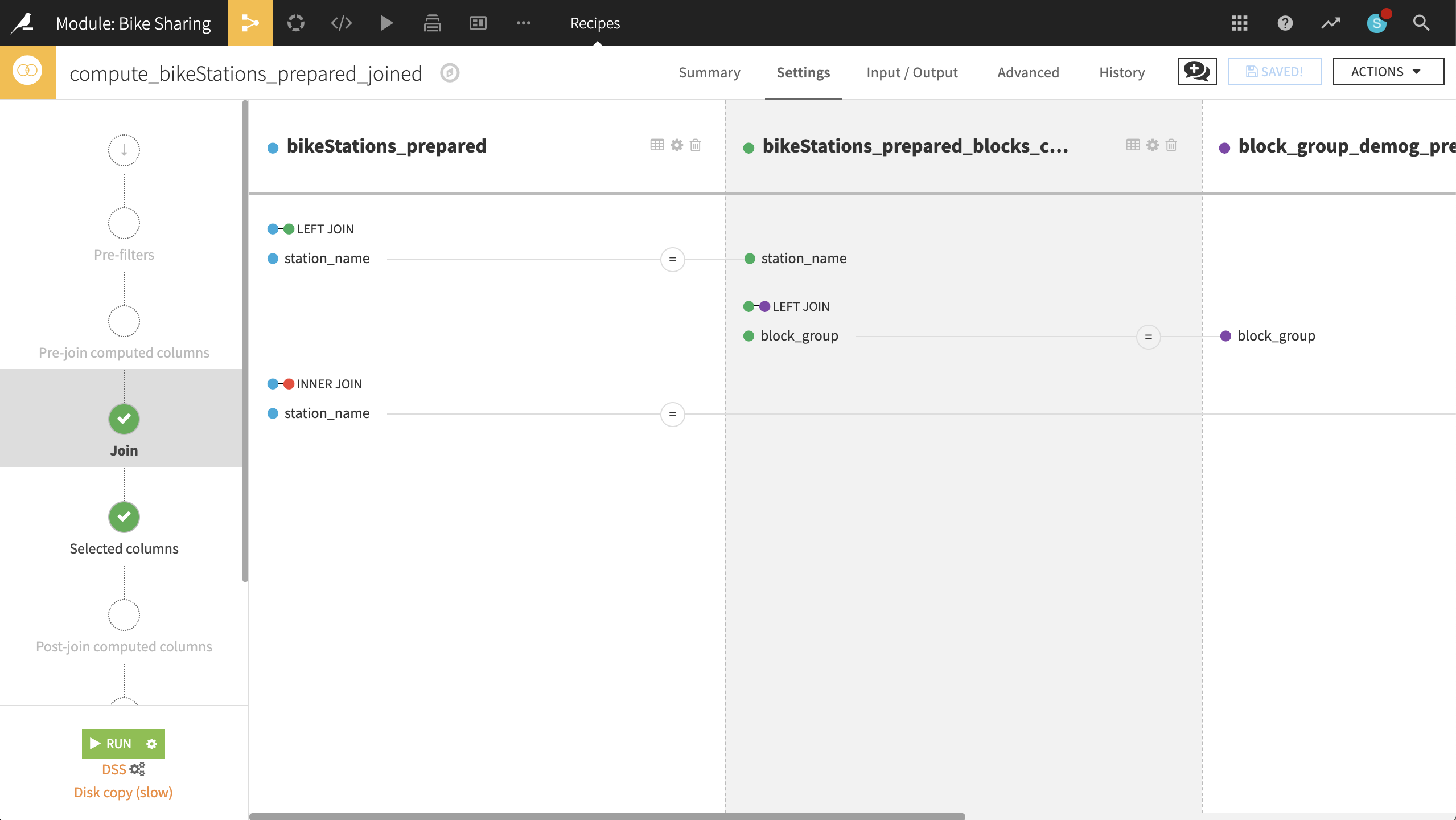
Returning to the bikeStations_prepared dataset, create a Join recipe and select bikeStations_prepared_blocks_complete as the dataset to join with. Accept the default output bikeStations_prepared_joined. In the recipe settings:
In the Join step:
station_name is unique in both datasets, and so should be the only join condition necessary. Keep the left-join.
This step just adds back the missing columns nbBikes and geopoint.
Add block_group_demog_prepared as a third input dataset, left-joined to bikeStations_prepared_blocks_complete as the existing input dataset.
If stored as strings in both, Dataiku should automatically find block_group as the join key. If it does not, please make sure that block_group is set as the join key for both datasets.
Most importantly, this join adds the number of people in a block group to the larger dataset.
Add bike_data_pivoted as a fourth input dataset, joined to bikeStations_prepared as the existing input dataset.
Set the type of join to an “Inner Join”, and the join key to station_name and Start station.
This enriches the bike station data with the aggregated trip data.
In the Selected columns step, we can drop some columns we won’t need.
From bikeStations_prepared, keep only nbBikes, station_name and geopoint.
From bikeStations_prepared_blocks_complete, keep only county_name and state_name.
From block_group_demog_prepared, keep only block_name and nbPeople.
From bike_data_pivoted, drop Start station.
Run the recipe, updating the schema to 35 columns.
Our station dataset is now enriched with demographic and trip information! For every station, we have the number of bikes, the associated census block group and the number of people living in it, and data on the duration and count of bike trips by casual and member riders each day of the week.