
How-to | Extract unstructured content into a dataset#
Learn how to extract content from documents using the Extract content recipe in Dataiku.
In the Flow, select a managed folder that contains documents of different formats (.pdf, .docx, .pptx, .txt, .md, .html, .png or .jpg).
In the right panel, open the Actions (
 ) tab, and click Extract content under the Visual Recipes section.
) tab, and click Extract content under the Visual Recipes section.In the New extract content recipe window, name the output dataset and click Create Recipe.
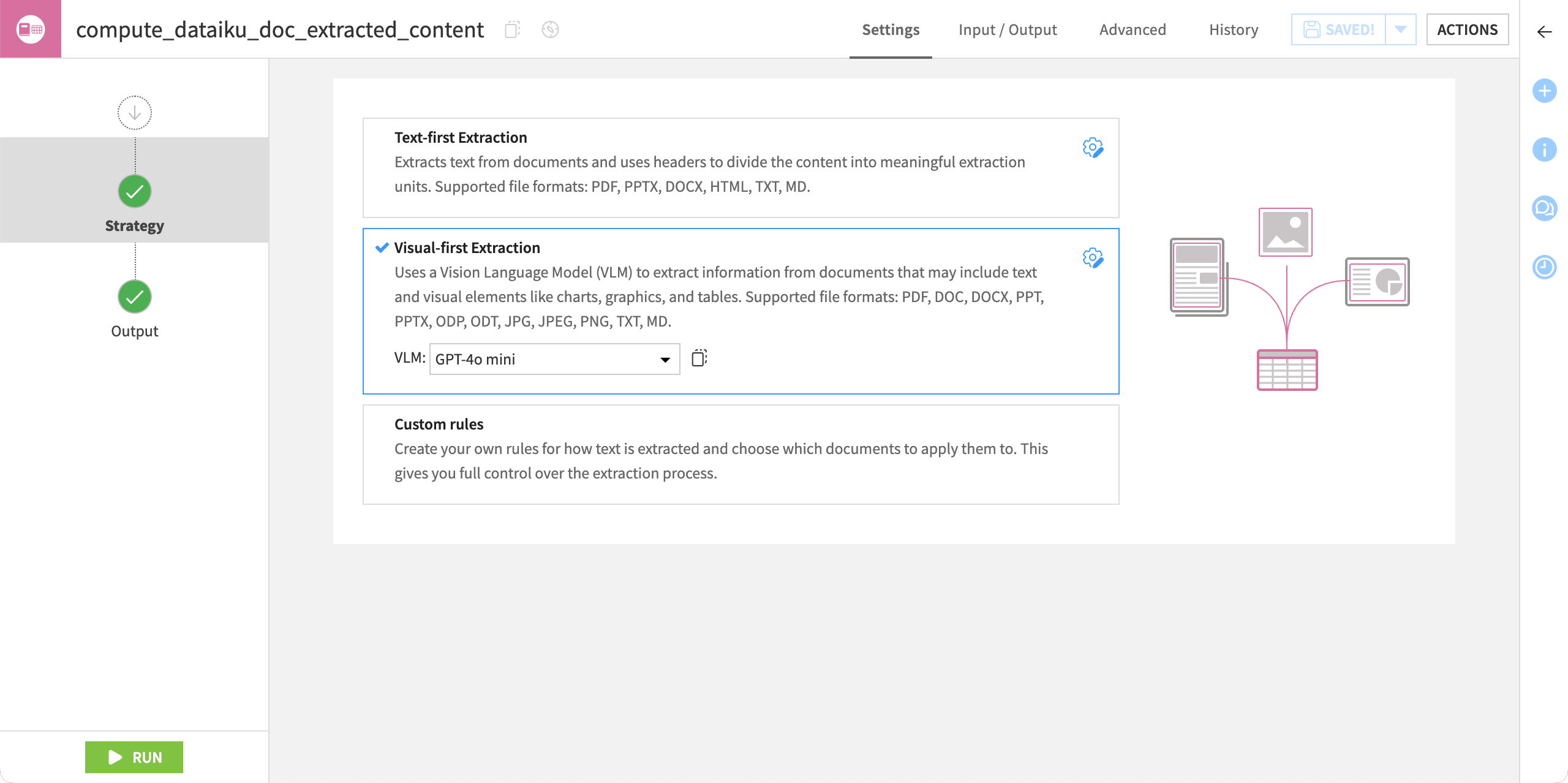
In the Strategy tab, select an extraction strategy (text-only, visual-first, or custom).
Click Run to execute the recipe.
Once the recipe has finished running, explore the output dataset. You will find the extracted content in different columns, such as source_file, extracted_content, content_id.
You can now use this dataset in the Flow for further transformations via visual recipes, to train machine learning models, or even leverage Generative AI features (such as classification or summarization or enriching an LLM using the Embed dataset or Embed documents recipes). This enables you to benefit from a clean end-to-end pipeline from raw documents to actionable insights.