Troubleshoot | Sync recipe from Snowflake to S3 takes many hours to complete#
What: A specific visual Sync recipe job in DSS is slower than expected. Our input dataset is a Snowflake dataset and our output is an S3 dataset with CSV formatting.
Who: Because this is impacting a single job, only one user is experiencing this performance issue, and only for this specific job.
When: We noticed that this job always takes about the same time to complete, so it consistently takes many hours to complete.
Where: This job is using the Spark engine, and it’s executing on our Spark cluster and not on the DSS server.
Troubleshooting steps#
We know this issue is consistent for this particular job. We also know the job is using the Spark engine and is executing on a Spark cluster, so it’s not an issue with the DSS server. Because this is a visual recipe and not a code recipe, we can rule out inefficient user code as the cause. In addition, because it’s a visual recipe, we’ll want to pay special attention to the engine this recipe uses.
Looking through the job logs, we see a line referencing “Computation won’t be distributed”:
[2021/10/06-11:10:19.408] [null-err-110] [INFO] [dku.utils] - [2021/10/06-15:10:19.400]
[main] [WARN] [dip.spark.fast-path]: Reading Snowflake dataset as a remote table. Computation won't be distributed
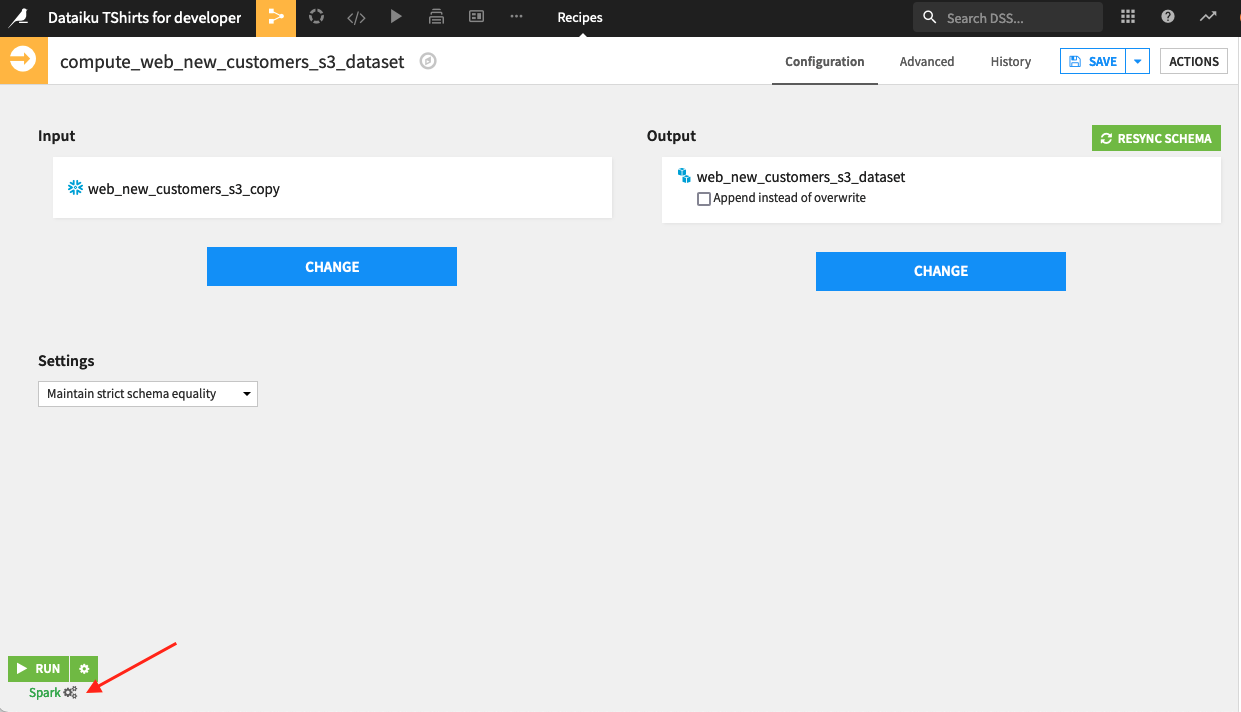
This indicates that there is something suboptimal about our recipe. Let’s start by taking a look at the available execution engines for the sync visual recipe . In this case, there is a specific fast-path engine for Snowflake-to-S3 syncing. We’re using the Spark engine instead.
Let’s review the requirements to use the fast-path engine from Snowflake-to-S3 and make sure we meet them. If we don’t already, it’s worth investigating if we can modify our setup so that we do meet all requirements and are able to leverage this engine.
For example, if the input dataset is an SQL query dataset, you won’t be able to use the optimal Snowflake-to-S3 engine. In this case, one option would be to alter your Flow so that the input dataset is an SQL table dataset and there is an additional SQL Query recipe that performs any necessary transformations on top of the initial dataset. This would then allow the final Sync recipe step to use the optimal Snowflake to S3 engine.
Once we reviewed everything and switched to the Snowflake-to-S3 engine, we see that the job time was significantly reduced!