
Solution | RFM Segmentation#
Overview#
Business case#
Personalization is a huge opportunity for retail and CPG businesses. To do so, a key step is to identify purchasing patterns among consumers to make the right decisions depending on each consumer purchase behavior. While you can use several techniques to do so, one tried-and-true method is RFM segmentation. It identifies purchasing patterns by focusing on the recency, the frequency, and the monetary value of the consumer purchases.
This plug and play Solution assesses all customers in a transactions dataset against those three criteria before segmenting customers across homogenous groups of users (segments): from the “hibernating” to the “champions,” every consumer belongs to one segment, which can evolve over time depending on the purchases made.
Brands are therefore able to push the right offer/product to the right consumer (segment). Doing so will foster loyalty and increase the consumer lifetime value for the brand, while consumers will benefit from a more personalized purchase journey.
Installation#
From the Design homepage of a Dataiku instance connected to the internet, click + Dataiku Solutions.
Search for and select RFM Segmentation.
If needed, change the folder into which the Solution will be installed, and click Install.
Follow the modal to either install the technical prerequisites below or request an admin to do it for you.
Note
Alternatively, download the Solution’s .zip project file, and import it to your Dataiku instance as a new project.
Technical requirements#
To use this Solution, you must meet the following requirements:
Have access to a Dataiku 13.2+* instance.
Dataiku’s Flow Charts plugin.
To benefit natively from the Solution, you should store your data in one of the following connections:
Snowflake
Google Cloud Platform: BigQuery + GCS (You need both if you want to leverage BigQuery).
PostgreSQL
Data requirements#
The Dataiku Flow was initially built using publicly available data. However, we intend for you to use this project with your own data, which you can upload using the Dataiku app. Having a transactional historical dataset is mandatory to run the project and each row of the dataset should be comprised of:
A product (Product ID)
A related transaction (Transaction ID)
Number of products purchased in a transaction (Product Quantity)
The product purchase price (Product Price)
Transaction date (Date)
Customer who made the purchase (Customer ID)
Workflow overview#
You can follow along with the sample project in the Dataiku gallery.
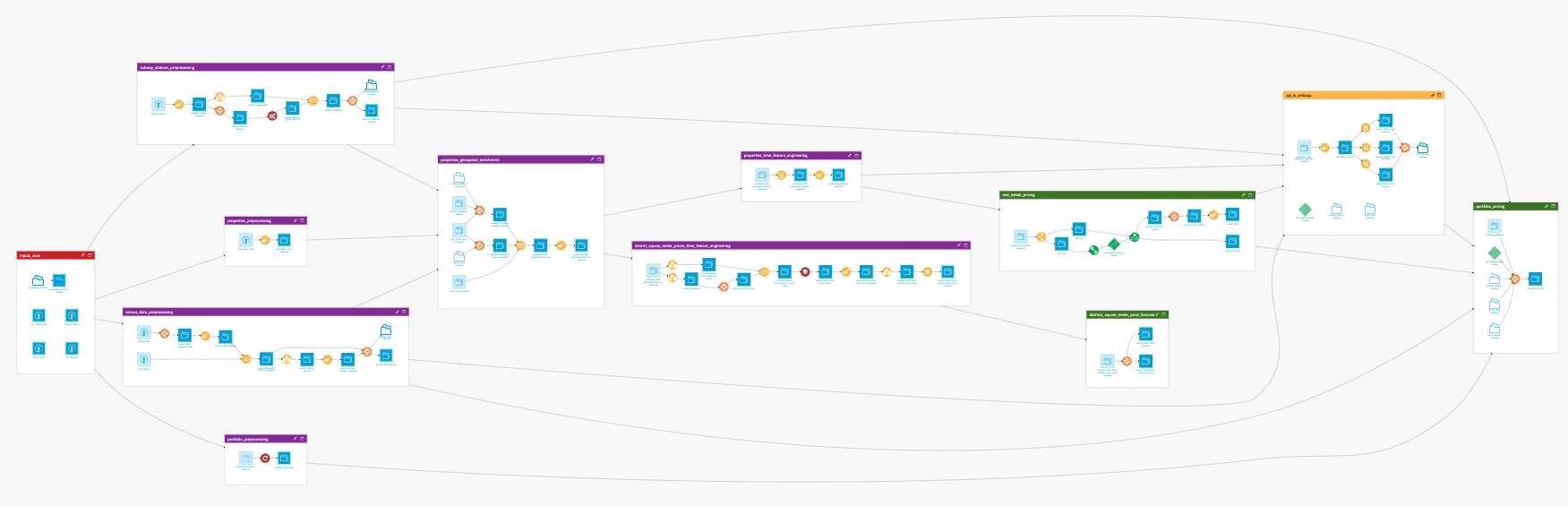
The project has the following high-level steps:
Connect your data as an input and select your analysis parameters via the Dataiku app.
Ingest and pre-process the data to be available for RFM computation and propagation.
Identify segments and apply segmentation to the customer base.
Propagate RFM scoring beyond the defined period of dates.
Interactively visualize the RFM segments as well as their evolution.
Walkthrough#
Note
In addition to reading this document, it’s recommended to read the wiki of the project before beginning to get a deeper technical understanding of how this Solution was created and more detailed explanations of Solution-specific vocabulary.
Plug and play with your own data and parameter choices#
To begin, you will need to configure the Solution with the project setup. You can do this by selecting Project Setup in the project’s homepage.
In the Inputs section of the project setup, reconfigure the connection parameters of the Flow. By default, the Solution works with datasets in a filesystem connection. To connect the Solution to your own transaction data, you will need your admin to inform you of your connection type and schema to be input into the app parameters. Once completed, the Reconfigure button will rebuild the full Flow to work with your data. Following reconfiguration, you can refresh the webpage, and search for and test the transaction dataset.
Once you have uploaded your data, the data needs to be preprocessed before identifying association rules. Within the Transactions preprocessing section of the project setup, you can define how the transactions dataset should be transformed. Specifically, it’s here where you can map the schema of the input transaction dataset to the Solution-defined schema (See Data requirements). Additionally, you can clarify the date formatting.
With the data filtered and formatted correctly, move to RFM to define the period of time on which to filter the transaction history to use for RFM scoring. Additionally, select the RFM score computation technique (KMeans vs. quantile) and Monetary Value Policy (total basket amount vs. average basket amount). The appendix of the project wiki goes into detail about the difference between these methods and policies.
Optionally, you can apply RFM propagation to the data by setting parameters of the RFM Propagation section. The overall project Flow will look different from that presented above if you have propagation turned off. Applying propagation allows you to apply the selected RFM scoring method on a larger date range that you define and enables you to see how customers have transitioned between segments over time.
We offer two final sections to make the project more production-ready. The Build all Flow at once section allows you to run all jobs needed to build the Flow using set parameters from the project setup. The Automation section activates pre-built scenarios to refresh the project with new data over time.
Once you’ve built all elements of the project setup, you can either continue to the Project View to explore the generated datasets or go straight to the dashboards to visualize the data.
Under the hood: Computing RFM scores and segmenting customers#
Tip
If you’re mainly interested in the visual components of this pre-packaged Solution, feel free to skip this section.
The Dataiku app is built on top of a Dataiku Flow that has been optimized to accept input datasets and respond to your selected parameters. Let’s walk through the different Flow zones to get an idea of how this was done. We will begin by focusing on the first branch of the Flow, which is specifically dedicated to the computation of RFM scores and customer segmentation based on those scores.
Flow zone |
Description |
|---|---|
Mandatory Inputs |
Contains the transactions_dataset which is populated by ingesting the transactions table defined in the Inputs section of the app. By default, it contains a publicly available dataset we’ve provided. Additionally, there is an editable dataset that you can use to tailor the segments applied to customers (name, recency, and frequency values, plus a color hex code used for visualizations). This editable dataset is later synced into a non-editable dataset via the segments_identification_sync Flow zone. 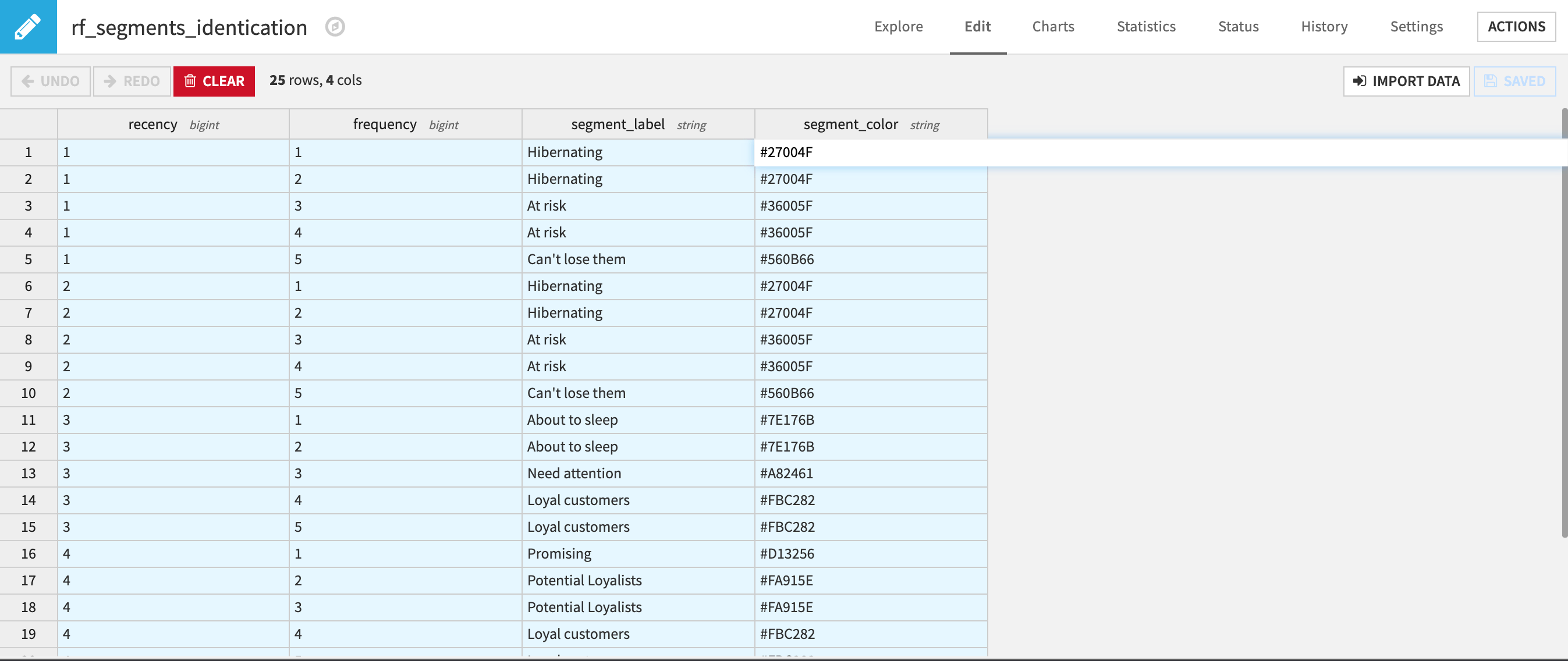
|
Transaction Preprocessing |
Renames columns, parses the date column if needed, extracts date elements, computes total price per transaction, and retrieves the RFM reference date defined in the app as a constant to the dataset. |
RFM Computation Preprocessing |
Takes the prepared transaction dataset and aggregates the transaction data by customer so that you can create the features necessary for RFM scoring. It’s in this section that you also filter transactions based on the period of time defined in the Dataiku app as the dates filtering strategy. |
RFM Segmentation |
Applies the selected RFM scoring method and segments customers based on this score in the rfm_segmentation Flow zone using a single Python recipe. The recipe scores and segments all customers. A managed folder stores the resulting RFM scoring information to be used later for optional propagation. Once again, you can find highly detailed explanations of how this project works, as well as reference materials, in the project wiki. |
Datasets for Dashboards |
Customer RFM segments are passed along to this zone, which isolates the datasets required for the various charts in the dashboards. |
Under the hood: Computing RFM scoring propagation#
Note
If you chose not to propagate RFM scoring, you can skip this section.
The second branch of the Flow, which applies the RFM scoring method to a pre-defined propagation period, is seemingly more complicated than the first branch detailed above, but, it’s straightforward in practice.
Flow zone |
Description |
|---|---|
RFM Propagation Preprocessing |
Takes the prepared transactions dataset and aggregates the transaction data by customer per month. As a result, you get, for each month a customer made a transaction, the features that are used to apply the selected RFM scoring method. The Flow also filters transactions based on a period of time, but the period is much larger than the one defined by the selected dates filtering strategy. |
RFM Propagation |
Leverages the RFM scoring information learned in the RFM Segmentation Flow zone and applies RFM segmentation to customers on a larger period of time. |
RFM Propagation Last Dates |
Filters customer RFM data to focus only on the most recent RFM segments and customers present in those recent segments. From this subset of data, you can then identify customers not present in the most recently identified segments as inactive customers. |
RFM Propagation Scores |
Computes the average RFM score for each month of the propagation period for analysis in the dashboard of month-over-month changes. |
RFM Propagation Transitions |
Computes the transitions between RFM features (recency, frequency, monetary value), as well as the transitions between RFM segments, before splitting the dataset into individual datasets per feature/segment so that you can analyze all transitions across multiple axes. 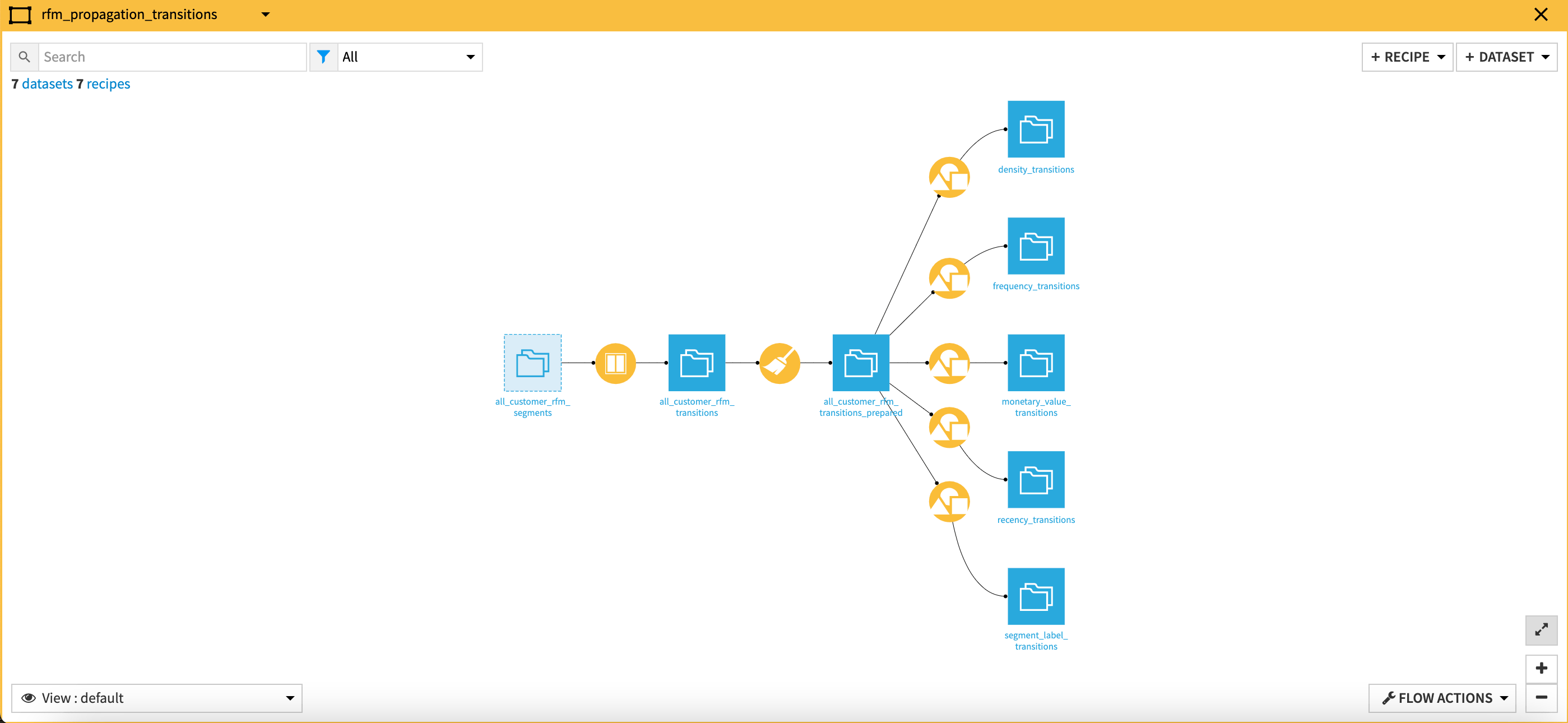
|
Datasets for Dashboards |
Customer RFM segments are passed along to this zone, which isolates the datasets required for the various charts in the dashboards. |
Further explore your customer segments with shareable visualizations#
The RFM Segmentation Solution comes with two prebuilt dashboards: Business Analysis and Data Science Validation. You will begin by walking through what’s available in this dashboard.
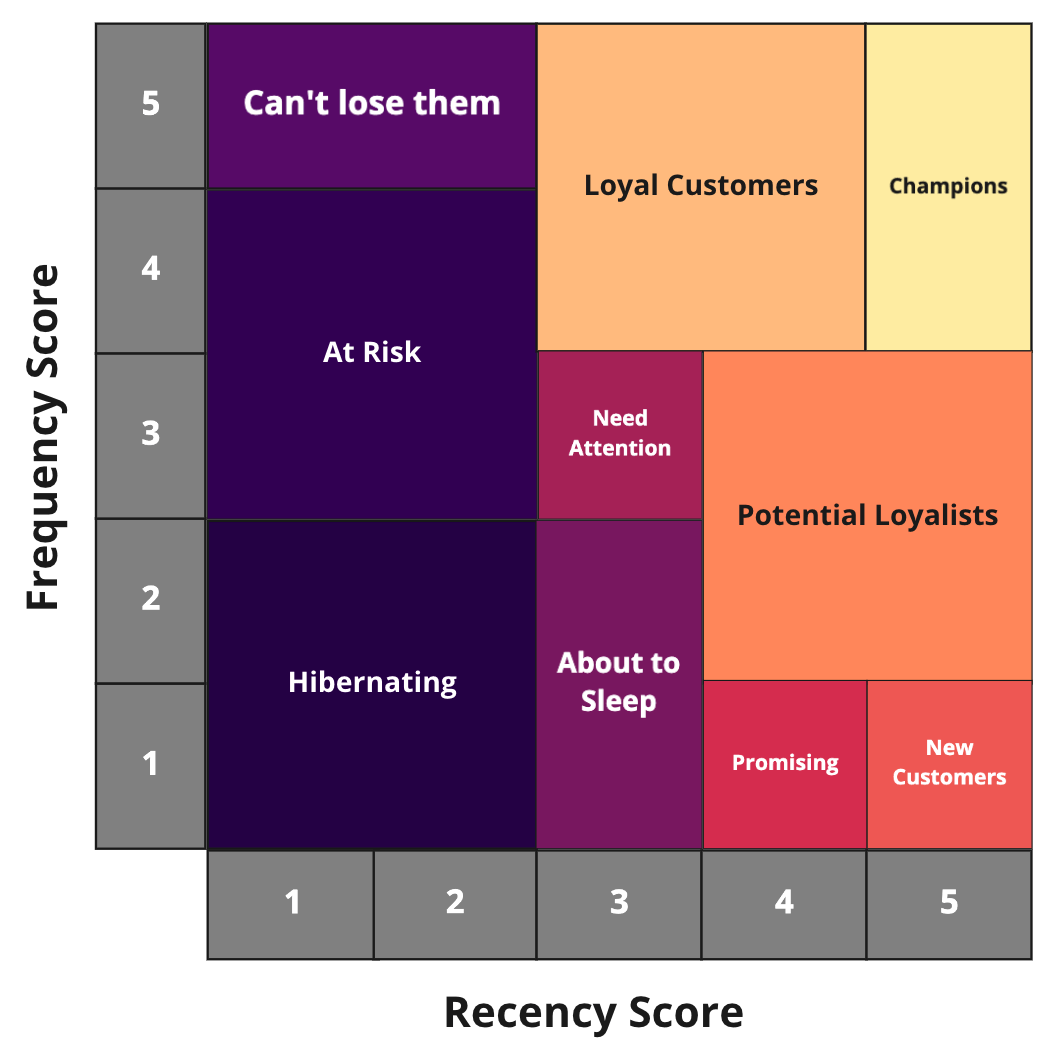
The RFM Analysis delivers a treemap chart that enables you to explore the distribution of customers within RFM segments. The colors used for each customer segment and monetary value are defined in the editable dataset of the Inputs section and within the project variables, respectively.
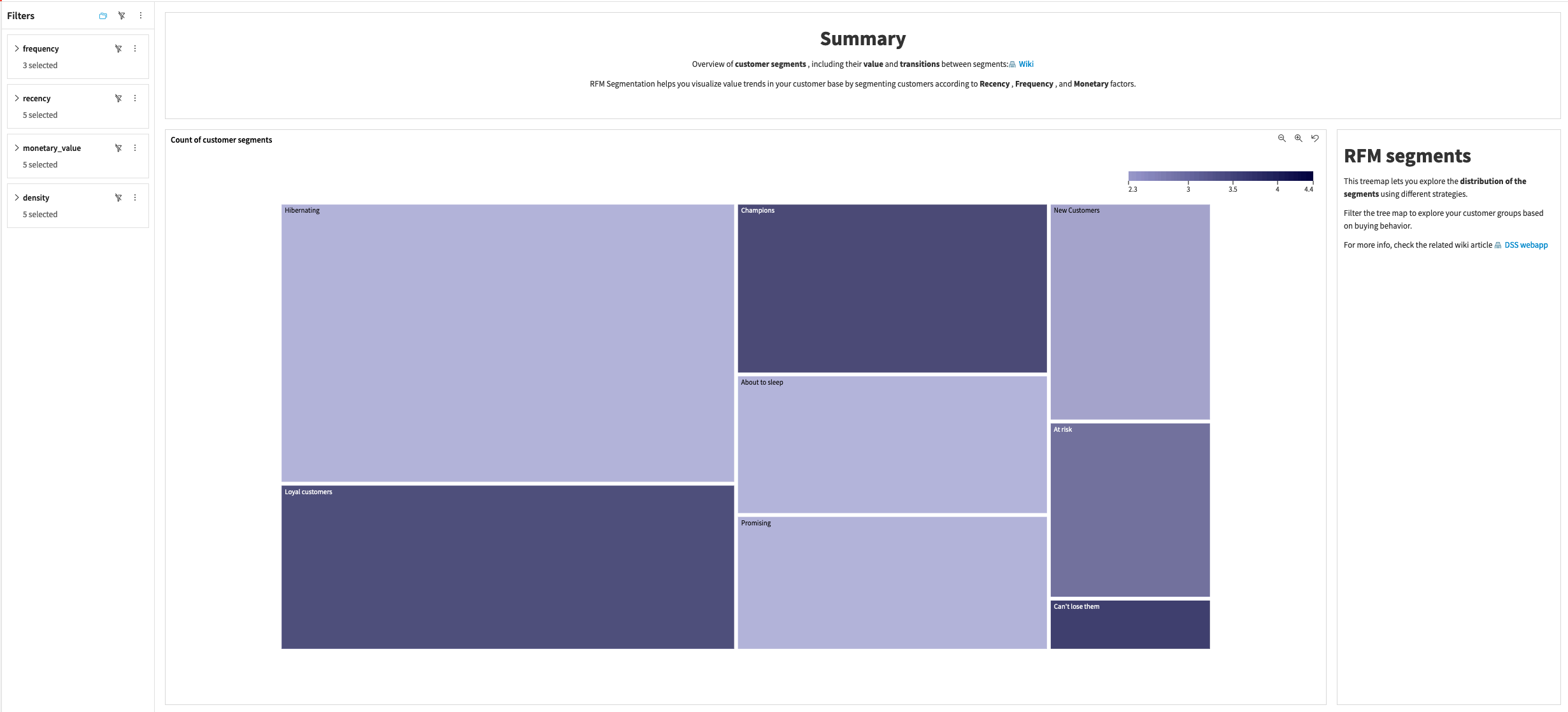
If you enabled RFM propagation, you can select between reference period customers, most recent dates customers, and inactive customers as the data source for treemap analysis.
The Treemap exploration strategy lets you choose between three different types of analysis:
Analyzing segments on whole data
Shows customer segments based only on recency and frequency, while ignoring their monetary value.
Analyzing segments by monetary value relative importance
shows the customer segments based on their recency and frequency, but additionally groups them by their respective monetary value.
Analyzing segments split by monetary value
Creates individual treemaps for a specific monetary value that can be selected/deselected, of the recency and frequency segments occurring in your dataset.
Two tabs are made available to analyze RFM scores. The first focuses on understanding the composition and occurrences of RFM scores, while the second tab contextualizes the RFM segments in a more global view.
Lastly, the EDA tab presents univariate and bivariate analyses of the RFM core information (that is, the customer features leveraged to assess RFM scoring).
Assuming RFM propagation was enabled, you can also access the RFM Propagation dashboard containing three pages:
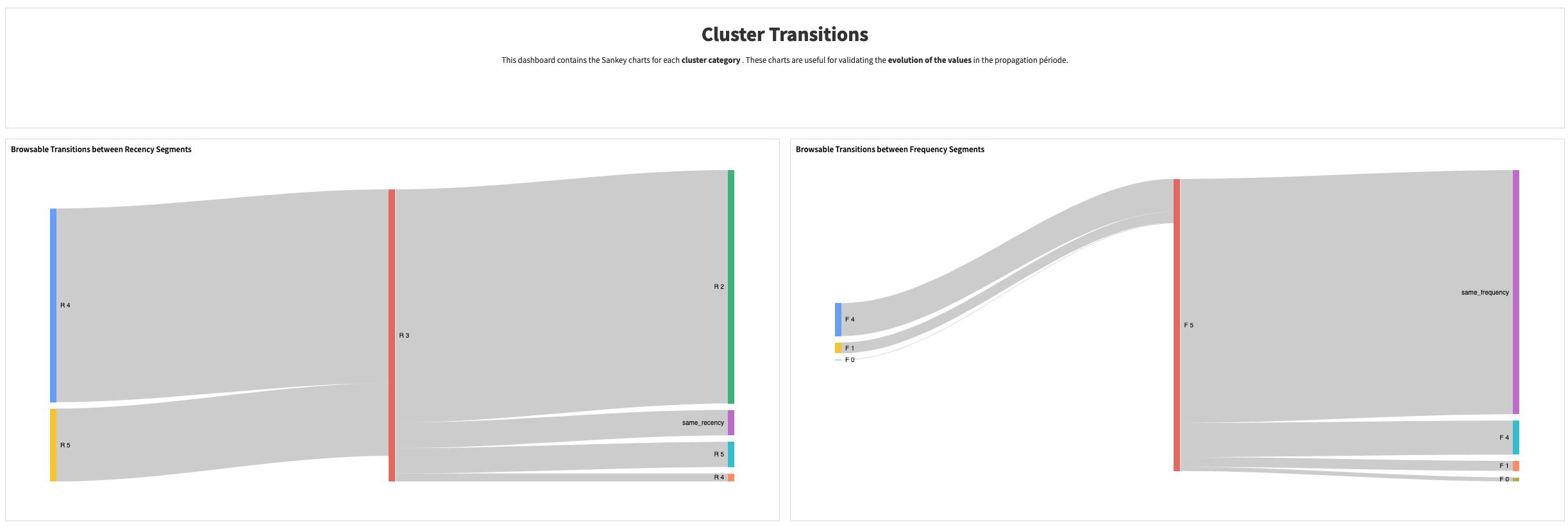
The RFM transitions tab uses a Sankey diagram to see the transitions occurring between RF segment labels (defined in the originating editable dataset). The chart is centered around customers classified as “Champions” so on the left side you can see all customer segments from which “Champions” originated while the right side shows other segments that customers tend to transition to once they’re Champions. There are additional charts in this tab to see transitions between:
Recency Scores
Frequency Scores
Monetary Value Scores
Density Scores
These transitions are computed on all months included in the propagation period.
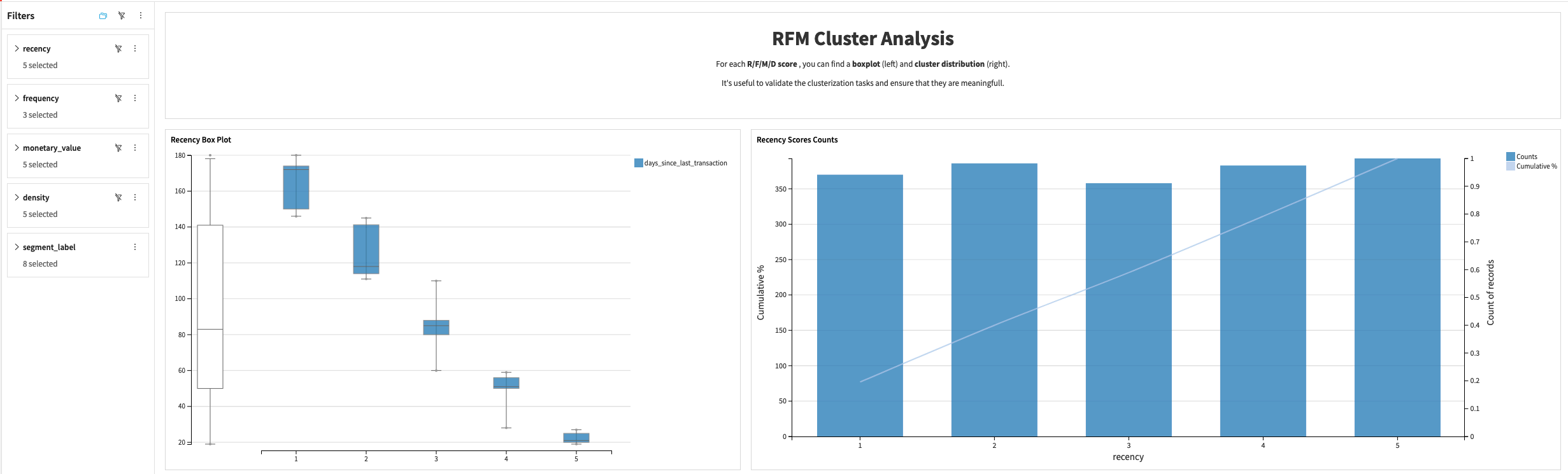
The RFM scores over time tab allows you to see the evolution of a variety of scores over time with bar colors indicating the period when these scores were computed. The scores over time include:
RFM Scores
RFMD Scores
Recency Scores
Frequency Scores
Monetary Value Scores
Density Scores
A short note on automation#
It’s possible to automate the Flow of this Solution based on new data, a specific time, etc. via the Project Setup. You can tune all trigger parameters in the Scenarios menu of the project.
Additionally, you can create reporters to send messages to Teams, Slack, email, etc. to keep your full organization informed. You can also run these scenarios ad-hoc as needed. You can find full details on the scenarios and project automation in the wiki.
Reproducing these processes with minimal effort for your data#
This project equips marketing teams with a plug-and-play Solution using Dataiku to segment customers by their RFM scores.
By creating a singular Solution that can benefit and influence the decisions of a variety of teams in a single organization, you can design smarter and more holistic strategies to optimize customer retention, identify at-risk customers, improve customer communication, and adapt marketing strategies to customer segment distributions.
This documentation has provided several suggestions on how to derive value from this Solution. Ultimately however, the “best” approach will depend on your specific needs and data. If you’re interested in adapting this project to the specific goals and needs of your organization, Dataiku offers roll-out and customization services on demand.