
Solution | Product Recommendation#
Overview#
Business case#
Companies that successfully implement personalization drive 40% more revenue than the average company. And this should come as no surprise: indeed, 71% of consumers expect companies to deliver personalization and are more likely to shop with brands that they recognize, that understand them, and provide relevant offers and recommendations that grow lasting relationships.
Recommending the right product to customers is now a must-do to secure market share and build loyalty. You can do this by implementing a recommendation engine based on a collaborative filtering approach which aims at answering the question: what items will appeal to customers who share similar preferences?
By answering this important question, brands can in turn recommend products that customers haven’t yet purchased. The resulting outcome: product discovery, increased customer engagement, and improved revenue.
With this Solution, companies open an opportunity to optimize their customer engagement activities, starting with online experiences:
A website landing page specifically tailored to logged-in users.
A digital app connecting customers to personalized offers.
Promotional emails personalized based on purchase history.
And much more!
Installation#
From the Design homepage of a Dataiku instance connected to the internet, click + Dataiku Solutions.
Search for and select Product Recommendation.
If needed, change the folder into which the Solution will be installed, and click Install.
Follow the modal to either install the technical prerequisites below or request an admin to do it for you.
Note
Alternatively, download the Solution’s .zip project file, and import it to your Dataiku instance as a new project.
Technical requirements#
To use this Solution, you must meet the following requirements:
Have access to a Dataiku 14+* instance.
Recommendation systems plugin.
A Python 3.9 code environment named
solution_product-recommendationswith the following required packages:
numpy<1.27
Flask==2.0.2
scikit-learn>=1.0,<1.6
pillow==11.3.0
scikit-image==0.24.0
opencv-python-headless==4.11.0.86
imageio==2.37.0
Werkzeug==2.3.7
The Solution comes with empty filesystem-managed datasets. Still, it needs SQL databases to use the Recommendation System Plugin, as its recipes depend on an SQL engine to run memory-intensive processes.
This Solution is compatible with the following connections:
Snowflake
Google Cloud Platform: BigQuery + GCS (You need both if you want to leverage BigQuery).
PostgreSQL
Microsoft SQL Server and Azure Synapse are compatible with the plugin but require roll-out services for this Solution
Data requirements#
The Solution comes without any data, but you should respect the following data model when connecting your data.
Data |
Description |
|---|---|
iteractions_history |
Mandatory dataset containing records of all the historical interactions between users and items with the following columns:
|
user_metadata |
Optional dataset containing information about our customers with the following columns:
|
item_metadata |
Optional dataset providing information about products with the following columns:
|
item_pictures |
Optional managed folder containing all product pictures. All images must be .jpg format |
Workflow overview#
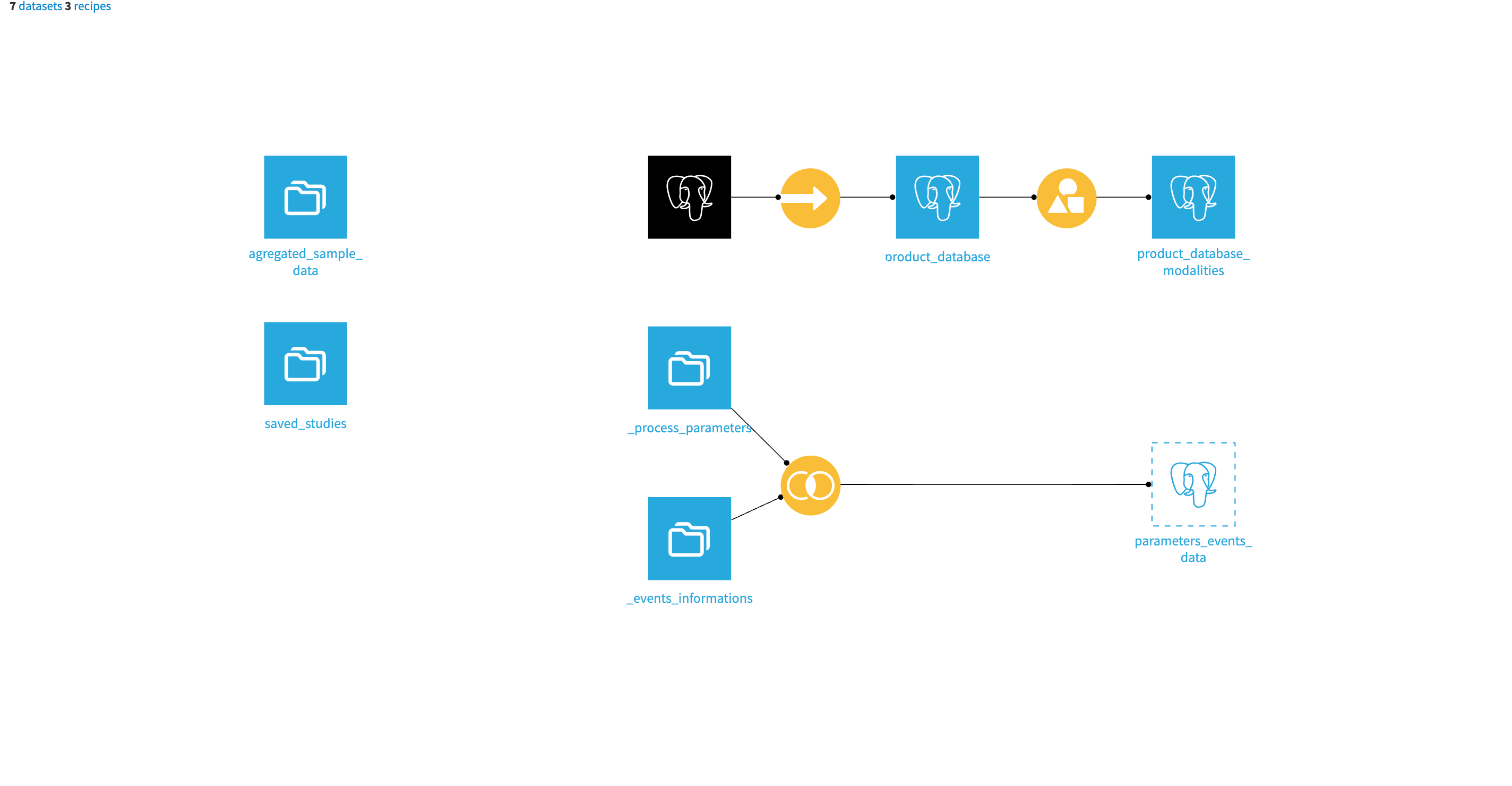
The project has the following high-level steps:
Connect your data as input and select your analysis parameters via the Dataiku app.
Join and prepare input data.
Apply collaborative filtering on established customers to create negative samples for downstream modeling.
Train a recommendation model with visual ML.
Calculate affinity scores and apply collaborative filtering on growth customers.
Predict product recommendations for growth customers.
Interactively explore the outputs of analytics Flow and automate reports.
Walkthrough#
Note
In addition to reading this document, it’s recommended to read the wiki of the project before beginning to get a deeper technical understanding of how this Solution was created and more detailed explanations of Solution-specific vocabulary.
Plug and play with your data and parameter choices#
To begin, you’ll need your own instance of the Dataiku app associated with this Solution.
From the waffle (
 ) menu of the Design node’s top navigation bar, select Dataiku Apps.
) menu of the Design node’s top navigation bar, select Dataiku Apps.Search for and select the application with the name of this Solution.
Then, click Create App Instance.
Once you’ve created a new instance, you can walk through the app steps to add your data and select the analysis parameters to run. Users of any skill level can input their desired parameters for analysis and view the results directly in a user-friendly webapp. You could also instantiate multiple Product Recommendation projects to compare your approaches.
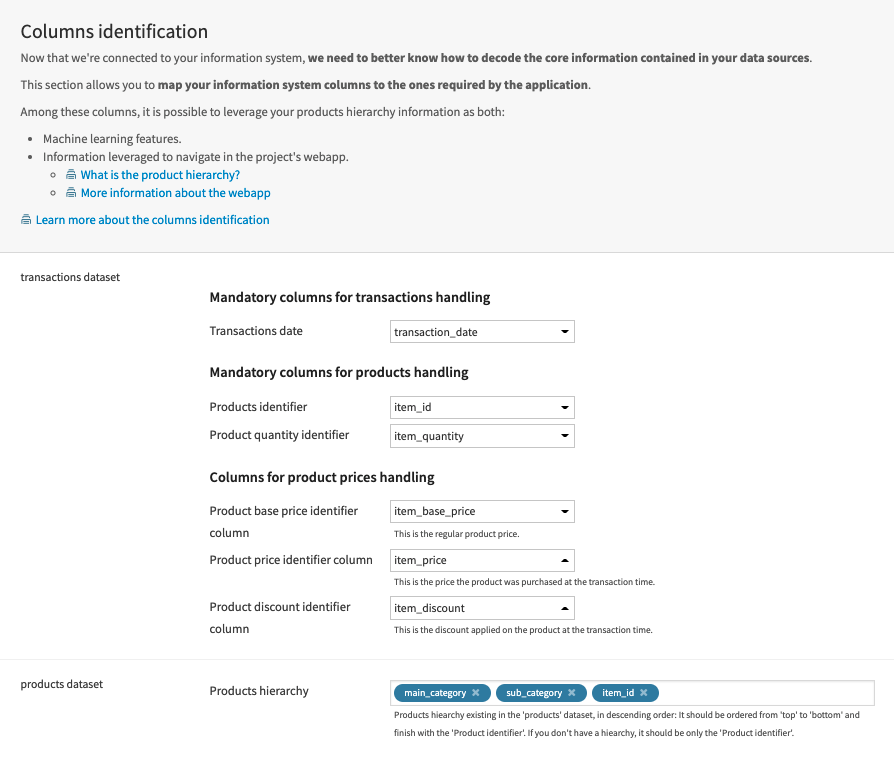
The first step of the Dataiku app, Connection settings, is to specify the connection where the data is available to be ingested into the Product Recommendation Solution.
It’s recommended to use the Dataiku app to reconfigure the Flow to your connection and data since it provides a more straightforward experience than manually updating the Flow to your desired connection.
The following two sections (Data specifications and Columns identification) of the Dataiku app is where you specify the datasets from the connection that you want to use and which optional datasets you want to include before going on to identify the main columns used by each included dataset. After inputting these details and reconfiguring the Flow, this allows the Solution to automatically map data to the data schema of the Solution.
Prepare data and identify customer types#
Moving along to the Recommendation framing sections of the Dataiku app, you can set the main parameters associated with the data batch used to create the recommendation system. Here you can:
Define the data batch parameters, including the reference data and the window of historical data to use for feature engineering and machine learning training.
Set the minimum number of interactions a user must have to be included in the recommendation system.
Define the items selection strategy.
Precise the max number of recommendations to propose for each user.
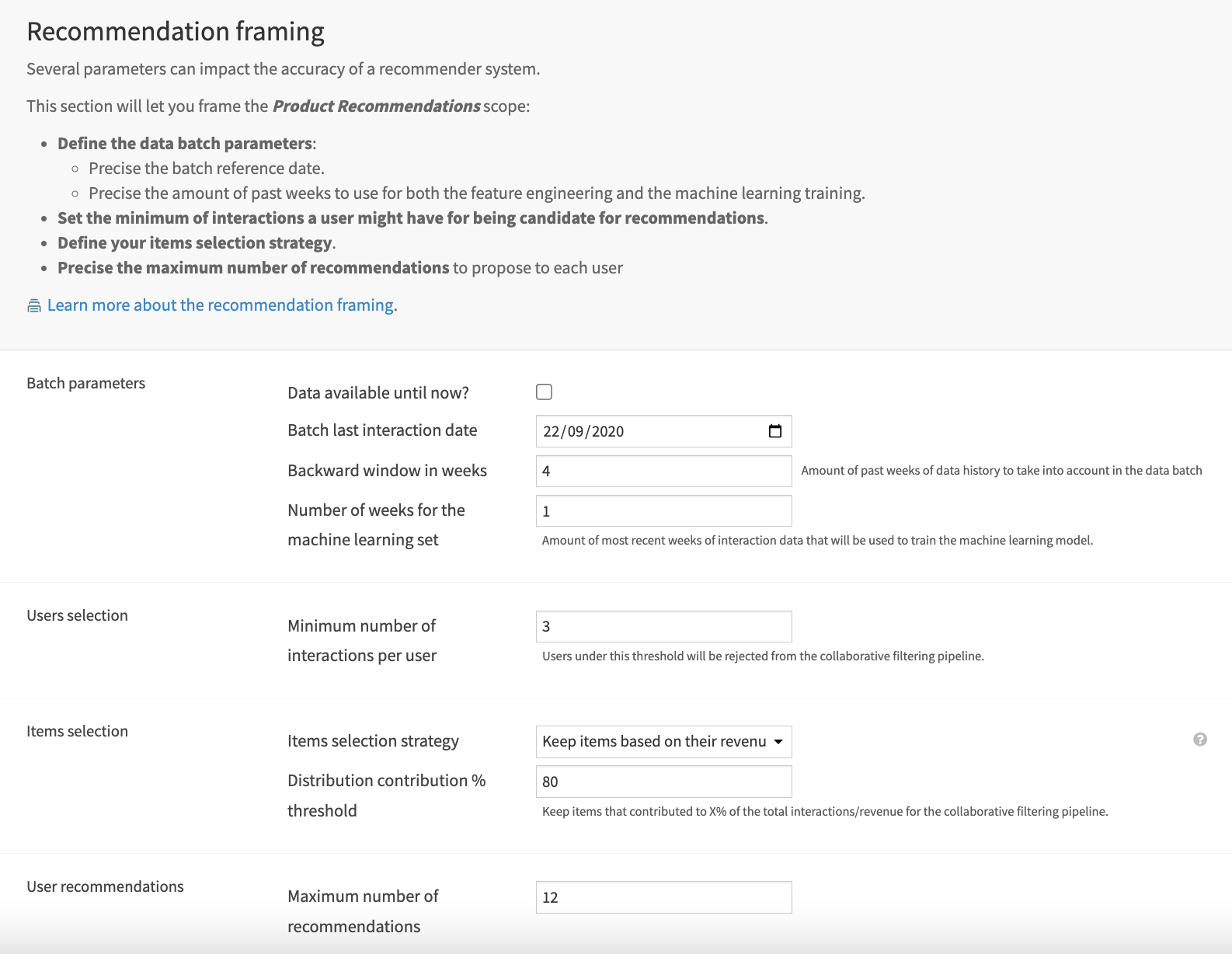
The values that you input in this section and your selections within the Data specifications and Columns identification are applied to your data via the data prep Flow zones. The Flow zone, ages_clustering, is optionally run only if your data contains a user’s age column for age clustering.
The resulting prepared data has been filtered to your specifications, cleaned and split so that some data is set aside for computing affinity scores, and the rest is ready for training a machine learning model based on the computed affinity scores.
Leveraging item metadata in product recommendations#
In the Recommendation feature engineering section of the Dataiku app, you can configure how to use the ingested item metadata for feature engineering.
You have three options:
Item characteristics feature engineering will apply collaborative filtering on the user-item-characteristics interactions recorded in your specified batch.
If chosen, optional Flow zones to apply characteristics of collaborative filtering will be run.
If the above is selected, then you can also select the specific columns to use for computing collaborative filtering features.
Model features enrichment will join item characteristics to all other features so that the recommendation model can take them into account.
Item characteristics feature engineering and model features enrichment will use both methods listed above.
Note
Collaborative filtering is an approach to feature engineering that uses information about the number of interactions and user ratings for products to generate affinity scores between users and products. These scores are based on correlations between pairs of items and pairs of users. Using matrix factorization, these affinity scores for a given user/item pair are calculated from the pairwise correlations.
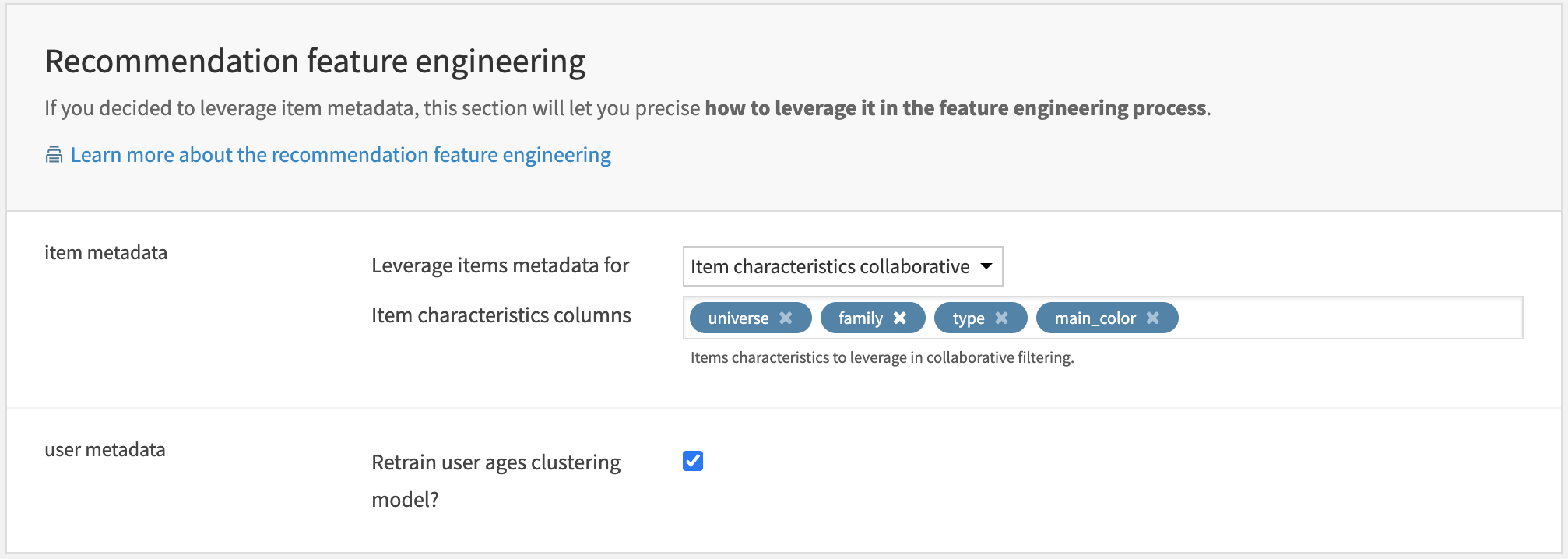
Once you’ve selected how you want to use the item metadata, you can also choose to retrain the ages_clustering_model during the Flow build.
Defining and training the recommendation model#
The final section of the Dataiku app where you need to input parameters is the Product recommendations modeling section. Here you can configure the machine learning model parameters used for training. To begin, you’ll be asked to choose an optimization strategy between the following ones.
Optimization strategy |
Description |
|---|---|
Optimize model ‘Precision’ |
Means that you will give preference to having a precise model at the risk of missing positive predictions. |
Optimize model ‘Recall’ |
Means that you will give preference to having an opportunistic model over a precise model. |
Optimize model ‘F1 Score’ |
Is a trade-off between being precise and opportunistic. |
Lastly, you can create model evaluation visualizations (subpopulation analysis and PDP) for the dashboard to better understand the model. Doing so can prove valuable in model transparency and understanding but will significantly increase computation time.
Once you’re satisfied with your chosen parameters, you can click the Run button and wait for the full Flow to build. When complete, you can directly go to the pre-built dashboard by clicking the provided link in the Dataiku app.
Recommending products to grow customer engagement#
The Product Recommendation Solution comes with a prebuilt dashboard containing the following tabs.
Tab |
Description |
|---|---|
Recommendations Explorer |
Provides a prebuilt webapp to audit and validates the behavior of your Product Recommendations model in an interactive and visually rich way. It will allow you to select users from the operating system and see their historical purchases side-by-side with their recommended products. You can view this in a tabular format, or if the item_images managed folder contains images, in a picture grid way. 
|
Recommendation model evaluation |
Provides metrics by which you can evaluate the model. If you choose to evaluate the model via subpopulation analysis, the resulting graph will be available in this tab. |
Recommendation model interpretation |
Provides a feature importance graph and, optionally, a partial dependence plot so that you can understand the most important variables and assess the relationship between input features and model predictions. |
User Analysis and Item Analysis |
Provide several charts to explain users behavior/how items are solicited so that you can iteratively tune the selected parameters of the Dataiku app to create a more accurate Product Recommendation model. |
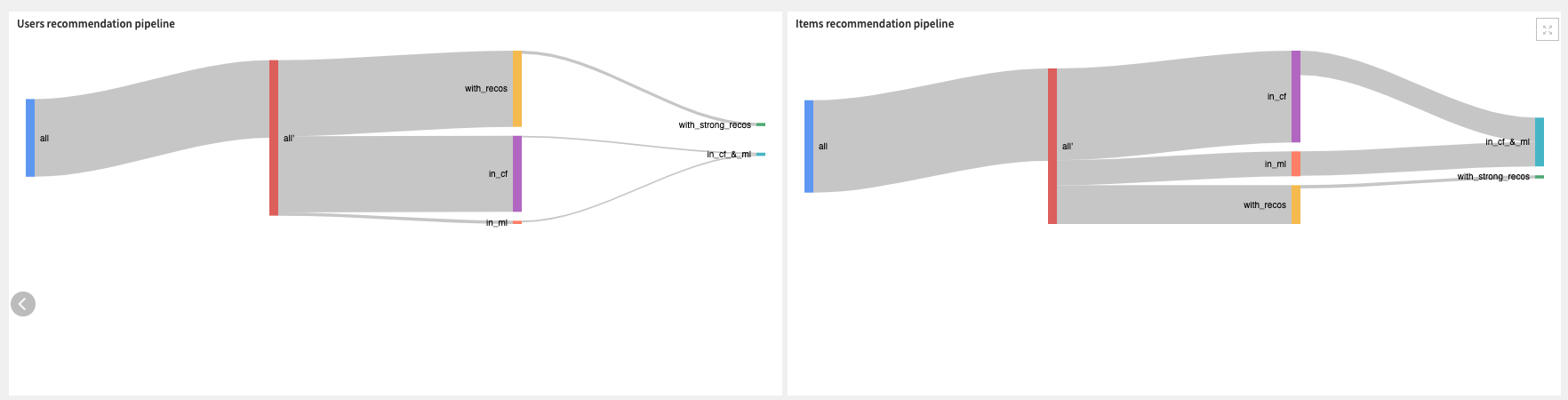
Lastly, you can get a global overview of the volume of users and items involved in a batch, among all collaborative key milestones, via Sankey Charts provided in the Recommendation pipelines tab.
A short note on automation#
It’s possible to automate the Flow of this Solution based on new data, a specific time, etc. via the Project Setup. You can tune all trigger parameters in the Scenarios menu of the project.
Additionally, you can create reporters to send messages to Teams, Slack, email, etc. to keep your full organization informed. You can also run these scenarios ad-hoc as needed. You can find full details on the scenarios and project automation in the wiki.
Reproducing these processes with minimal effort for your data#
This project equips customer management and marketing teams to understand how they can use Dataiku to generate personalized product recommendations for customers.
By creating a singular Solution that can benefit and influence the decisions of a variety of teams in a single organization, you can design smarter and more holistic strategies to engage with customers, design marketing strategies, and serve as the basis for better product pricing.
This documentation has provided several suggestions on how to derive value from this Solution. Ultimately however, the “best” approach will depend on your specific needs and data. If you’re interested in adapting this project to the specific goals and needs of your organization, Dataiku offers roll-out and customization services on demand.