
Reference | Usage parameters for SQL databases#
As an example of how the “Allow managed datasets” usage parameters varies based on connection type, let’s look at the usage parameters for a PostgreSQL connection.
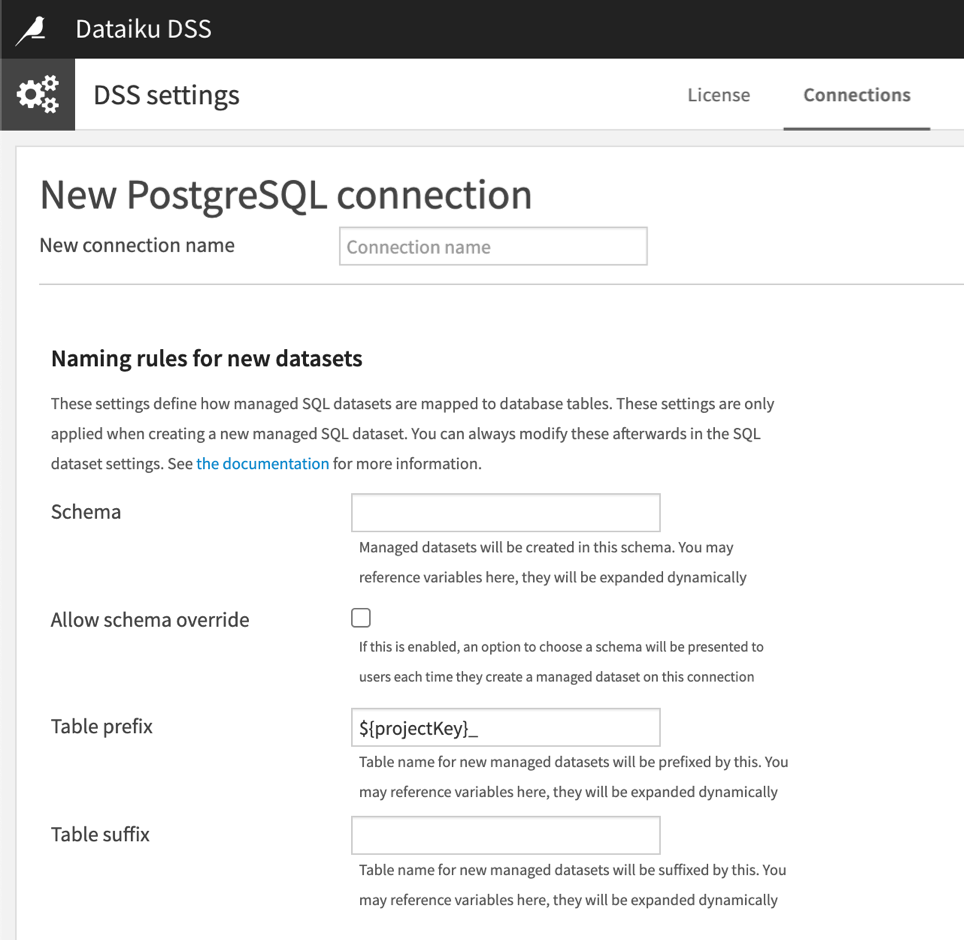
Naming rules for new datasets and folders#
You can define a schema with the option to allow schema override. You can apply the same prefix and suffix mechanism as for metastore table names.
Read only data lake example#
The following diagram depicts an example of a strategy with a read-only data lake and a dedicated DSS bucket for managed datasets.
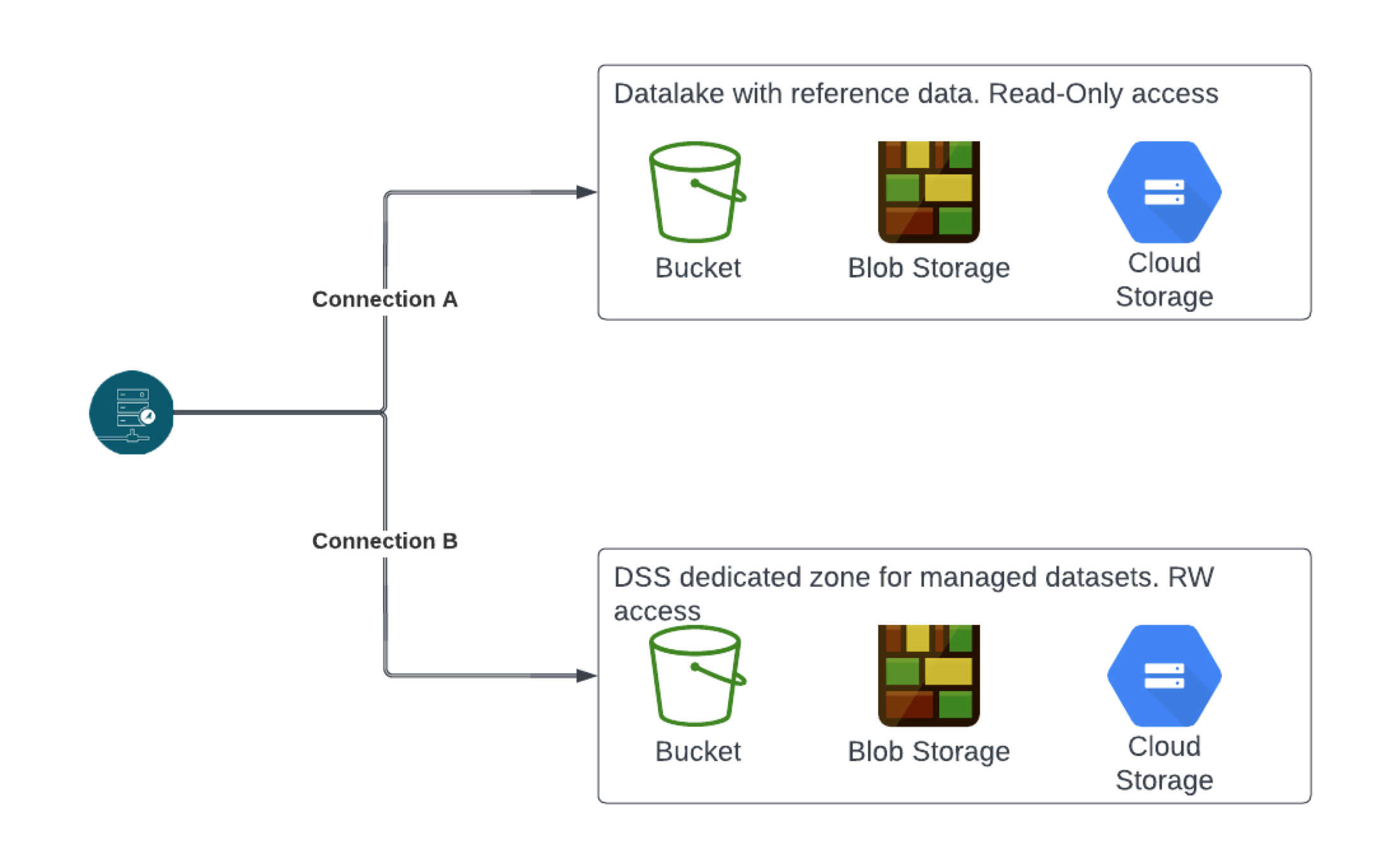
This basic example demonstrates how connections can be separated to answer security or governance concerns. In this example, two connections are created inside DSS.
Connection A refers to DSS connection defined to interact with a cloud storage used as a reference data lake inside the company. This storage won’t be editable by DSS.
Connection B refers to a storage zone in which DSS (through the Service Account defined in both connections) will be able to write its managed datasets.
Service Account Configuration
When creating the Service Account it will be attached to policies allowing a set of actions:
Read access on the data lake storage (and the metastore if needed).
Read/Write access on the dedicated DSS storage so that managed datasets can be created and managed (deletion, metadata update…).
Connections Configuration
Both connections will be created using the same service account for interactions. Each will point to the relevant object storage.
The connection used for managed datasets will be configured with the following:
Allow write activated
Allow managed datasets activated
Some optional extra configuration specific to the managed datasets (Path, prefix, metastore…)
The connection used to reach the data lake will be configured with the following:
Allow write deactivated
Allow managed datasets deactivated
This connection won’t be available when selecting an output zone inside the flow.