
Solution | Batch Performance Optimization#
Overview#
Business case#
Batch processes form a critical part of the manufacturing value chain where inefficiencies cost billions of dollars each year. This is true in anywhere from the production of bulk chemicals and packaged goods or performing critical cleaning processes in food and drug production.
At a time when supply chains are stressed and raw material prices are increasingly volatile, the need to maximize equipment utilization by reducing downtime and to improve yield by reducing unnecessary waste becomes even more critical. The proliferation of IoT devices and centralized data collection systems for plant automation networks has led to unprecedented opportunities for enterprise manufacturers.
The challenge ahead is now to turn the mountain of data produced by automation networks into insights actionable by engineers and other professionals running batch manufacturing processes.
With this Solution, organizations can quickly enhance their capacity to dissect vast volumes of production process data. They can develop actionable insights for technicians, operators as well as reliability and process engineers, to understand root cause of failures and to predict batch outcomes. This can accelerate the move from reaction to anticipation in batch manufacturing.
Installation#
From the Design homepage of a Dataiku instance connected to the internet, click + Dataiku Solutions.
Search for and select Batch Performance Optimization.
If needed, change the folder into which the Solution will be installed, and click Install.
Follow the modal to either install the technical prerequisites below or request an admin to do it for you.
Note
Alternatively, download the Solution’s .zip project file, and import it to your Dataiku instance as a new project.
Technical requirements#
To use this Solution, you must meet the following requirements:
Have access to a Dataiku 12.0+* instance.
Please also note that Dataiku instances with a built-in environment of Python2, instead of Python 3, will be unable to use the webapp. For instances with a built-in environment of Python2, users should create a basic Python3 code env and set the project to use this code env.
Data requirements#
The Solution takes in two input data sources.
Dataset |
Description |
|---|---|
input_sensor_data |
Contains all the sensors values from all the machines in the following format:
|
input_batch_data |
Contains information about batch general parameters in the following format:
In this second dataset, you can add as many columns as you have batch parameters (string type). You will use these parameters to analyze your batches and predict failure. |
Workflow overview#
You can follow along with the Solution in the Dataiku gallery.
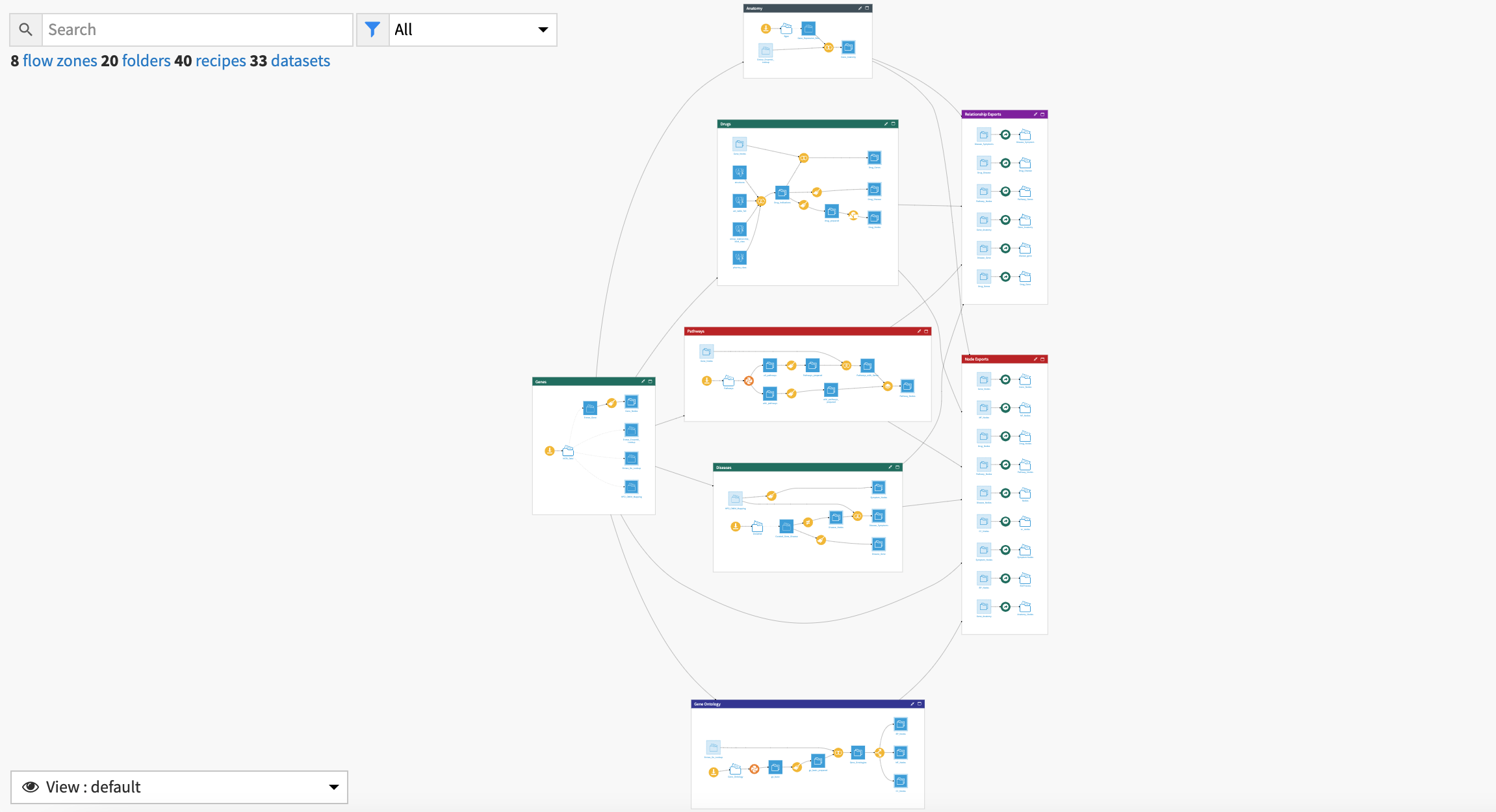
The project has the following high-level steps:
Connect your data as input and select your analysis parameters via the Dataiku app.
Ingest and prepare the data.
Train, score, and use a failure prediction model.
Analyze the historical batch data.
Explore batch history, analyze sensors, and predict failure risk with an interactive webapp.
Walkthrough#
Note
In addition to reading this document, it’s recommended to read the wiki of the project before beginning to get a deeper technical understanding of how this Solution was created and more detailed explanations of Solution-specific vocabulary.
Plug and play with your own data and parameter choices#
To begin, you’ll need your own instance of the Dataiku app associated with this Solution.
From the waffle (
 ) menu of the Design node’s top navigation bar, select Dataiku Apps.
) menu of the Design node’s top navigation bar, select Dataiku Apps.Search for and select the application with the name of this Solution.
Then, click Create App Instance.
Once you have created the new instance, you can walk through the app steps to add your data and select the analysis parameters to run. Users of any skill level can input their desired parameters for analysis and view the results directly in a user-friendly Webapp. You could also instantiate multiple Batch Performance Optimization projects to compare your feature engineering and modeling approaches.
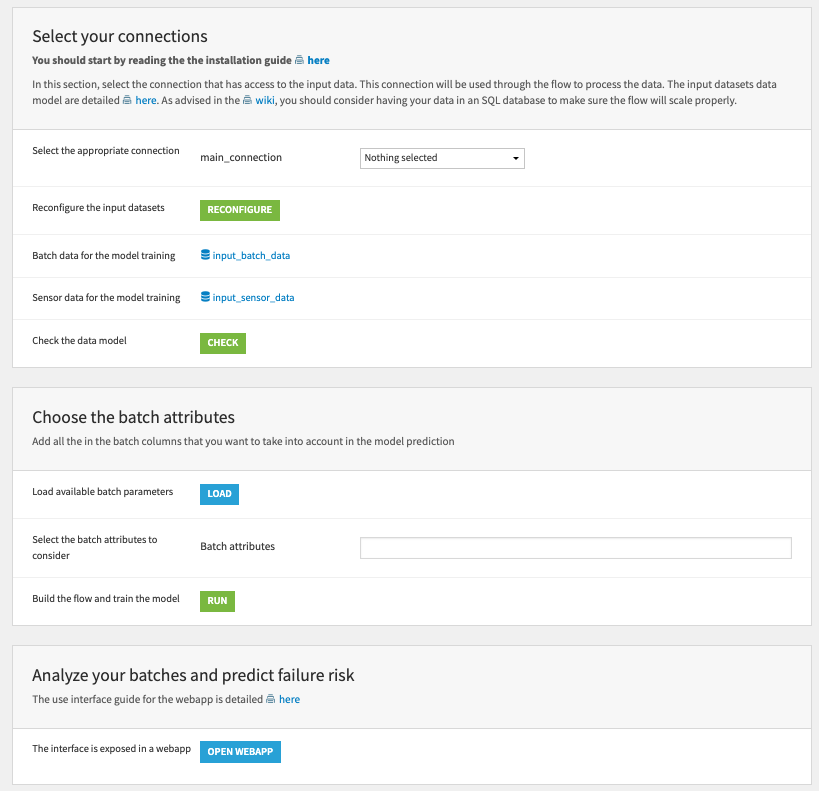
To begin, configure the data connection to retrieve and load the input datasets. You can select a button to confirm that the data fits the data model of the Solution. With the correct data connected, you can load all available batch parameters, and select the batch attributes you want to consider in the model prediction. Clicking Run will train the model, which can take several hours depending on the data size. Finally, click the Open Webapp button to go directly to the interactive visual analysis tool delivered with this Solution.
Once you’ve built all elements of the Dataiku app, you can either continue to the Project View to explore the generated datasets or go straight to the Dashboards and webapp to visualize the data. If you’re mainly interested in the visual components of this pre-packaged Solution, feel free to skip over the following few sections.
Ingest and prepare data#
The first two Flow zones of the project are straightforward. The Data Ingestion Flow zone brings in two initial datasets detailed in the previous Data requirements section.
Once you have access to all input datasets, you can move to the Data preparation Flow zone. This zone first pivots the senor dataset so that there is only one column per sensor before joining it with the batch dataset. To be able to feed the model a reasonable amount of data, it computes and groups by min, max, avg, stddev, and count for each sensor over each batch. This results in a dataset with one row per batch and one column by sensor aggregation.
A final Window recipe transforms the dataset such that each batch connects to information from the previous batch and the next batch failure. The Flow uses this final dataset to train a model. Separately, the Flow applies a Group recipe to the original batch dataset to compute all the different batch parameter combinations used as filters in the Webapp.
Minimizing risk of failure: Training a batch failure prediction model#
The Flow trains a model on the prepared batch and sensor data, specifically training on the failure_last column based on all the previous batch information and the following batch parameters. The model can learn to detect anomalies in the sensor values to predict an imminent failure and help a technician with preventive maintenance.
The Prediction Flow zone is rebuilt by the interactive prediction scenario every time a user initiates a new analysis from the Next Batch Prediction tab of the interactive Webapp. The scenario uses a Python recipe to prepare the batch and sensor data to match the user selection before using the previously trained model to score the data and output the failure risk prediction and Shapley values. A Group recipe filters the train data on the selected batch parameters and compute the average values for each sensor aggregation when it has led to a failure or success.
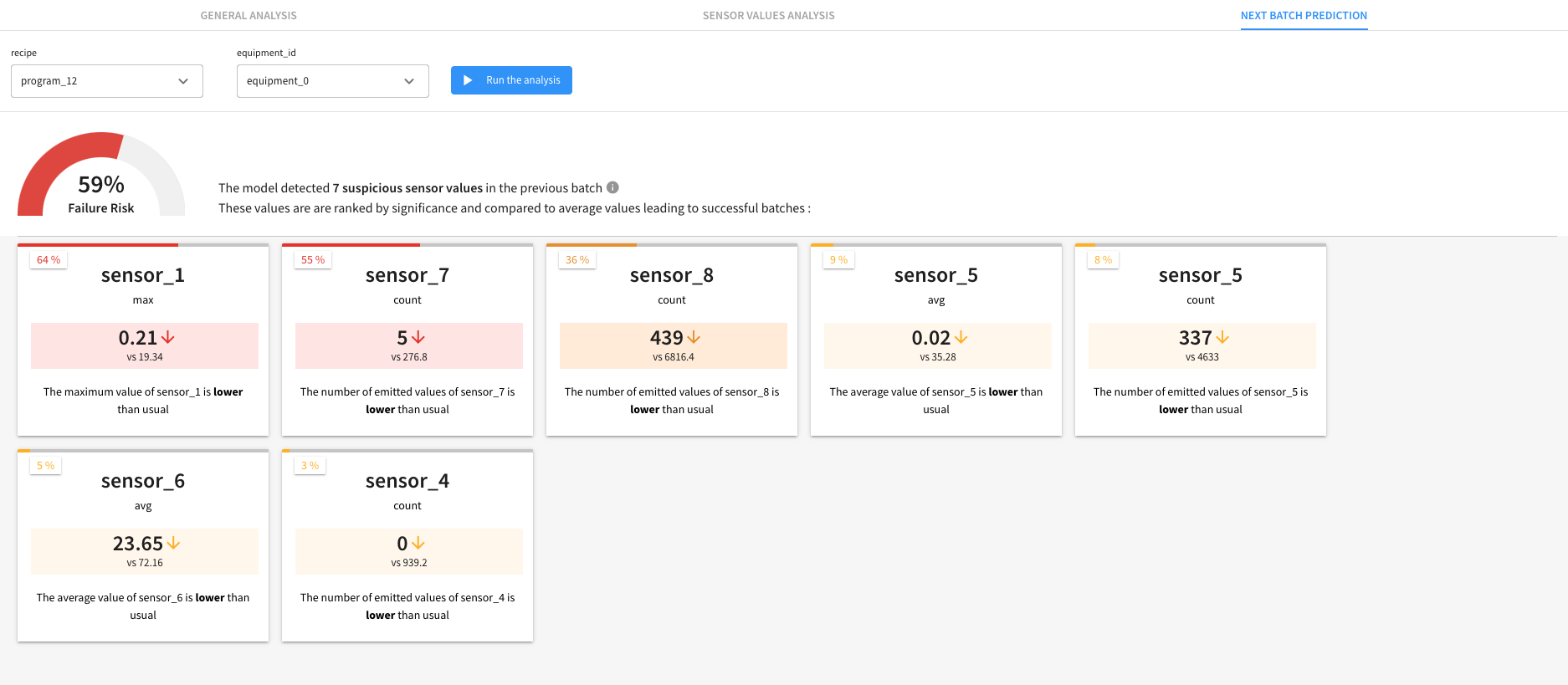
Analyzing batch and sensor data#
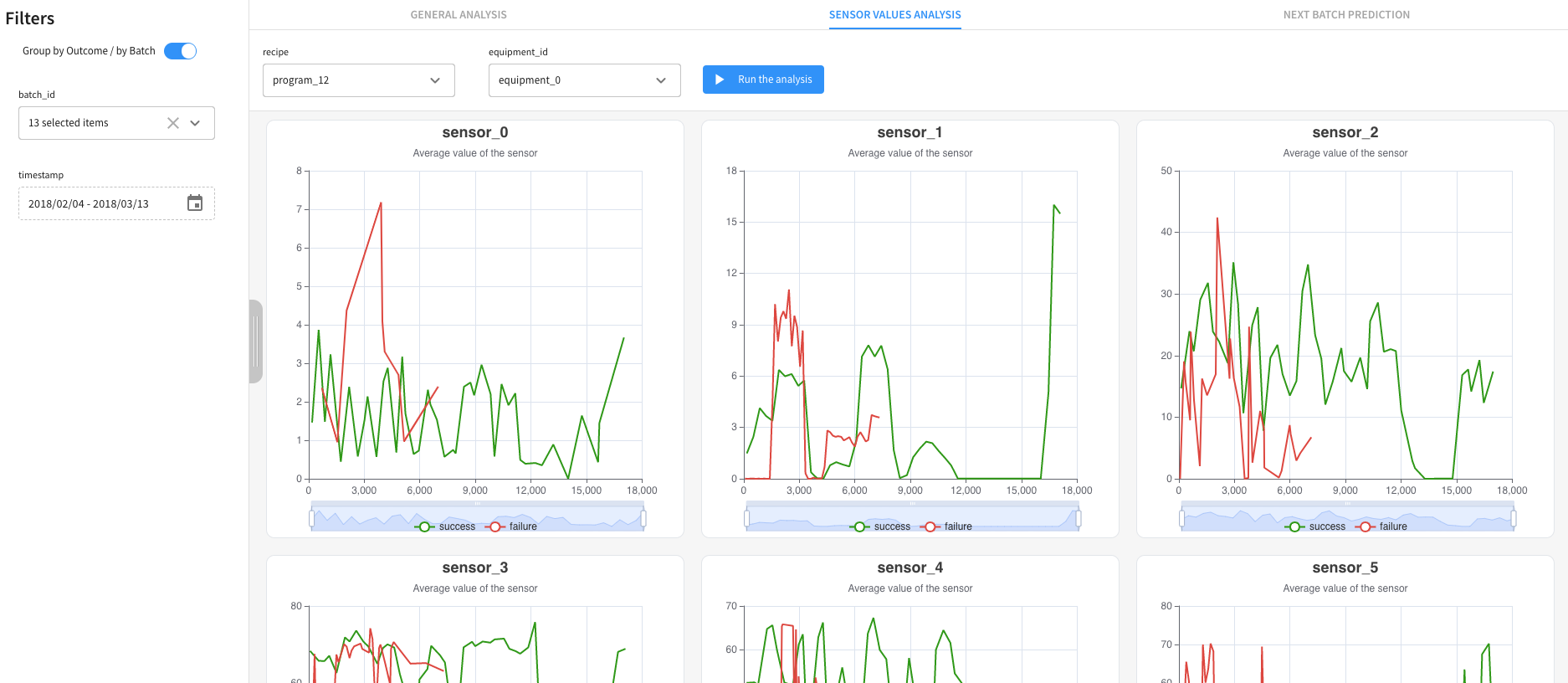
In addition to predicting future batch failures with the trained model, you can also analyze the historical batch and sensor data using the Sensor Values Analysis and General Analysis tabs of the webapp. You can launch a new analysis from the Sensor Values tab, which will rebuild the Batch Analysis Flow zone. Specifically, this Flow zone:
Computes the batch duration, which is displayed in the General Analysis tab.
Filters the data to match the user selection.
Resamples the sensor value to have the elapsed time in seconds.
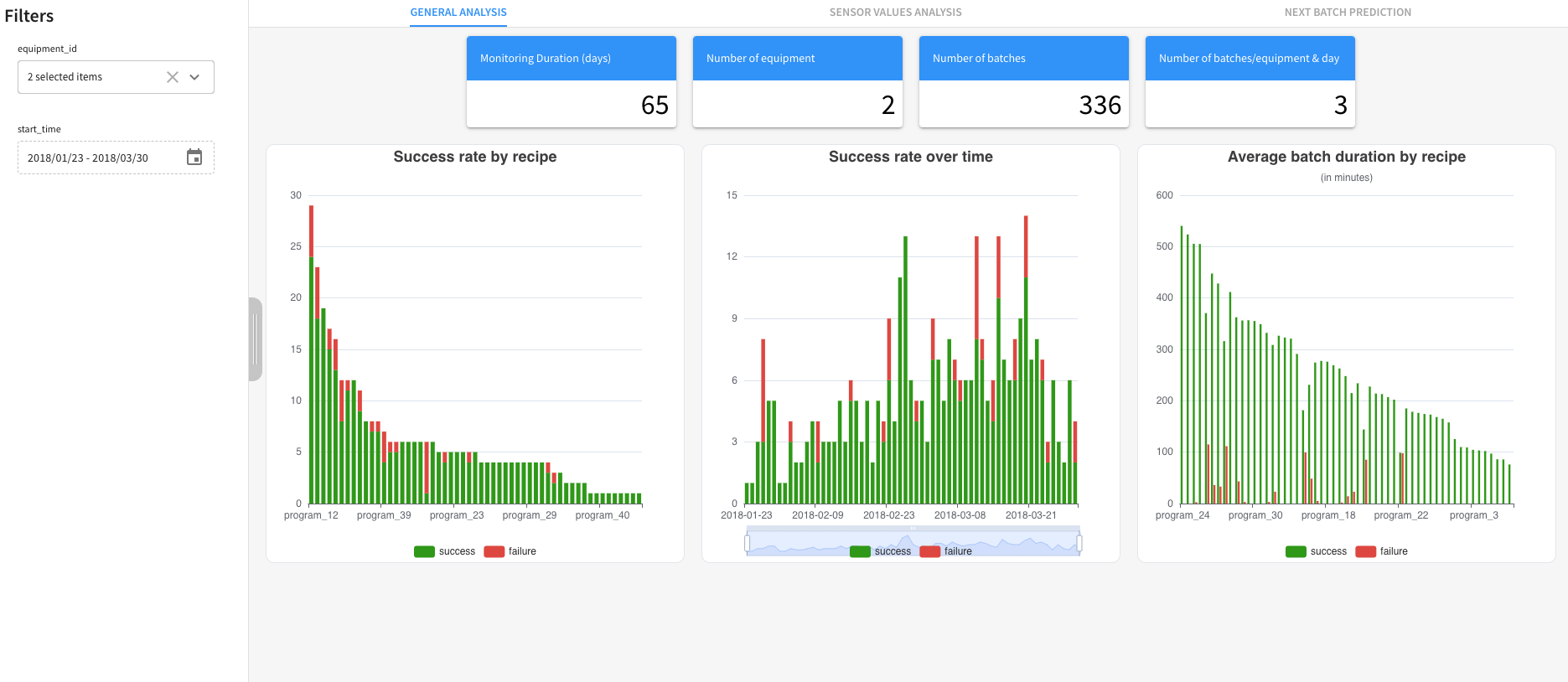
Also, the General Analysis tab contains Success Rate by Batch Parameter and the Success Rate over Time. The outputs of the Batch Analysis Flow zone allow for seeing the charts for each sensor of the machines, aggregated over all the batches corresponding to the selected parameters for the Sensor Values Analysis.
Reproducing these processes with minimal effort for your data#
The intent of this project is to enable an understanding of how you can use Dataiku to analyze sensors and estimate the risk of failure and identify anomalies in equipment. By creating a singular Solution that can benefit and influence the decisions of a variety of teams in a single organization, strategies can be implemented that focus on preventive maintenance, rapid response to equipment failures, and process optimization.
This documentation has provided several suggestions on how to derive value from this Solution. Ultimately however, the “best” approach will depend on your specific needs and data. If you’re interested in adapting this project to the specific goals and needs of your organization, Dataiku offers roll-out and customization services on demand.