
Solution | Customer Satisfaction Reviews#
Overview#
Business case#
Brands face multiple challenges in keeping modern consumers engaged. It’s key for brands to listen to what their customers think, feel, and say about their purchasing experience with them. To do so, brands first need to collect feedback from customers. The latter is one of the key pillars of digital/social commerce.
Sentiment analysis adds a new layer to the performance insights of a brand. It allows them to understand emotions better and measure customer satisfaction. By leveraging actionable ways to transform customer emotion into brand action, marketers can deliver a better customer experience.
The Solution consists of a data pipeline that uses a combination of descriptive statistics and machine learning. Analysts can input their own data and surface the outputs in a dashboard to gauge customer engagement strategies’ previous and future success. Data scientists should use this sample project as an initial building block to develop advanced analytics and support decision-making.
Installation#
From the Design homepage of a Dataiku instance connected to the internet, click + Dataiku Solutions.
Search for and select Customer Satisfaction Reviews.
If needed, change the folder into which the Solution will be installed, and click Install.
Follow the modal to either install the technical prerequisites below or request an admin to do it for you.
Note
Alternatively, download the Solution’s .zip project file, and import it to your Dataiku instance as a new project.
Technical requirements#
To use this Solution, you must meet the following requirements:
Have access to a Dataiku 12.6+ instance.
Dataiku’s Text Visualization Plugin.
A Python 3.9 code environment named
solution-customer_satisfaction_reviewswith the following required packages:
MarkupSafe<2.1.0
Jinja2>=2.11,<2.12
cloudpickle==3.0.0
flask>=1.0,<1.1
itsdangerous<2.1.0
lightgbm>=3.2,<3.3
scikit-learn>=1.0,<1.1
scikit-optimize>=0.7,<0.10
scipy==1.13.0
statsmodels==0.12.2
xgboost==0.82
gluonts>=0.8.1,<=0.10.4
pmdarima>=1.2.1,<1.8.5
mxnet==1.8.0.post0
prophet==1.1.1
holidays>=0.14.2,<0.25
transformers==4.39.3
sentencepiece==0.2.0
torch==2.2.2
Werkzeug==2.1.2
The code environment also requires an initiation script. Users should put the following script in the tab Resources.
## Base imports
from dataiku.code_env_resources import clear_all_env_vars
from dataiku.code_env_resources import set_env_path
from dataiku.code_env_resources import set_env_var
# Clears all environment variables defined by previously run script
clear_all_env_vars()
## Hugging Face
# Set HuggingFace cache directory
set_env_path("HF_HOME", "huggingface")
# Load model directly
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("lxyuan/distilbert-base-multilingual-cased-sentiments-student")
model = AutoModelForSequenceClassification.from_pretrained("lxyuan/distilbert-base-multilingual-cased-sentiments-student")
LLM Mesh connection: This Solution uses Dataiku’s LLM Mesh to interact with local or remote models. An admin needs to configure one connection to run the project.
Data requirements#
The Dataiku Flow was initially built using publicly available data. When adapting the project to your data and needs, having an input dataset of reviews is mandatory to run the project. Each row of the dataset should comprise the following:
Column |
Type |
Description |
|---|---|---|
product_id |
[String] |
Unique identifier for a product |
review_text |
[Text] |
Body of the review written by the customer |
product_category |
[String] |
Category of the reviewed product |
review_date |
[Date] |
Date of the customer review |
review_score_provided |
[Integer] |
Score of the product provided by the user on a scale of 5 |
customer_id |
[String] |
Unique identifier of the customer |
customer_country |
[String] |
Country of residence of the customer |
customer_latitude |
[Double] |
Latitude of a GeoPoint centered on the customer’s country |
customer_longitude |
[Double] |
Longitude of a GeoPoint centered on the customer’s country |
Workflow overview#
You can follow along with the sample project in the Dataiku gallery.
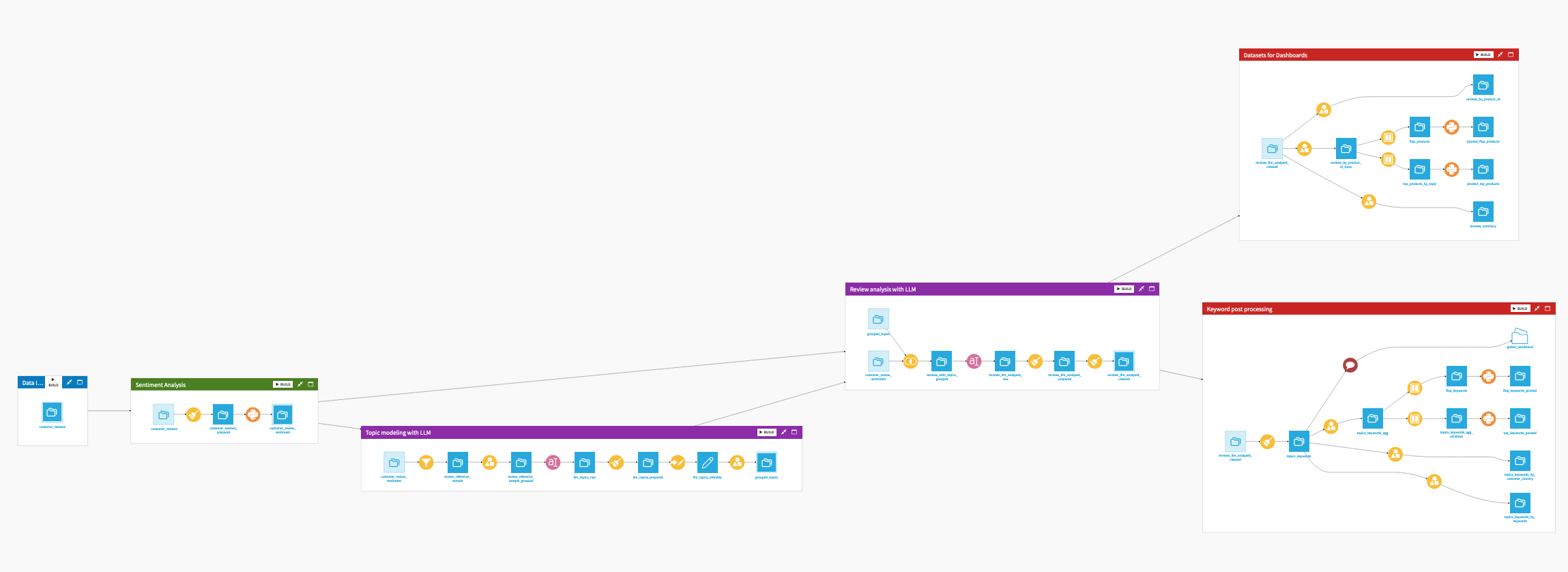
The project has the following high-level steps:
Evaluate the review text’s overall sentiment with an NLP model.
Sample review and identify relevant topics using an LLM.
Extract the rating regarding each topic on every review.
Aggregate results for visualization.
Note
This project is intended as a template to guide the development of your analysis in Dataiku. You shouldn’t use the model’s results as actionable insights, and the data provided by the project may not represent actual data in a real-life project.
Walkthrough#
Note
In addition to reading this document, it’s recommended to read the wiki of the project before beginning to get a deeper technical understanding of how this Solution was created and more detailed explanations of Solution-specific vocabulary.
Sentiment analysis#
Once you have uploaded the correct input data (see Data requirements) to the project, the Sentiment Analysis Flow zone processes the reviews. Using an NLP model, the project evaluates the rating of a review based on its text. This can be compared to the provided rating and be used to avoid irregularities between text and rating (that is, a negative text with a positive rating).
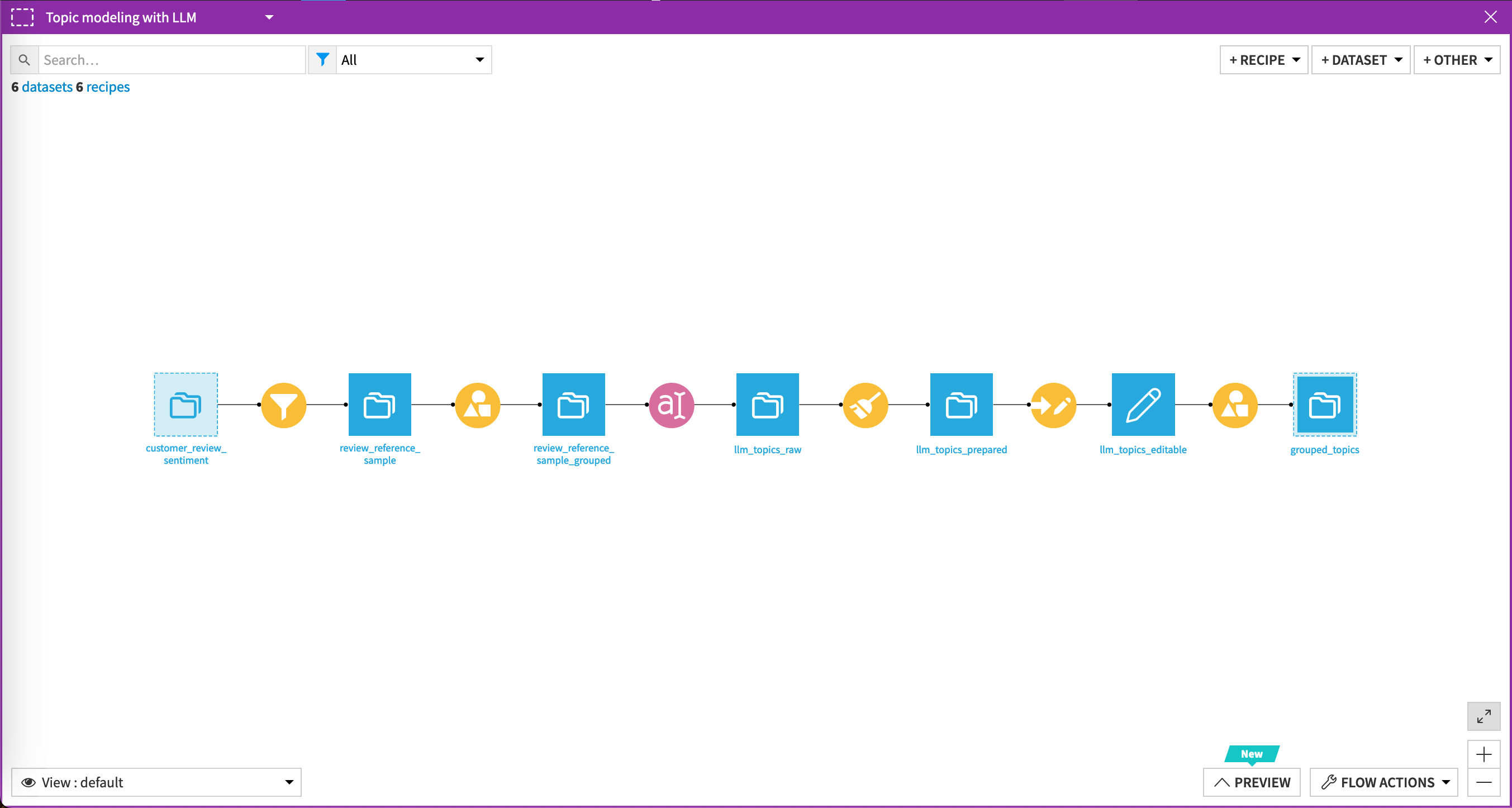
Topic modeling with an LLM#
To extract topics from the data, you can select a sample of the reviews (rebalancing by product) to feed them into the LLM recipe. You can then review the topics in the editable dataset to validate them.
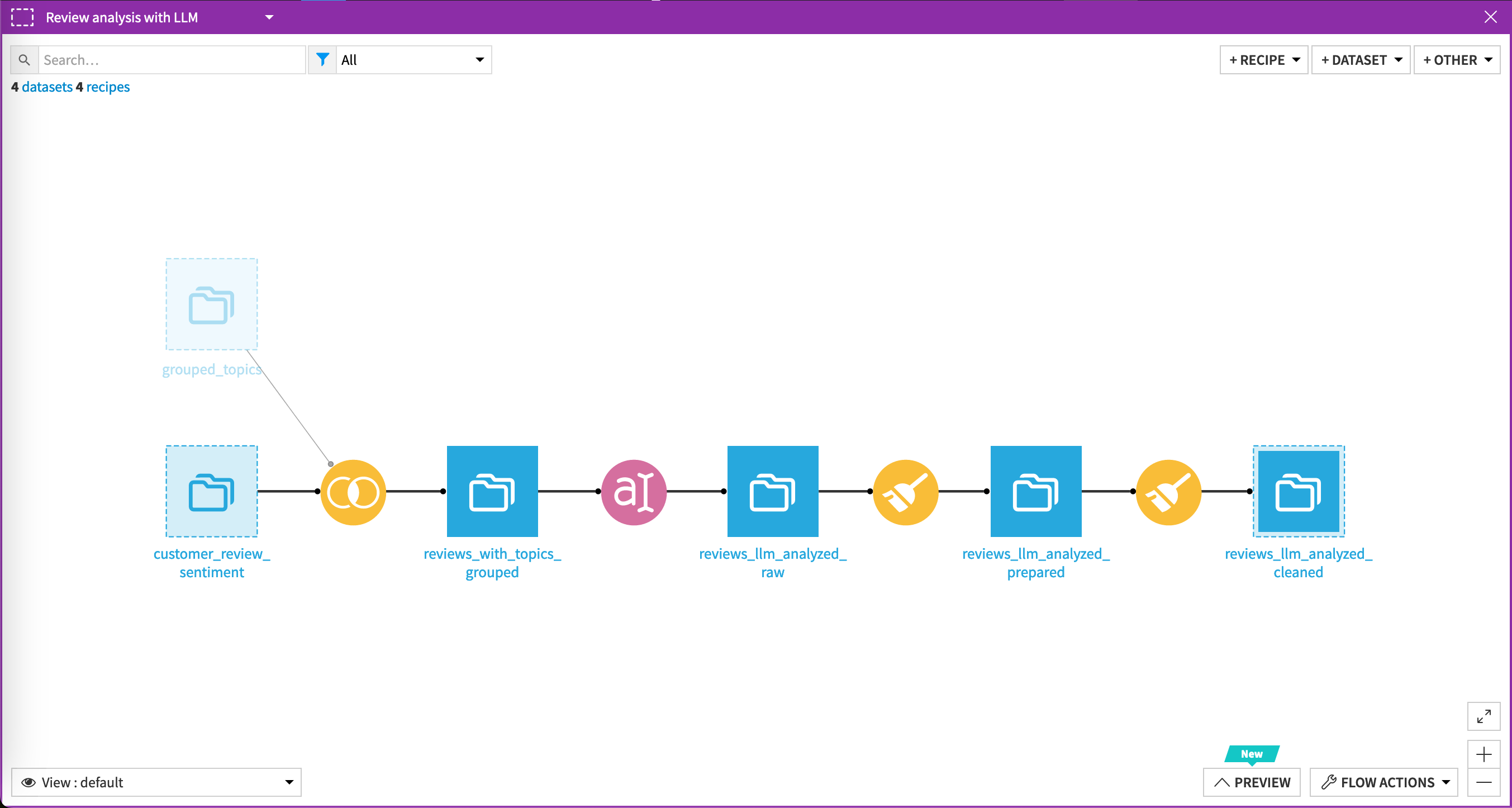
Review analysis with an LLM#
Leveraging the topics, you can ask the LLM to provide a rating for each review. This gives a multimodal perspective on customer satisfaction and helps identify specific strengths or pain points regarding products.
When imported to new instances, LLM Mesh recipes default to No Connection. However, the prompt, inputs, and examples configuration are still stored and will appear pre-filled for review and further editing when you select an LLM connection.
Processing results for dashboards#
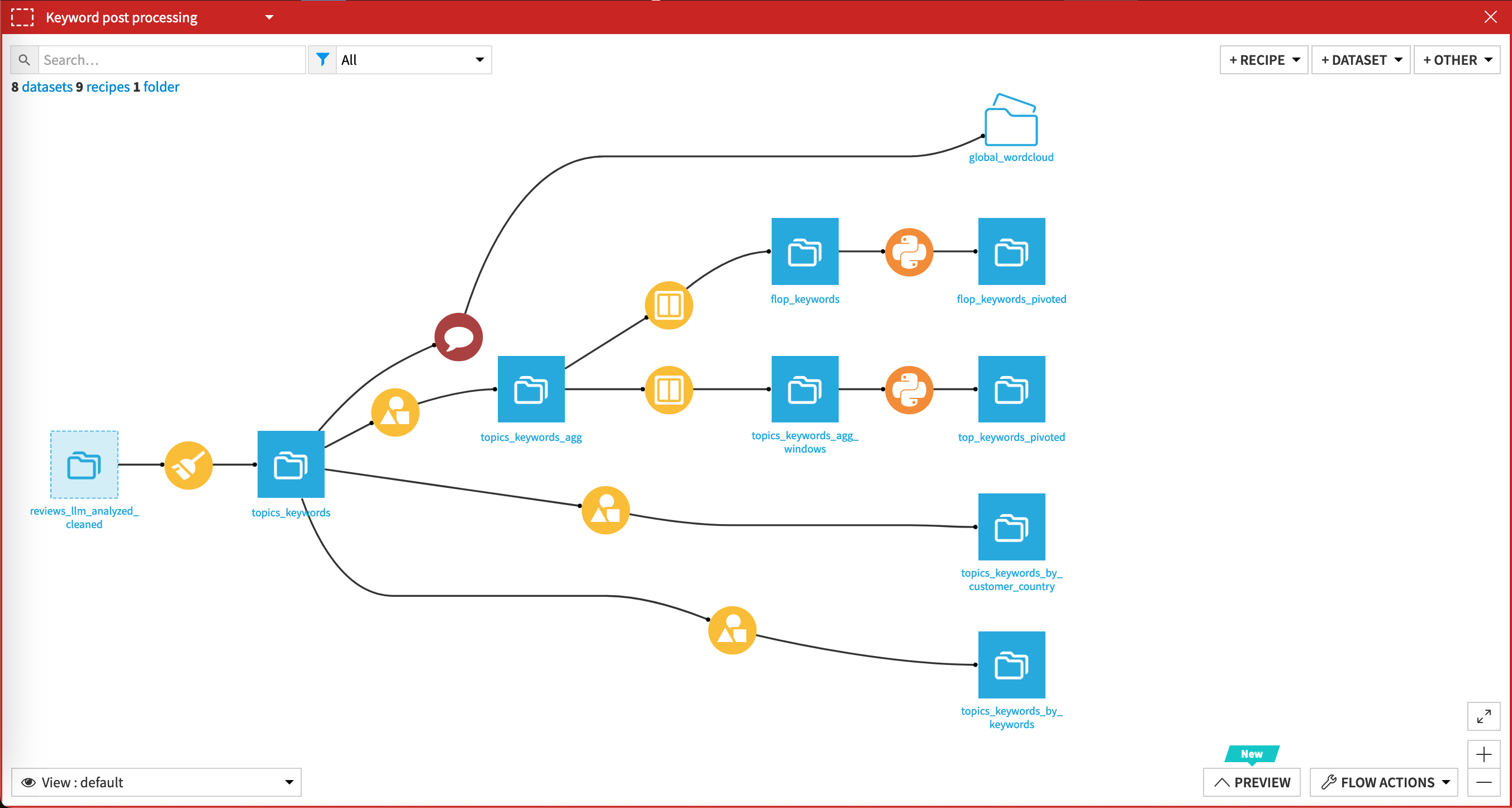
Reviews with the added information from the LLMs are processed in those Flow zones to be displayed in the dashboards.
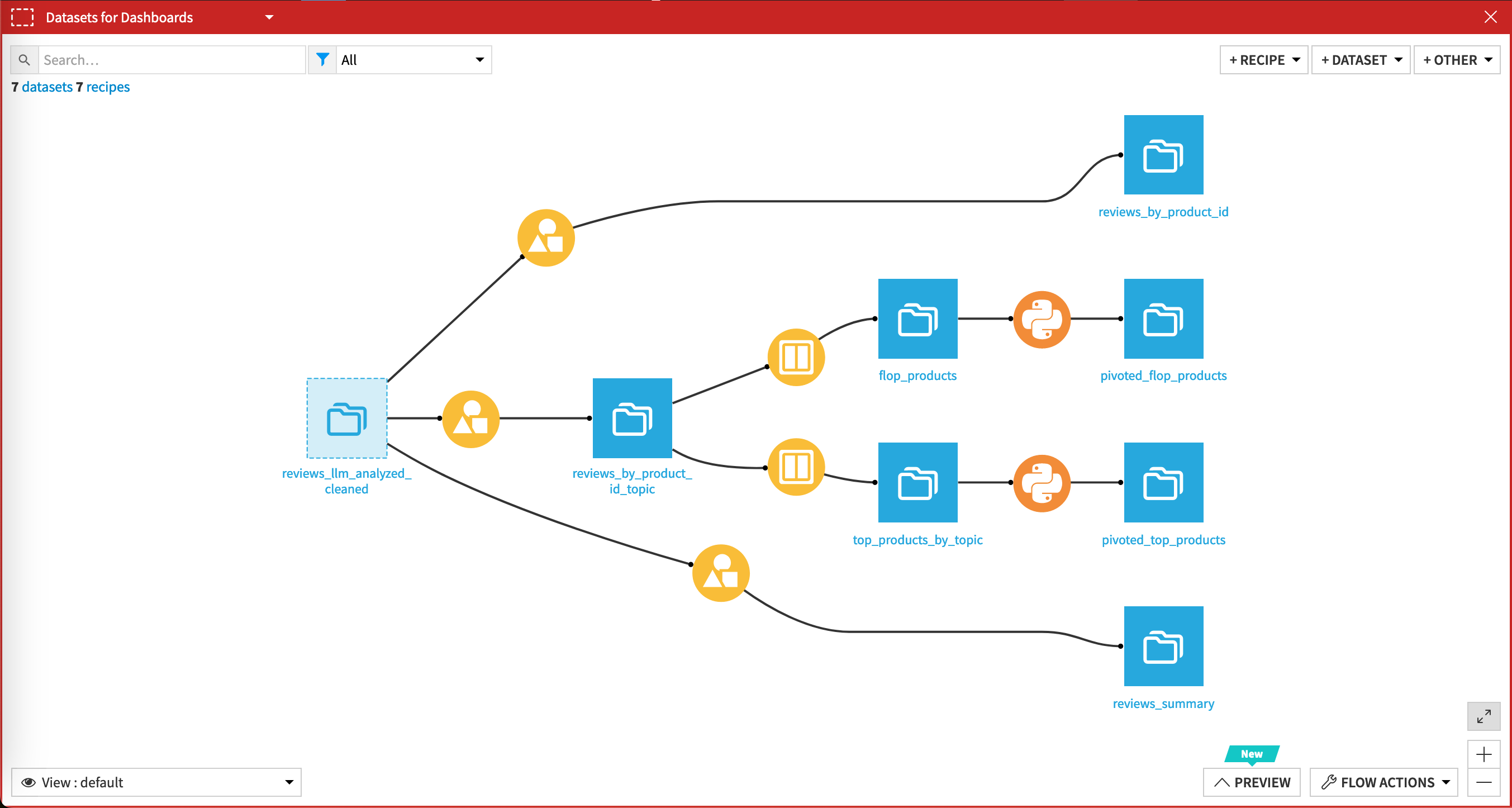
Both Flow zones use Python recipes to pivot and aggregate the datasets to identify the best-performing products and keywords for each topic.
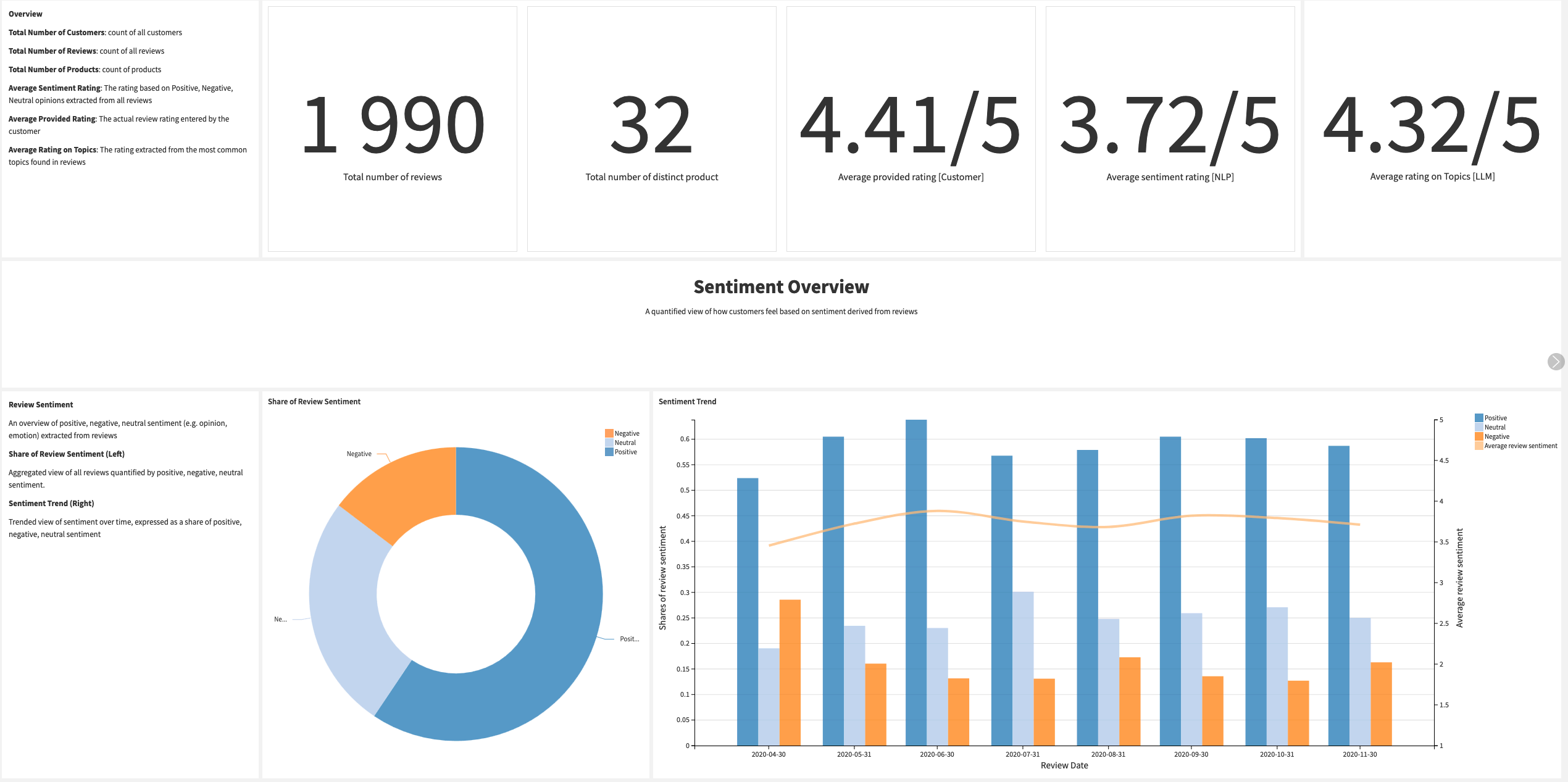
Dashboard#
You can follow the overall rating from the sentiment analysis and the sentiments associated with the identified topics. You can monitor how satisfaction evolves through time with the Sentiment Trend and look for an increase in dissatisfaction.
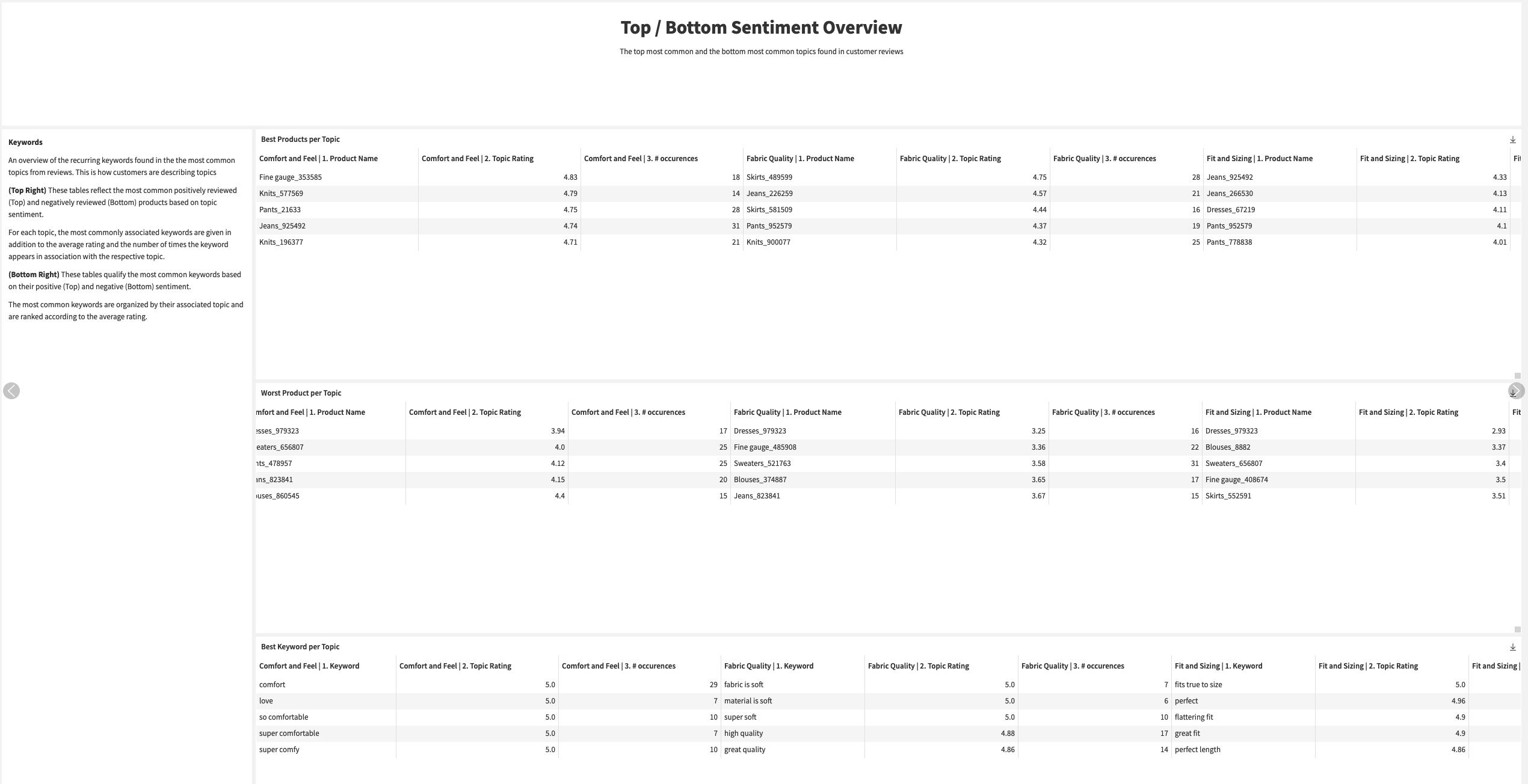
These dashboards also allow a deeper exploration of the topics. You can see how often topics are mentioned in reviews and the associated sentiment with Topic & Occurrences.
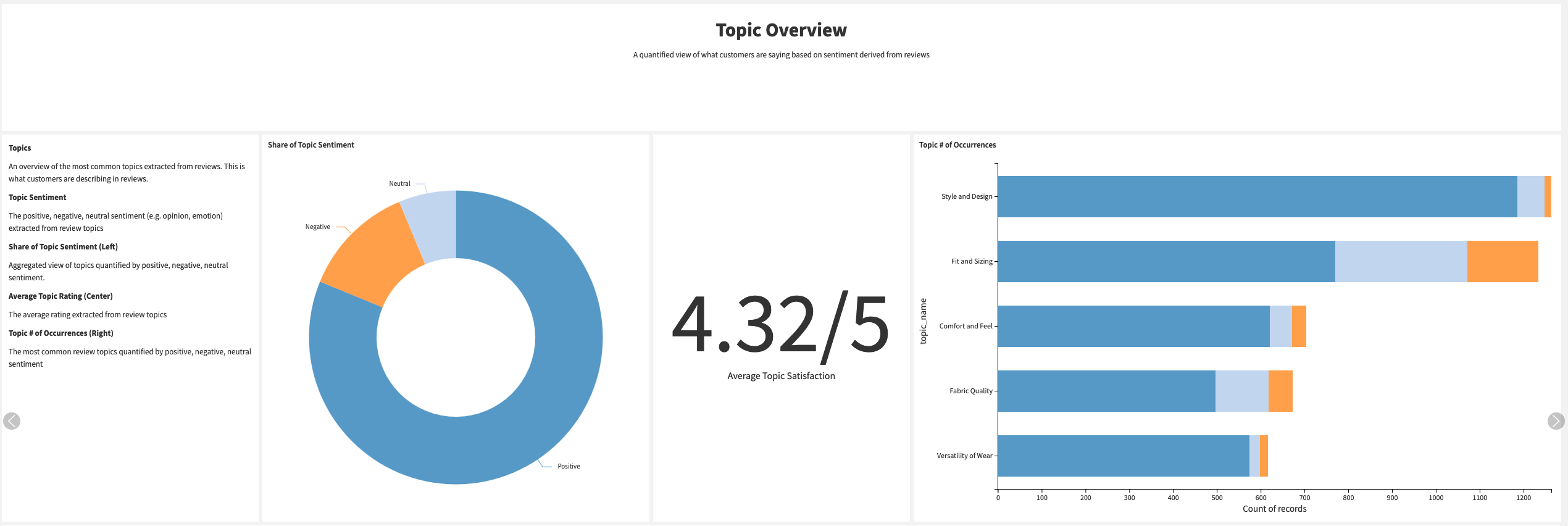
You can explore which products are best/worst rated across the different issues and identify the common keywords associated with the positive and negative sentiment in reviews. This will help highlight clear issues with specific products. With this information, you can identify which product to focus on and how to improve customer satisfaction.
Working with LLMs#
Working with LLMs is an opportunity but requires specific attention. Please be mindful about cost, privacy, and regulatory concerns. You should also use a small sample of data for testing to avoid unpredicted behavior and limit the cost of iteration. You might need to modify prompts regarding your data or the model used. Lastly, we recommend a human-in-the-loop process before taking any actions based on results that rely on LLMs (directly or indirectly).
Reproducing these processes with minimal effort for your data#
This project equips marketing and customer success teams to understand how they can use Dataiku to fully view customer sentiment toward their products.
By creating a singular Solution that can benefit and influence the decisions of various teams in a single organization, you can design smarter and more holistic strategies to optimize customer retention, improve products, make smarter inventory decisions, and adapt marketing strategies.
This documentation has provided several suggestions on how to derive value from this Solution. Ultimately however, the “best” approach will depend on your specific needs and data. If you’re interested in adapting this project to the specific goals and needs of your organization, Dataiku offers roll-out and customization services on demand.