
Solution | Clinical Site Intelligence#
Overview#
Business case#
Clinical trial research and operations are among the most expensive and time-consuming components of the therapeutic lifecycle, spanning from discovery to regulatory submission. A compound entering phase I of clinical trials historically has a 10% success rate. Pivotal efficacy studies (phase III) have a median cost of nearly USD$50 million and a per-patient enrolled cost of over USD$40K [1]. These estimates vary by therapeutic area, complexity of the drug, or mechanism of action. The total costs of clinical trials can be upwards of USD 200 million.
The cost burden stems from two driving components:
The number of patients needed to enroll
The number of sites and site visits required to prove treatment efficacy (per protocol).
Studies show that more than 80% of trials require study timeline extensions or additional study sites due to low enrollment rates. This is also the leading cause of trial termination [2]. A single month’s delay could translate to USD 1 million in trial costs and lost revenue due to time-to-market. Therefore, proper intelligence and selection of clinical sites capable of achieving enrollment goals are essential for a new study protocol.
Dataiku’s Clinical Site Intelligence Solution leverages ClinicalTrials.gov’s database of nearly 500k global studies to:
Predict study enrollment rates.
Discover similar studies based on a novel study synopsis and patient criteria.
Provide analytics on the clinical sites used in those studies.
Sponsor dashboards also provide overviews of studies, intelligence on competing sponsors and sites, and augmented social factors and disease prevalence at site locations to facilitate site review and selection that encourages participant diversity.
Installation#
From the Design homepage of a Dataiku instance connected to the internet, click + Dataiku Solutions.
Search for and select Clinical Site Intelligence.
If needed, change the folder into which the Solution will be installed, and click Install.
Follow the modal to either install the technical prerequisites below or request an admin to do it for you.
Note
Alternatively, download the Solution’s .zip project file, and import it to your Dataiku instance as a new project.
Technical requirements#
To use this Solution, you must meet the following requirements:
Have access to a Dataiku 14.6+* instance.
To access ClinicalTrial.gov through an API service, it’s currently not required to have an API key.
A Python 3.9 code environment named
solution_clinical-site-intelwith the following required packages:
Flask==3.0.2
scikit-learn==1.4.0
faiss-cpu==1.7.0
python-dotenv==0.19.0
dataiku-api-client>=11.0.0
tqdm==4.66.1
transformers==4.24.0
torch==2.0.1+cu117
--find-links https://download.pytorch.org/whl/torch_stable.html
sentencepiece==0.2.0
git+https://github.com/dataiku/solutions-contrib.git#egg=webaiku&subdirectory=bs-infra
The code environment also requires an initialization script. Users should place the following script in the Resources tab.
from dataiku.code_env_resources import clear_all_env_vars
from dataiku.code_env_resources import set_env_path
from dataiku.code_env_resources import grant_permissions
import os
clear_all_env_vars()
# Shared resource root for this code env
set_env_path("HF_HOME", "huggingface")
hf_home = os.getenv("HF_HOME")
from transformers import AutoTokenizer, AutoModel
# Pre-download into the code env resources cache
AutoTokenizer.from_pretrained("DataikuNLP/paraphrase-multilingual-MiniLM-L12-v2", cache_dir=hf_home)
AutoModel.from_pretrained("DataikuNLP/paraphrase-multilingual-MiniLM-L12-v2", cache_dir=hf_home)
AutoTokenizer.from_pretrained("emilyalsentzer/Bio_ClinicalBERT", cache_dir=hf_home)
AutoModel.from_pretrained("emilyalsentzer/Bio_ClinicalBERT", cache_dir=hf_home)
grant_permissions(hf_home)
Container configuration is required.
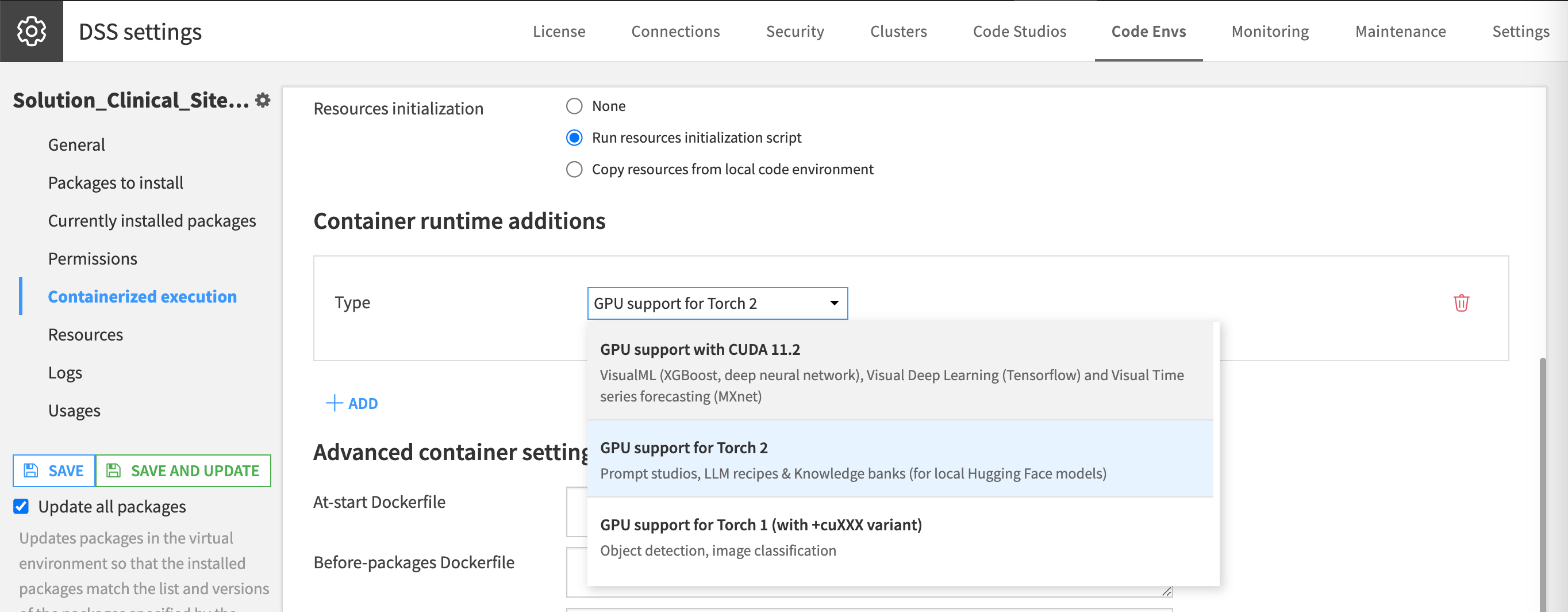
Please also include GPU support for Torch 2 for runtime if executing on Dataiku Cloud.
Data requirements#
This Solution requires a ClinicalTrial.gov API connection.
Connecting to output data from the Social Determinants of Health (SDOH) Solution is optional.
The Solution directly queries the ct.gov API, and loads the results into clinicaltrialgov_dataset. The current API version doesn’t require API keys for connection. The Solution inherits the data schema directly from the ct.gov API.
The Solution can opt-in US county-level census data and geography information from two data frames of the SDOH Solution: SOL_new_measure_final_dataset_county & SOL_tl_2020_us_county provides. The current version bundles the two data frames as part of the Solution, and so installing the SDOH Solution in advance is unnecessary.
Workflow overview#
You can follow along with the Solution in the Dataiku gallery.
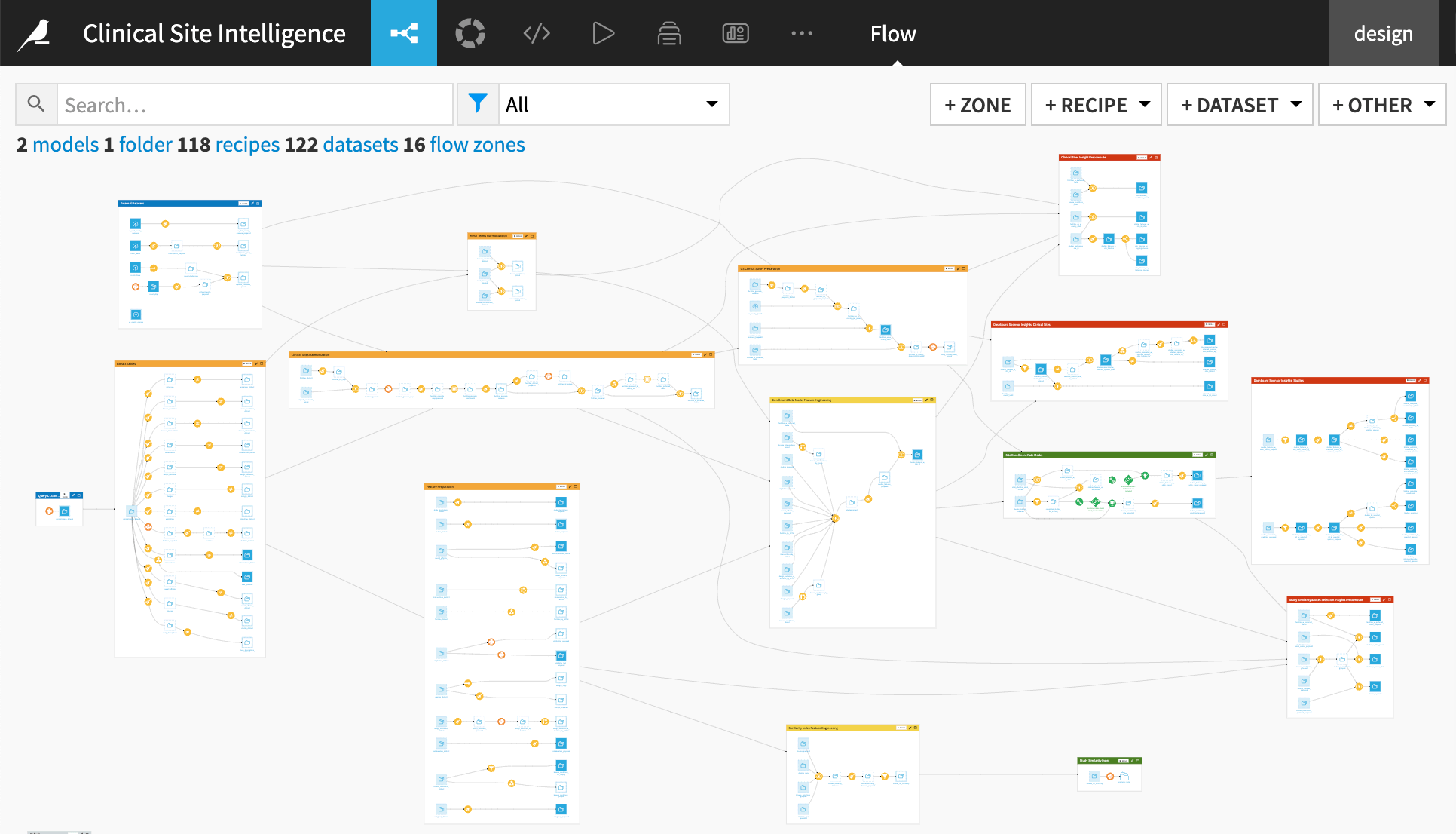
The project has the following high-level steps:
Query the ct.gov API, and extract the latest clinical trials registry data.
Run automatic pipelines of data cleaning, harmonization, and feature engineering.
Create an enrollment rate model and study the similarity index for intelligence.
Pre-compute data frames for the Clinical Site Intelligence webapp. The webapp provides interactive intelligence for study similarity analysis and site scorecards.
Create a sponsor dashboard to understand study characteristics and SDOH information.
Walkthrough#
Note
In addition to reading this document, it’s recommended to read the wiki of the project before beginning to get a deeper technical understanding of how this Solution was created and more detailed explanations of Solution-specific vocabulary.
Solution set-up via Dataiku app#
You must use a Dataiku app to set up the Solution and provide users with access to its prebuilt dashboards and webapp.
To begin, you’ll need your own instance of the Dataiku app associated with this Solution.
From the waffle (
 ) menu of the Design node’s top navigation bar, select Dataiku Apps.
) menu of the Design node’s top navigation bar, select Dataiku Apps.Search for and select the application with the name of this Solution.
Then, click Create App Instance.
The Dataiku App will create a new instance of the parent project, which you can configure to suit your specific needs. It will help you connect to your data regardless of the connection type and configure the Flow based on your parameters. You can make as many instances as needed (for example, if you want to apply this Solution to other data).
Connection configuration#
Within the Dataiku app, select the preferred connection for the data frames and folders, respectively, where you want to build. The optimal engine will apply to the recipes within the Flow.
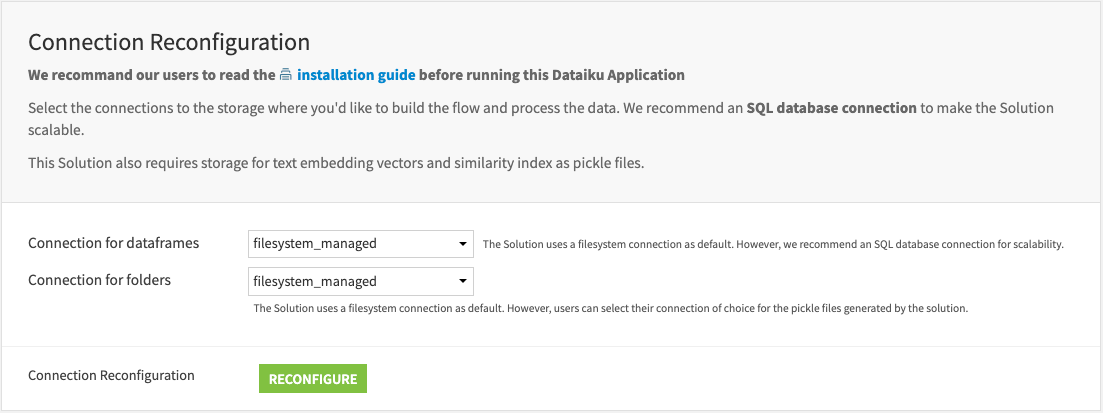
Tip
Select Snowflake or filesystem for data frames connection and filesystem for folder connection.
We recommend an SQL database (Snowflake) connection because it makes the Solution more scalable. This Solution saves the text embedding vectors and similarity index as pickle files in folders.
Define study scope#
This section defines the customized query to ClinicalTrials.gov API. In other words, the customized query establishes the scope of the clinical trials that feed into the intelligence of this Solution. The query convention follows the API documentation.
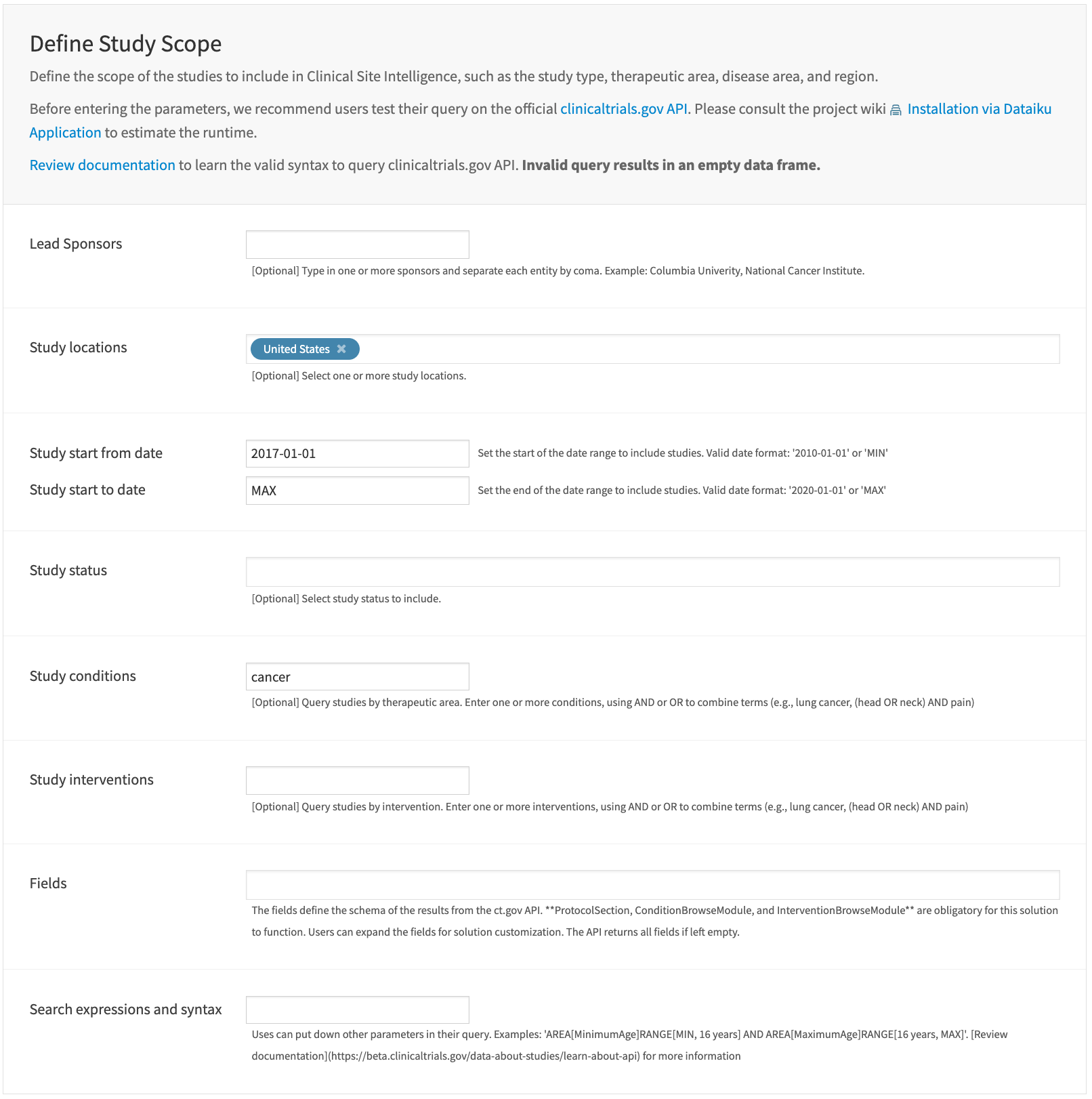
Include the demographic and social determinants of health factors (optional)#
If included, this optional dataset augments the prediction model for study enrollment rate and clinical site intelligence. The current release is limited to the SDOH data of US counties.

Read the SDOH Solution wiki for more information.
Build the Flow#
The Dataiku app will run all pipelines and create all models in the Solution with the above configuration. The pipelines include direct queries to the ct.gov API, data cleaning, harmonization, feature engineering, model building, and dataset pre-computation for the webapp.
The Flow creates multiple machine learning algorithms to power the study similarity analysis and clinical site intelligence. The enrollment rate model and study similarity index offer study and clinical site insights through interactive visualization via a webapp and dashboard.

Launch the webapp#
Launch the Clinical Sites Intelligence webapp to review insights from study similarity analysis and clinical site intelligence.

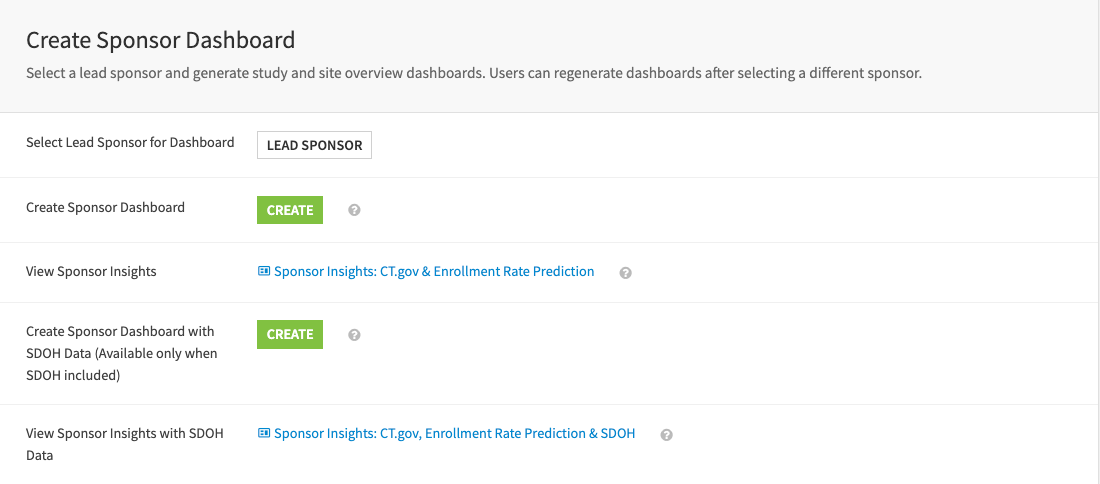
Create the sponsor dashboard#
Create a sponsor dashboard to overview studies and sites sponsored by a selected lead sponsor. The dashboard includes three components: Studies Overview, Clinical Sites Overview, and Social Determinants of Health on Sites.
The first page provides study summaries from the ClinicalTrials.gov API and augments the insights with study enrollment rate prediction.
The second page summarizes broader study activity and history across sponsors at clinical sites used by the selected sponsor of interest.
The last page reveals the locations of facilities (sites) used for studies by the chosen sponsor, with census county populations and social vulnerability information. It’s only available if users include the SDOH dataset during the build in the Dataiku app.
Caution
Including SDOH data will result in a different dashboard. Sponsor Insights: CT.gov, Enrollment Rate Prediction & SDOH is only available if you have opted in to SDOH data. Otherwise, users should use Sponsor Insights: CT.gov, Enrollment Rate Prediction instead.
Webapp: Study similarity and clinical site intelligence#
The Study Similarity & Clinical Site Intelligence webapp is an interactive interface that enables users to query clinical site intelligence using study protocols. It distills the operational history of similar studies and associated clinical sites, presenting insight in charts.
Users initiate the webapp by providing a study protocol and can interact with each step/component. Finally, users can export the list of selected clinical sites in the last step of the webapp for further analysis.
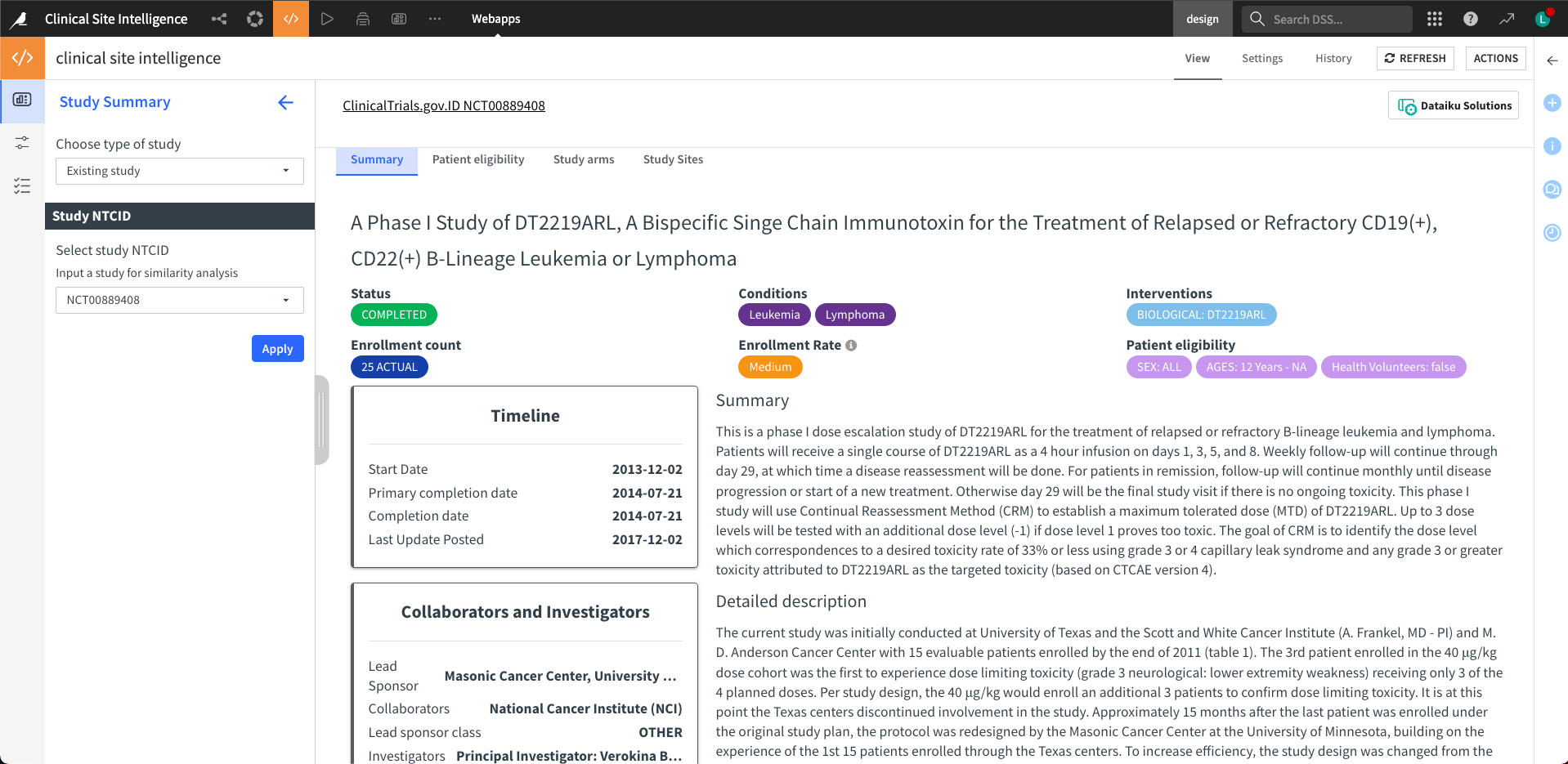
Step one: Study summary#
Users always start a query from the first tab. There are two ways to initiate new queries: input an existing study or a novel study protocol.
When choosing the existing study option, users must input a valid National Clinical Trial (NCT) identification number. Users will fill in a self-defined study protocol for the novel study option as a query. The novel study input field includes study title, study summary, cohort age, sex, inclusion and exclusion criteria, healthy volunteers, and MeSH conditions.
After submitting the query, the right main panel will display the study summary results. The webapp divides the summary into separate tabs at the top of the panel. There are four tabs: Summary, Patient Eligibility, Study Arms, and Study Sites—the webapp returns all four tabs for existing studies and the first two for novel studies.
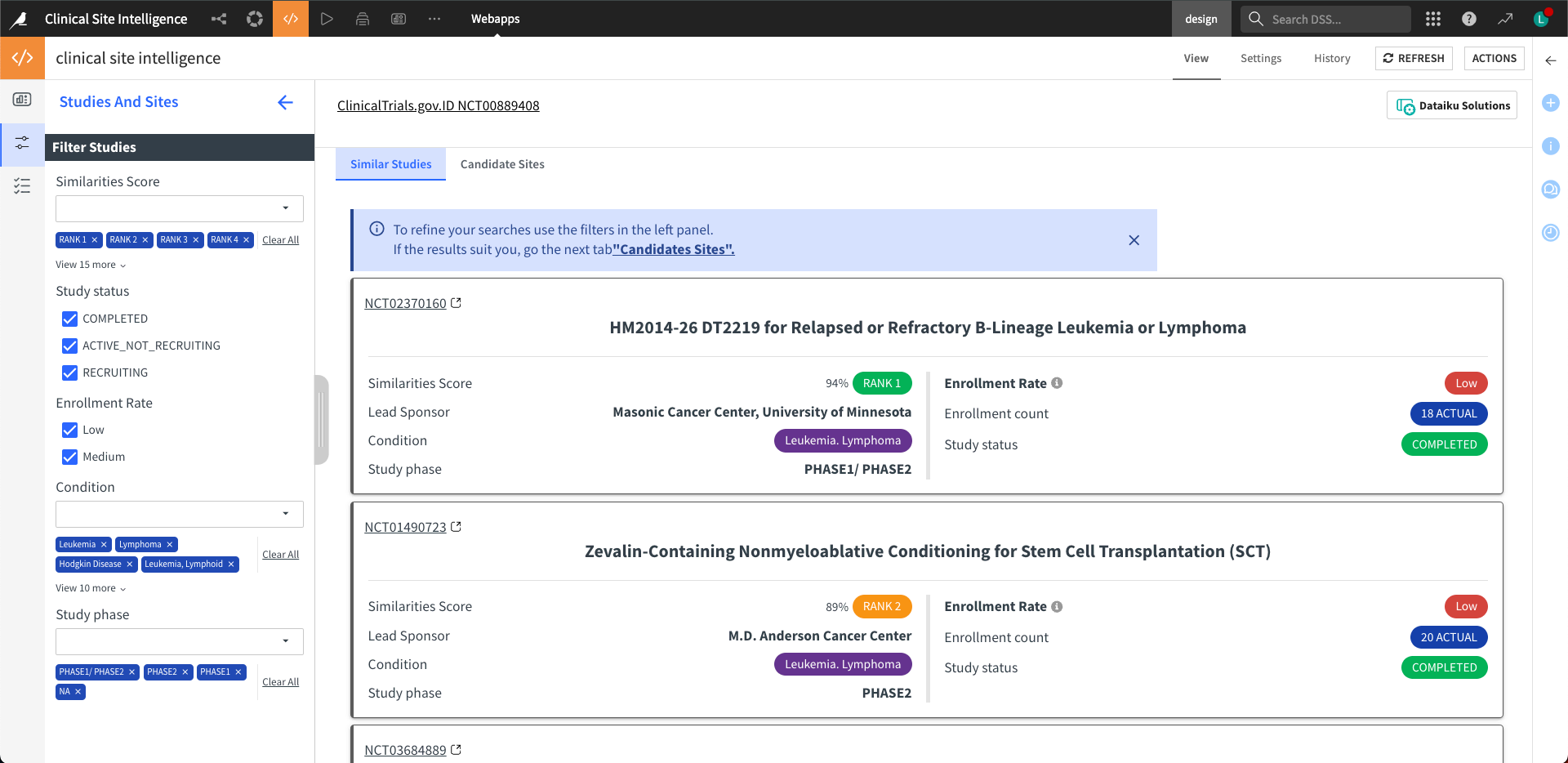
Step two: Studies and sites#
The webapp queries the study similarity index prebuilt by the Dataiku app for a given study protocol. It returns the top 20 similar study protocols. Then, it identifies clinical sites recruited by these top similar studies. It shows the results in two tabs: Similar Studies and Candidate Sites.
The left panel of both tabs serves as a filter, allowing users to select or deselect studies or sites. The filter for the Similar Studies tab will regenerate the list of locations in the Candidate Sites tab. Meanwhile, the filter for the Candidate sites tab will pass on to generate the site scorecards in step three.
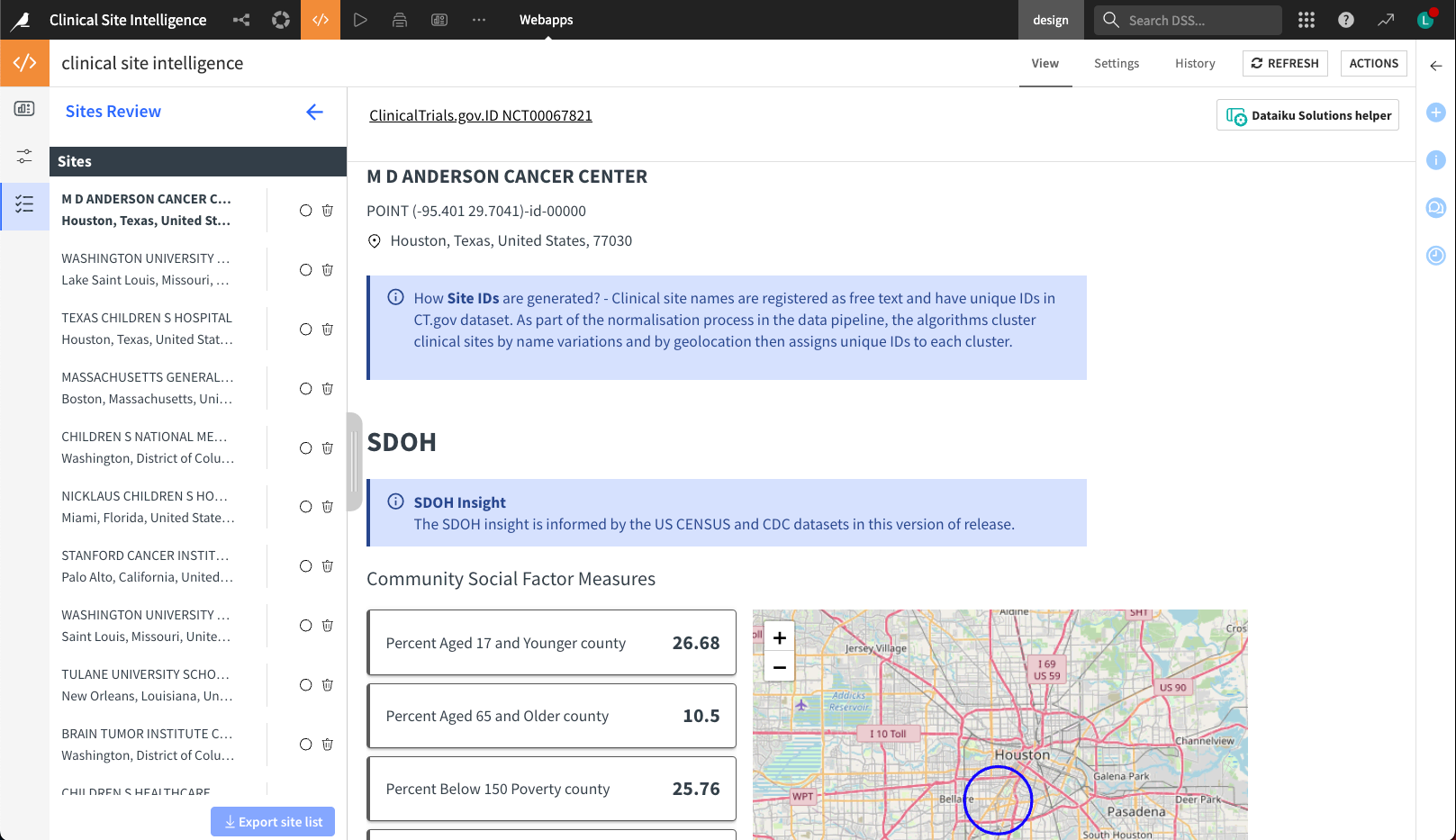
Step three: Site score cards#
The Site Score Card provides visualized insights into individual clinical research sites, including geolocation, SDOH, studies involved, and competing sponsors. The left panel logs the users’ review history on the list of candidate sites and allows users to drop locations. Finally, the user can export the finalized list for further analysis.
Dashboard: Sponsor dashboard#
The Sponsor Insights dashboard provides an overview of clinical trials and clinical research sites sponsored by a selected lead sponsor. The dashboard has two versions, depending on the Dataiku app configuration: Sponsor Insights with SDOH if the setting includes the SDOH dataset option, and Sponsor Insights otherwise.
Studies Overview
Clinical Sites Overview
Census Social Factors and CDC Chronic Disease Prevalences at Site Locations
Studies overview#
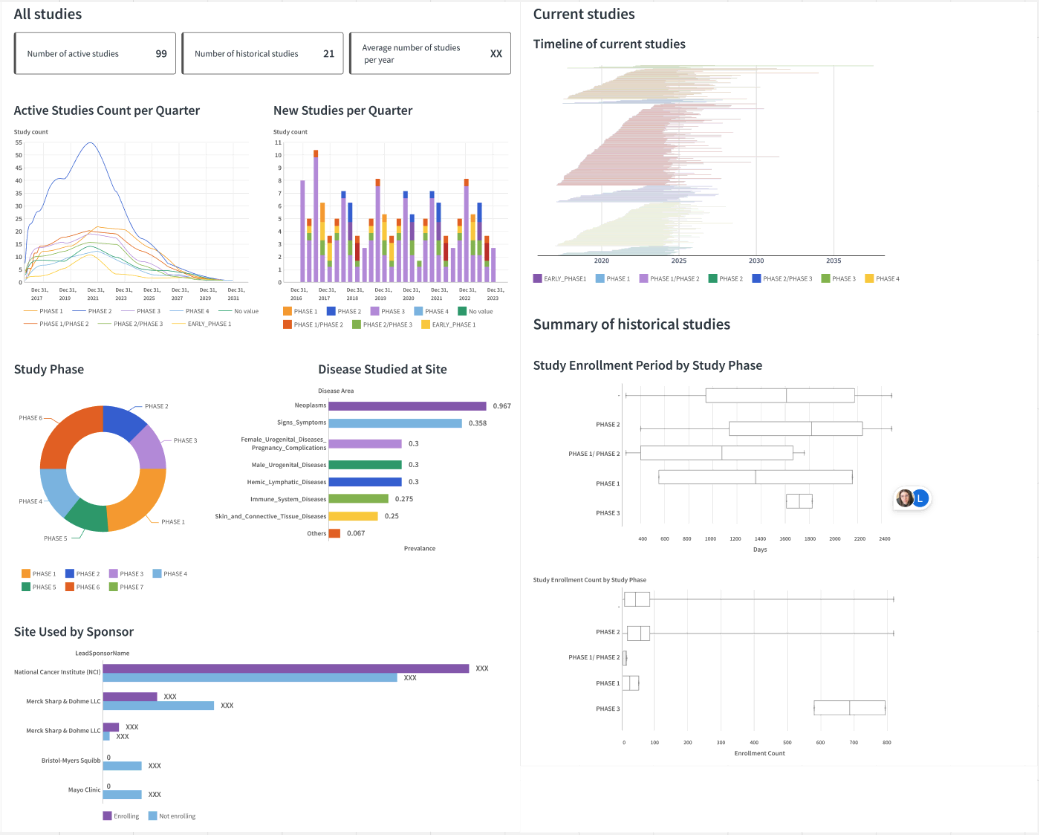
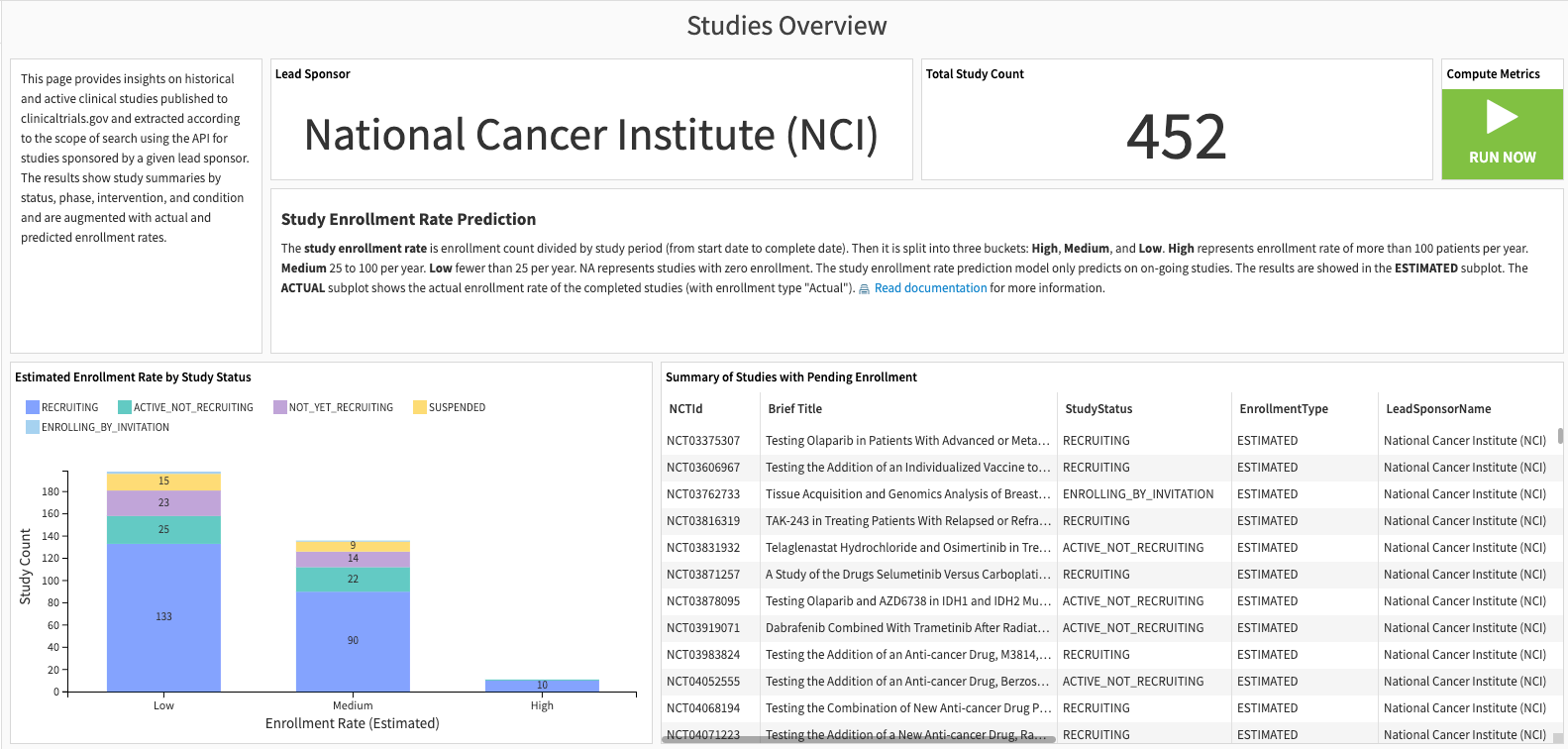
The first slide provides the most up-to-date information from the clinicaltrials.gov dataset. This Solution augments the intelligence with study enrollment rate prediction for ongoing studies. This section has two parts: study enrollment rate prediction and study characteristics.
The enrollment rate model uses study protocols and SDOH (optional) as features. The random forest model predicts the likelihood of having a high, medium, or low enrollment rate for a given study protocol. The study enrollment rate is calculated by dividing the enrollment count by the study period (from start to completion). Then, it’s categorized into three buckets:
High: more than 100 patients annually.
Medium: 25 to 100 per year.
Low: fewer than 25 per year.
NA represents studies with zero enrollment.
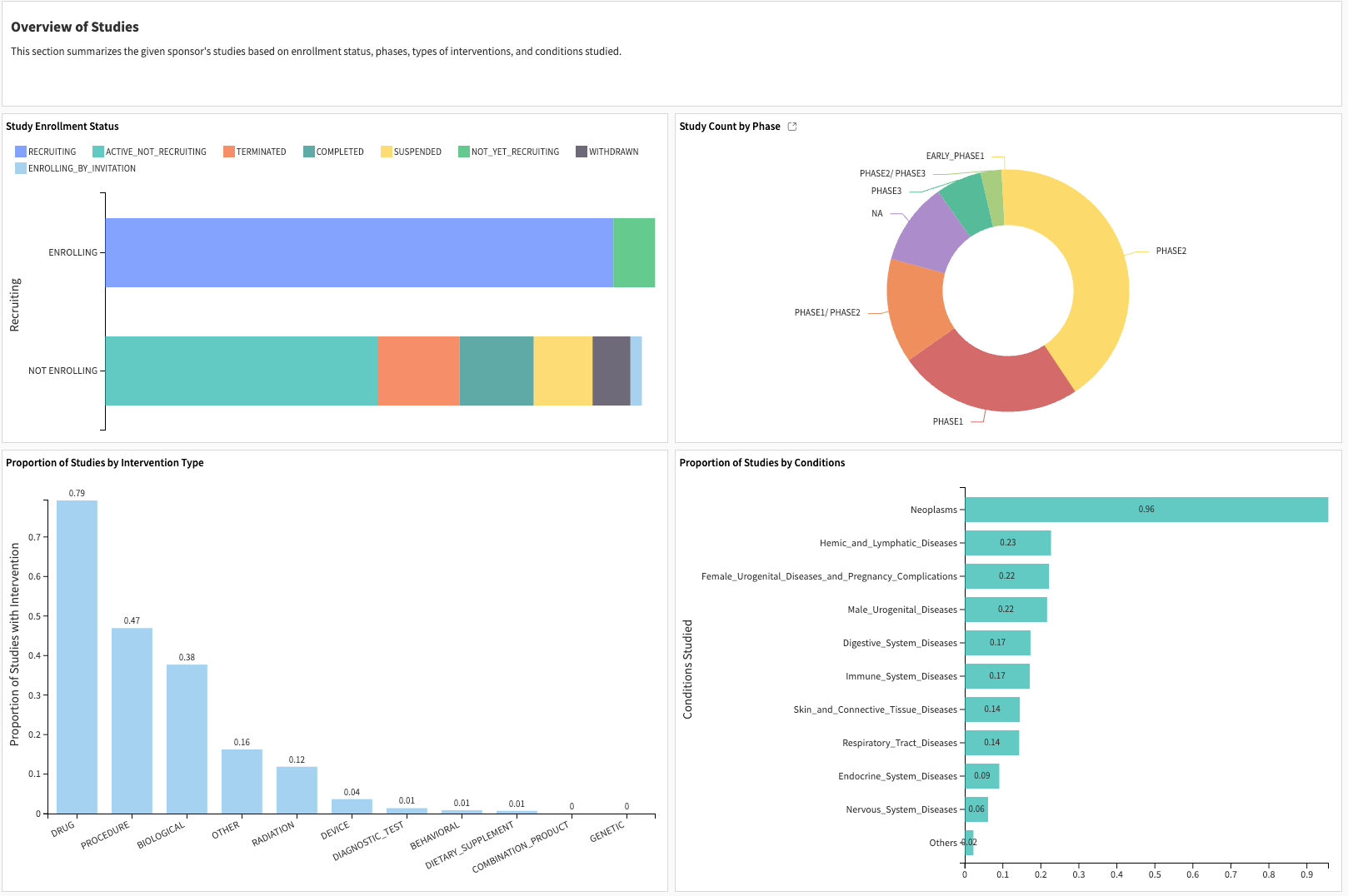
The study characteristics represent the enrollment status, study phases, percentage of studies in the therapeutic area, and intervention domain.
Sites overview#
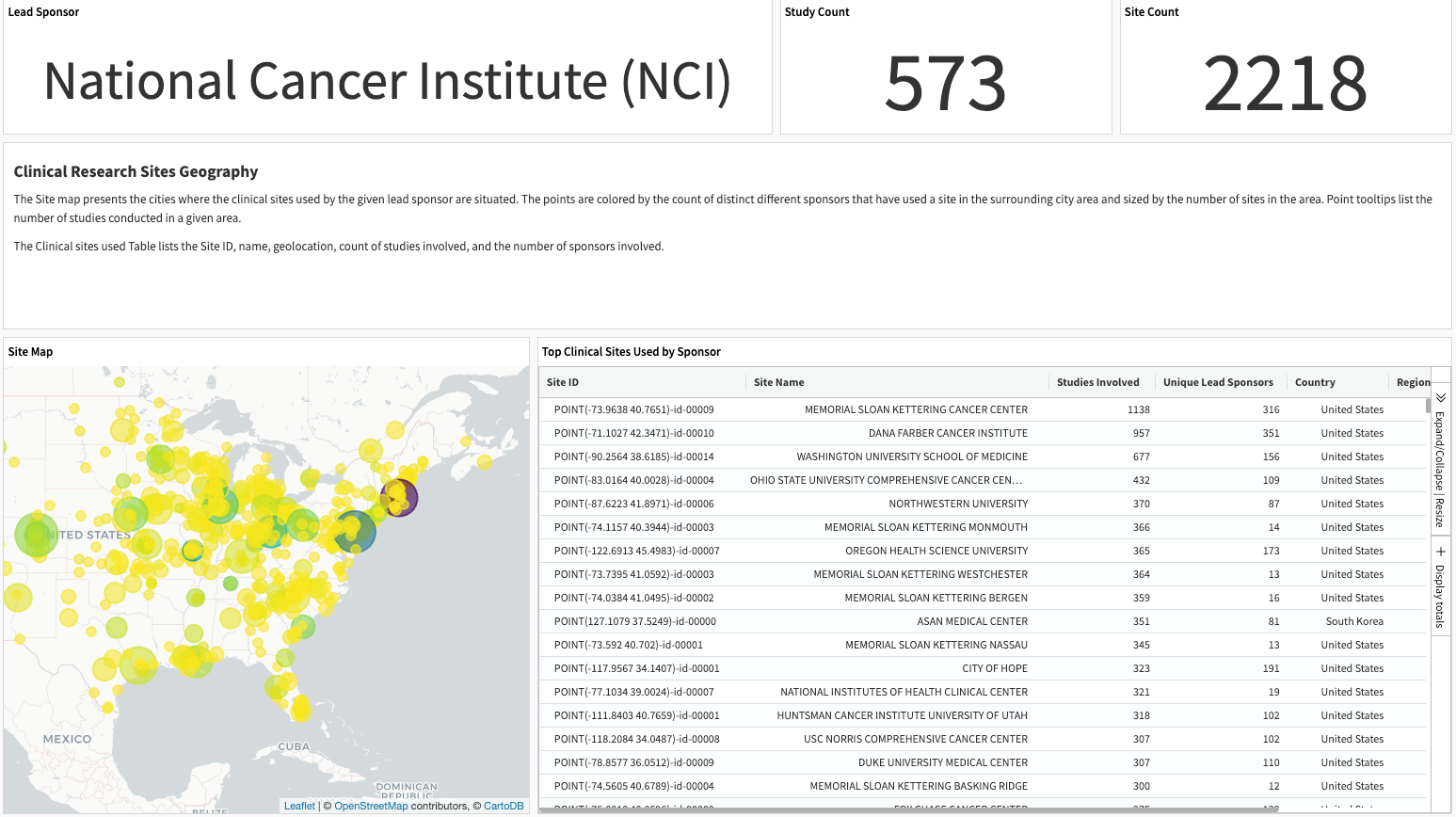
This slide summarizes broader study activity and history across sponsors sourced from clinicaltrials.gov at clinical sites used by the selected sponsor of interest.
The site map displays the number of research sites and competing sponsors for each city that a selected sponsor uses. The Table of Clinical Sites Used lists the Site ID, name, geolocation, count of studies, and sponsors involved.
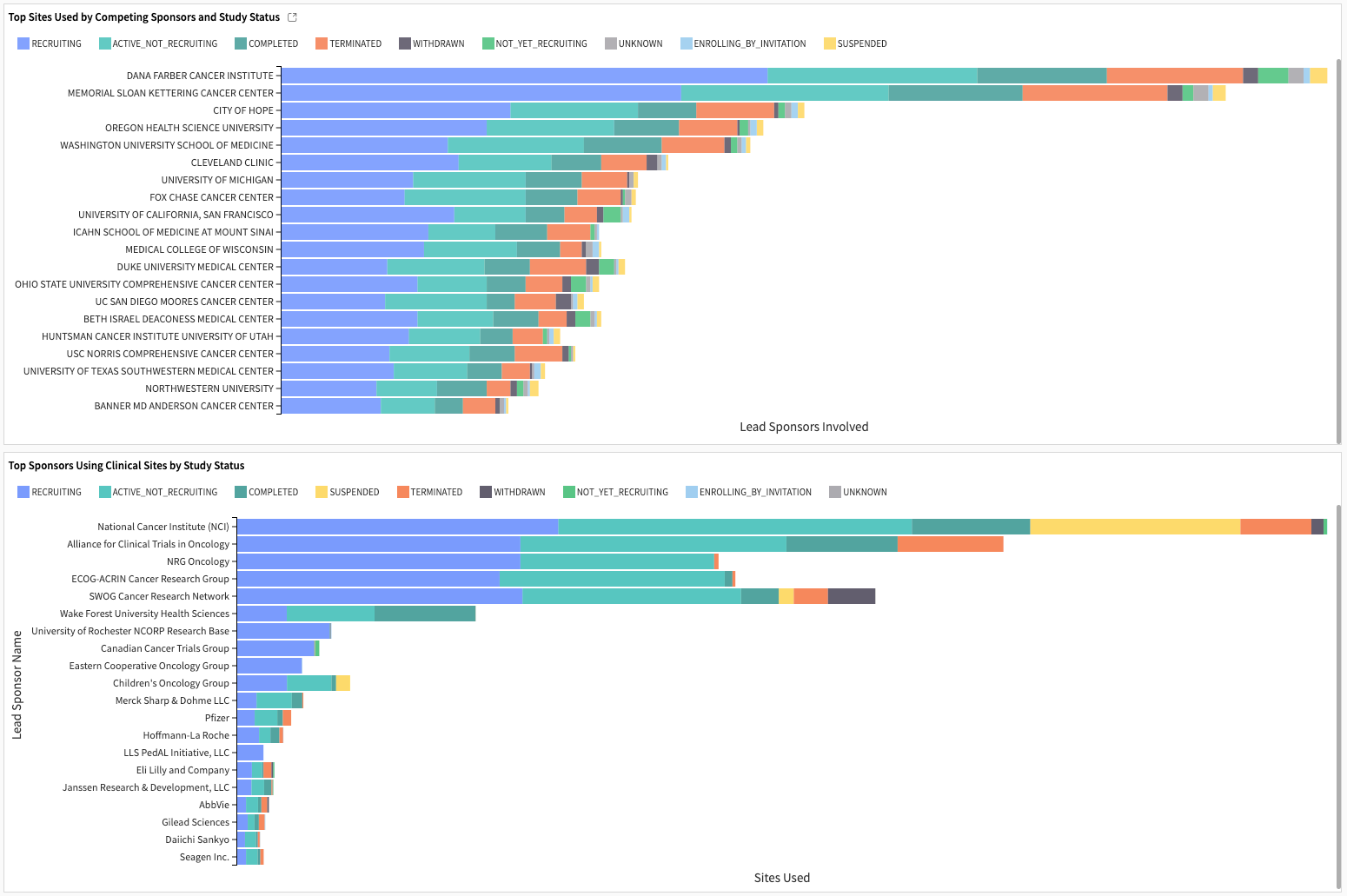
The competitiveness analysis examines the utilization of clinical sites by other sponsors. The Top Sites Used by Competing Sponsors and Study Status show the clinical sites’ records of involvement in other studies sponsored by other lead sponsors. The Top Sponsors Using Clinical Sites by Study Status indicates the number of clinical sites that a given lead sponsor competes against the selected sponsor.
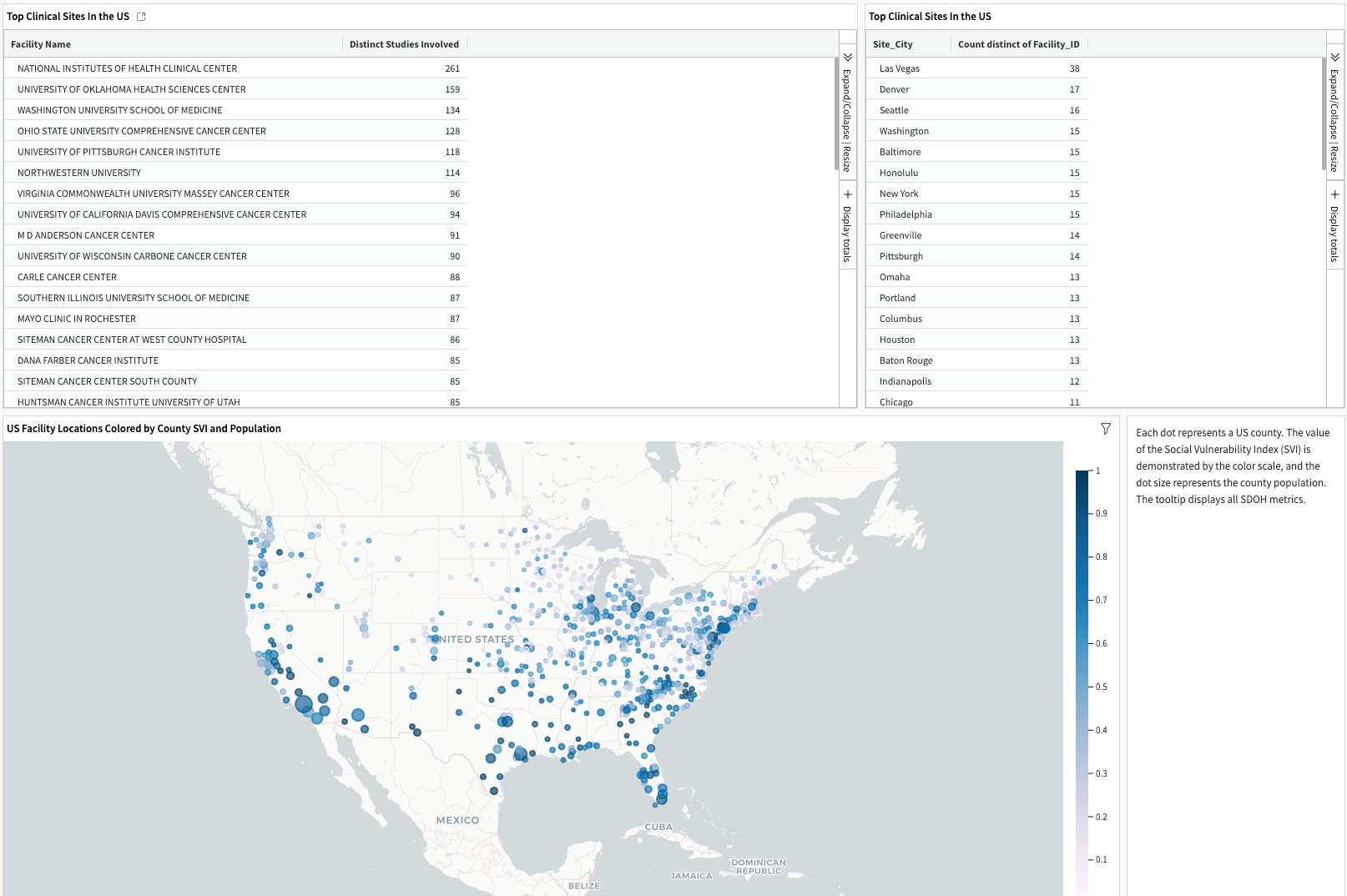
Census social factors and CDC chronic disease prevalence#
This slide displays the locations of facilities (sites) used for studies by the selected sponsor with CENSUS county populations and Social Vulnerability information. It’s only available if the SDOH dataset is included during the build-up in the Dataiku app. The current version is limited to the USA census data.
Responsible AI statement#
This Solution utilizes analytics and ML-driven insights to inform clinical site recruitment by study protocol design. However, it’s crucial to be mindful of inequality in the recruitment of human subjects in the history of clinical research. The patient enrollment process often under-represents communities with a particular sex, gender, minority/ethnic background, and health conditions. A data-driven approach will inevitably inherit these biases from the clinical trial registry. It’s essential to consider these potential data biases when interpreting any results.
The Solution also augments clinical site intelligence with US SDOH insights to encourage recruitment diversity. It’s derived from community-level survey data. Organizations shouldn’t use it to support misleading attribution on how a person’s socioeconomic status, minority/ethnic background, and household situation predict or inform potential disease occurrence or outcomes. Self-reported survey data are particularly susceptible to recall bias, social desirability bias, and non-response bias. Any decisions or actions based on this analysis must consider these limitations, which may influence the distribution of the data.
While leveraging disease associations with regional community-level characteristics, it’s essential to use this information to advance health equity and enhance therapeutic accessibility. Organizations should actively avoid any reinforcement or exacerbation of disparities or biases within the health and life sciences systems where this Solution is deployed.
This approach is extendable to incorporate supplementary data, including health care professional (HCP) or pharmacy geolocation information. The same applies to individual-level (de-identified) personal patient behavioral and clinical data in regions identified as potential areas of disparity.
Furthermore, any models developed for crafting personalized patient-care journeys, health outreach programs, pricing considerations, or therapeutic delivery must undergo a thorough evaluation guided by a robust and responsible AI ethics process. This process ensures the prevention of biases, consideration of all subpopulations, and the establishment of model interpretability and explainability.
See also
We encourage users to check out Dataiku’s Responsible AI course to learn more.
Reproduce these processes with minimal effort#
This project equips healthcare and life science professionals to facilitate clinical operations using public datasets with Dataiku.
By creating a singular Solution that can benefit and inform the decisions of various teams within a single organization or across multiple organizations, you can utilize immediate insights to refine clinical site recruitment strategies for drug manufacturers.
This documentation has provided several suggestions on how to derive value from this Solution. Ultimately however, the “best” approach will depend on your specific needs and data. If you’re interested in adapting this project to the specific goals and needs of your organization, Dataiku offers roll-out and customization services on demand.