
Solution | Credit Scoring#
Overview#
Business case#
Credit decision-making is the cornerstone of successful lending operations and continuously evolves with customer behavior and data availability. The complexity and depth of analysis required to offer competitive pricing and accurate prediction of credit events is ever increasing. Higher performance models demonstrably increase revenue, reduce credit loss, and improve efficiency.
Credit scorecards are a foundational part of a credit teams’ workflow. Enhancing them with more powerful data sources and faster collaborative review is vital to retaining and expanding a customer base. Existing tools can be difficult to adapt to this new environment. Future-focused approaches can often be disconnected from the current technology and needs of the team. This silos the potential benefits and prevents them from being integrated into the working model that directly impacts customers.
By leveraging Dataiku’s unified space where existing business knowledge, machine-assisted analytics (for example, automatic searching of many features and feature iterations for credit signals), and real-time collaboration on credit scorecards are unified, credit teams can immediately benefit from the value of an ML-assisted approach, establish a foundation on which to build dedicated AI credit scoring models, all while remains connected to their current customer base and systems.
Installation#
From the Design homepage of a Dataiku instance connected to the internet, click + Dataiku Solutions.
Search for and select Credit Scoring.
If needed, change the folder into which the Solution will be installed, and click Install.
Follow the modal to either install the technical prerequisites below or request an admin to do it for you.
Note
Alternatively, download the Solution’s .zip project file, and import it to your Dataiku instance as a new project.
Technical requirements#
To use this Solution, you must meet the following requirements:
Have access to a Dataiku 13.2+* instance.
Generalized Linear Models plugin
A Python 3.8 or 3.9 code environment named
solution_credit-scoringwith the following required packages:
scorecardpy==0.1.9.2
monotonic-binning==0.0.1
scikit-learn>=1.0,<1.1
Flask<2.3
glum==2.6.0
cloudpickle>=1.3,<1.6
lightgbm>=3.2,<3.3
scikit-learn>=1.0,<1.1
scikit-optimize>=0.7,<0.10
scipy>=1.5,<1.6
statsmodels==0.12.2
xgboost==0.82
Data requirements#
The project is initially shipped with all datasets using the filesystem connection. One input dataset must contain at least two mandatory columns with some additional columns to build the models. The mandatory columns in need of mapping are:
the credit event variable which should be constructed to fit the specifications of the study
the ID column a unique identifier for each applicant
Workflow overview#
You can follow along with the Solution in the Dataiku gallery.
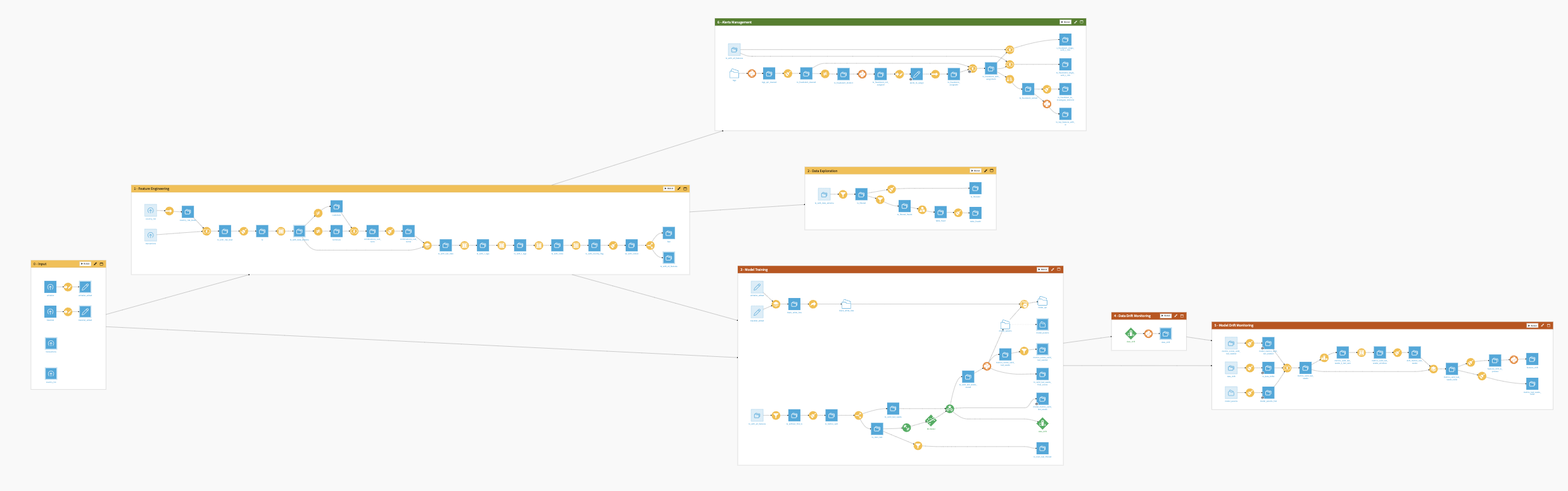
The project has the following high-level steps:
Connect your data as input and select your model parameters via the Dataiku app.
Explore your credit model with pre-built visualizations.
Understand your scorecards through the webapp through a responsible framework.
Walkthrough#
Note
In addition to reading this document, it’s recommended to read the wiki of the project before beginning to get a deeper technical understanding of how this Solution was created and more detailed explanations of Solution-specific vocabulary.
Plug and play with your own data and parameter choices#
To begin, you’ll need your own instance of the Dataiku app associated with this Solution.
From the waffle (
 ) menu of the Design node’s top navigation bar, select Dataiku Apps.
) menu of the Design node’s top navigation bar, select Dataiku Apps.Search for and select the application with the name of this Solution.
Then, click Create App Instance.
The project includes sample data that you can use to run an initial demo of the Solution. Alternatively, you should replace it with your own data. You can select a Snowflake or PostgreSQL data connection to reconfigure the Flow and app to your own data.
After selecting your connection, click Reconfigure, which will switch dataset connections on the Flow. Once the reconfiguration is complete, you can input the names of the input dataset. Click the Load button before refreshing the page to allow the Dataiku app to reflect the data accurately.
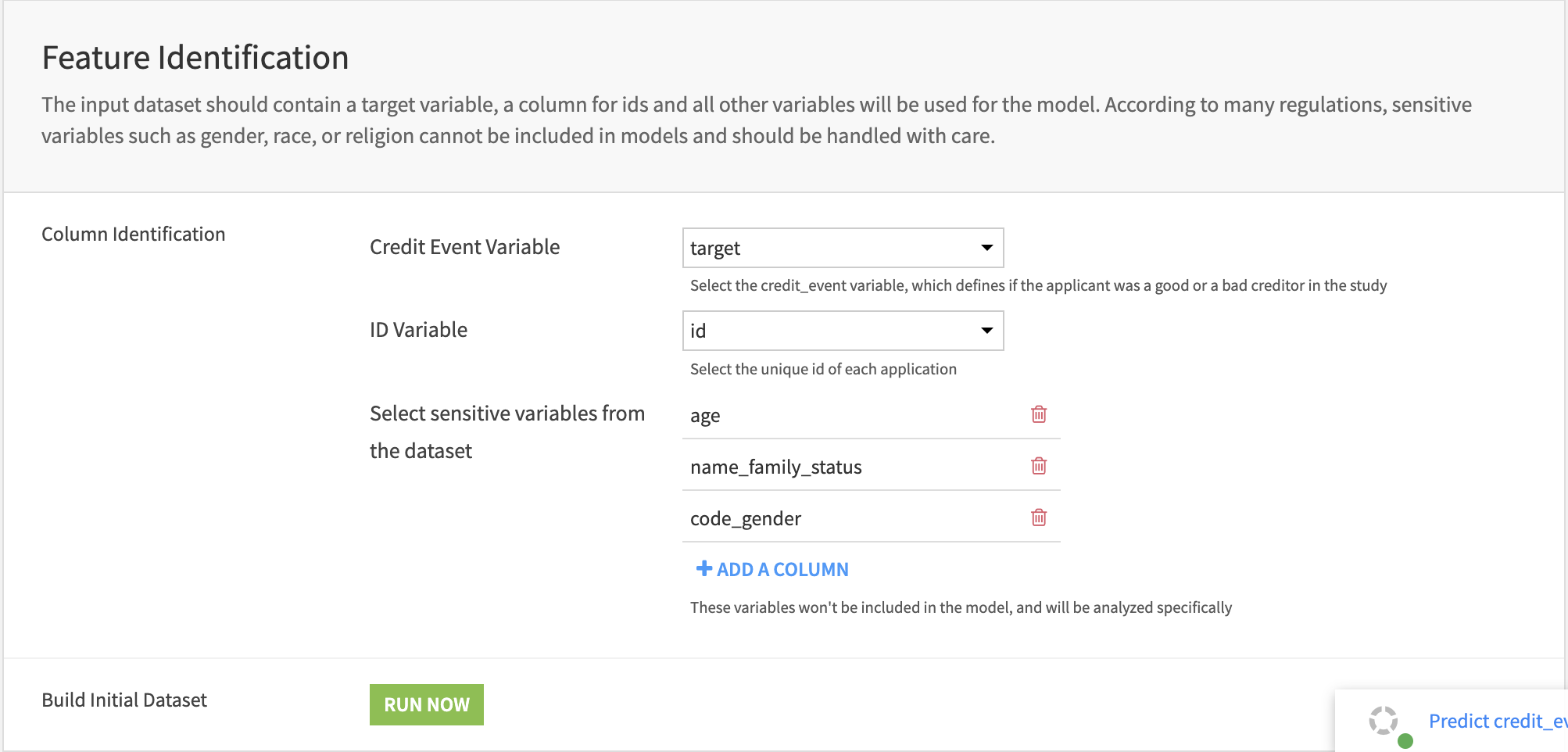
You can use the Feature Identification section to configure the two mandatory columns mentioned in the data requirements. Then, the user can select sensitive variables (which will be used as features to predict the applicant’s creditworthiness) from the dataset. They will be removed from the core analysis and analyzed specifically with the Responsible Credit Scoring Consideration.
The next step is the Feature Filtering, which takes place in two successive steps. First, the Information Value and Chi-Square p-value drive the univariate filters. The user can specify the threshold for both these metrics to discriminate between kept and discarded variables. Then, the correlation filter removes from pairs of correlated variables the ones with the most negligible information value. The user selects the correlation threshold (the absolute correlation is compared to this value) and chooses the method for computing correlation among Spearman and Pearson. The filtering occurs when clicking the Run button, which triggers the scenario.
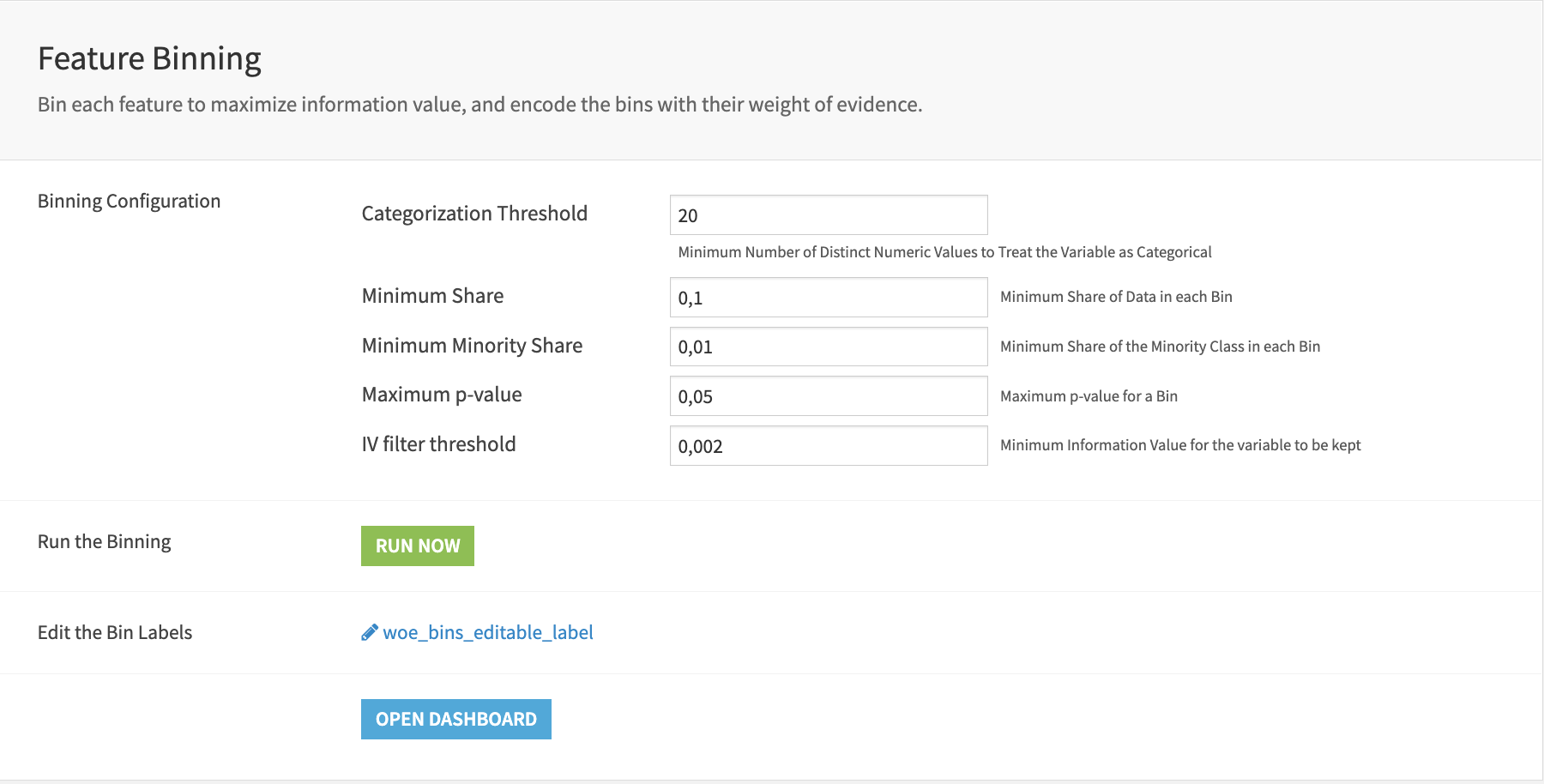
After that, Feature Binning is the next step to bin the features using the weight of evidence and encode the variables using that same metric. The run button will trigger the Bin Variables scenario, and then the user can edit the editable dataset to give more meaningful labels to the bins.
The Feature Selection is where the user can specify one of the three available methods for feature selection and the number of selected features desired in the end. The Score Card Building fits the logistic regression coefficients and defines the three parameters to scale the scorecard as desired (Base score, Base odds & Points to Double Odds). After launching the Build Score Card scenario, you can access the scorecard in the dashboard. The last step is the third scenario which updates the API and refreshes the webapp.
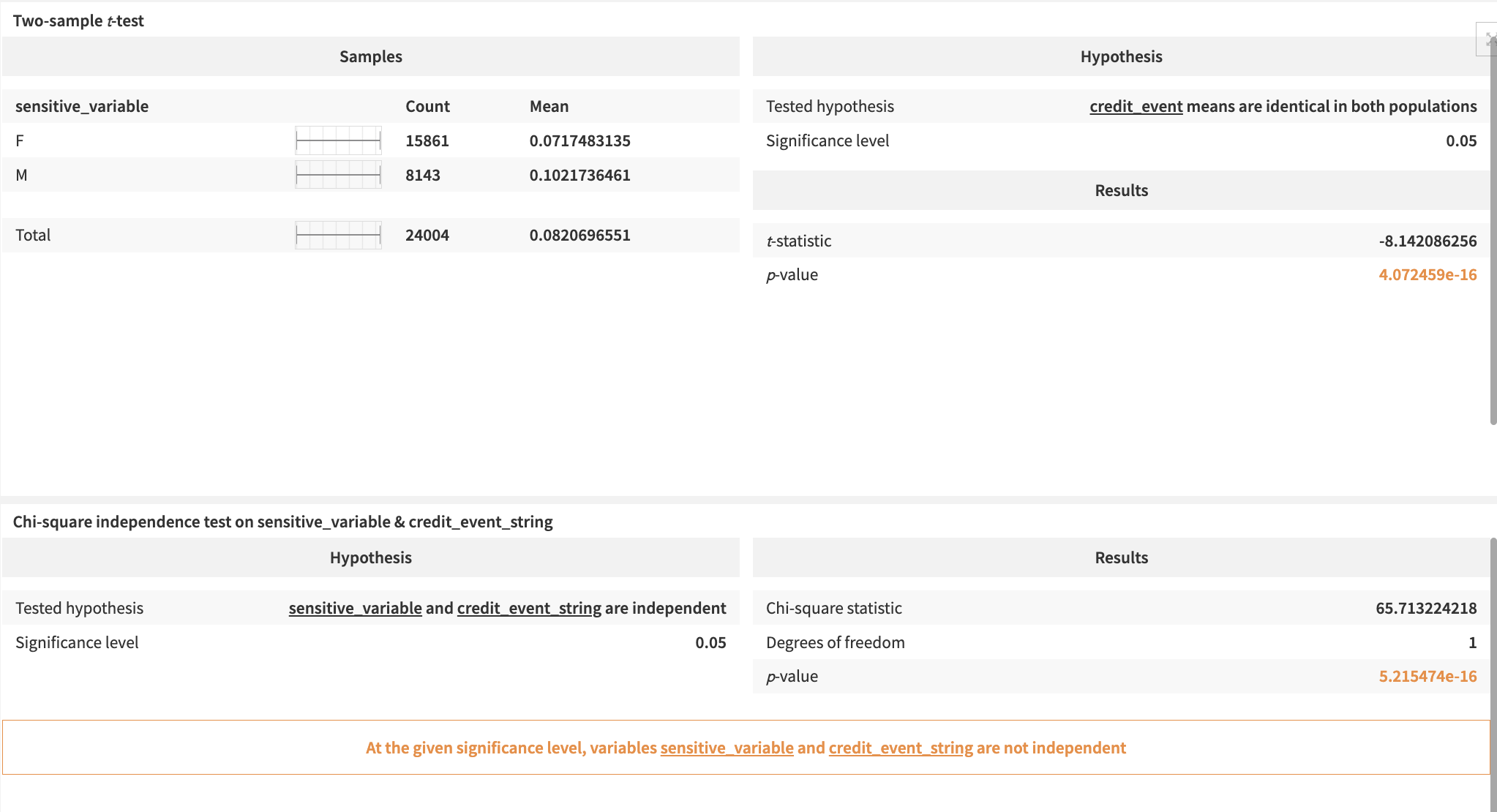
As borrowing is a key service for people in society and access to it can significantly affect one’s economic opportunities, the Solution includes a Fairness Analysis. The Solution carries out this analysis on one sensitive variable at a time. The user selects the specific sensitive variable and runs the process with the scenario Analyze Sensitive Variable.
Further explore your credit model with pre-built visualizations#
The Credit Scoring dashboard contains five pages: Feature Filtering, Feature Binning, Feature Selection, Credit Model, and Responsible Credit Scoring.
The first page Feature Filtering, contains visualizations published from the Dataiku app. The first two graphs represent the Information Value of a variable with respect to the credit event target. The higher the value, the more information is contained in the variable to explain the credit event.
The graphs below represent the Chi-Square p-value, which is similar to the above except that here, the lower, the better. The tab has a statistical card in a correlation matrix form, shown below. The user should focus on the brighter tiles, either red or blue, that indicate either significant positive or negative correlations.

The Feature Binning page contains a set of three charts. The two graphs on the right help observe the bins and their weight of evidence. To understand them, one must click on them and adjust the filters to show only one variable at a time. The third graph displays the information value after binning is plotted for each variable, and the line is the threshold for keeping a variable.
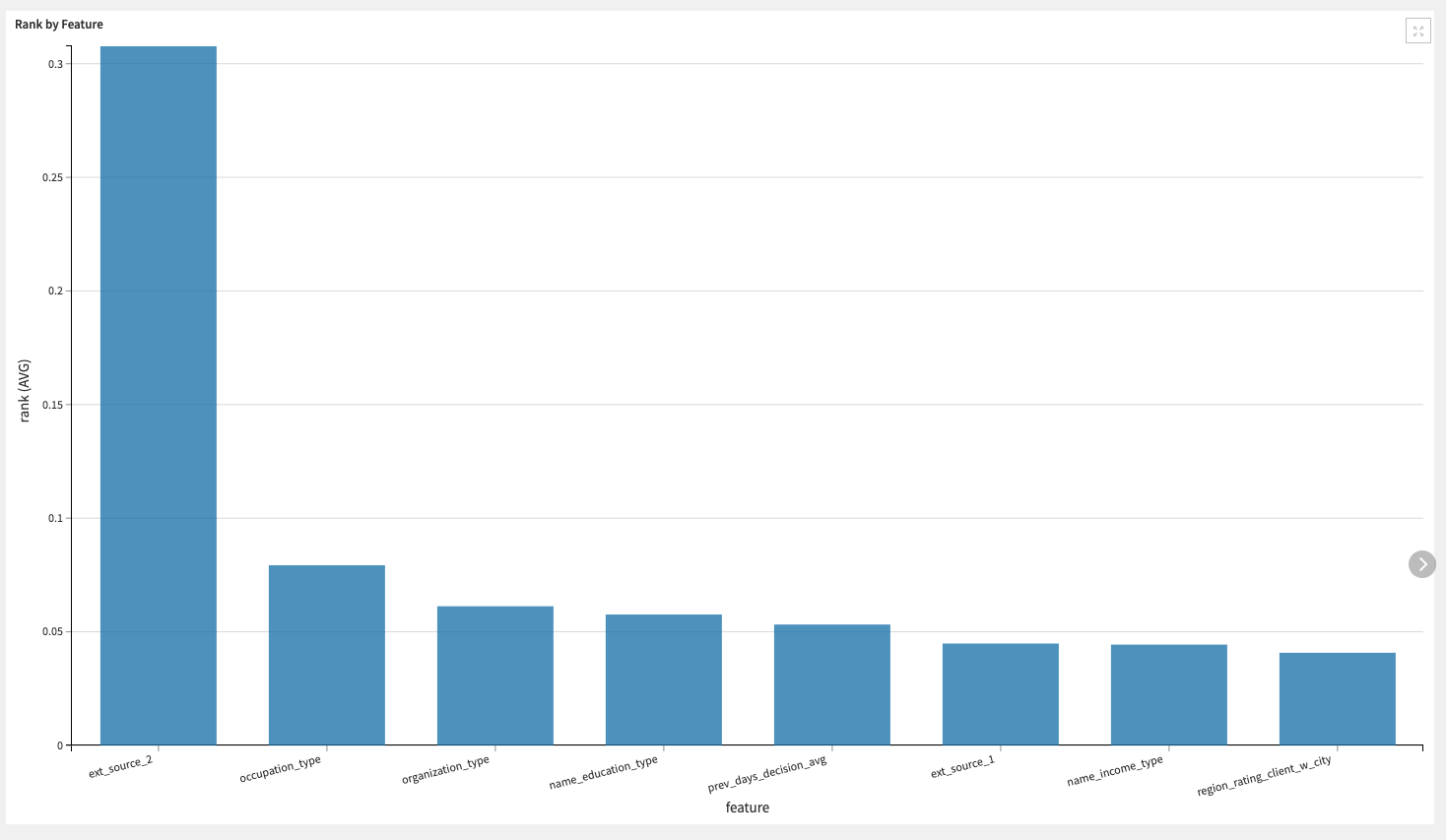
The Feature Selection is achieved using one of the three available automated feature selection algorithms selected in the Dataiku app: forward selection, lasso selection, and tree-based selection. The bar chart represents either the absolute value of the coefficients for forward and lasso selection or the feature importance for tree-based selection. It indicates the rank of each variable in the selection.
The Credit Model tab is here to help the user understand the scorecard. It’s explained in two different formats. The first is displayed as a dataset. It contains as many rows as there are bins within each selected feature. For each of these bins, the Solution pre-computes a score. The second is a chart representing the average credit event frequency per group of scores, all computed on a test dataset. Scores have been computed using the scorecard and binned to have reliable estimations of the credit event frequency within each bin.
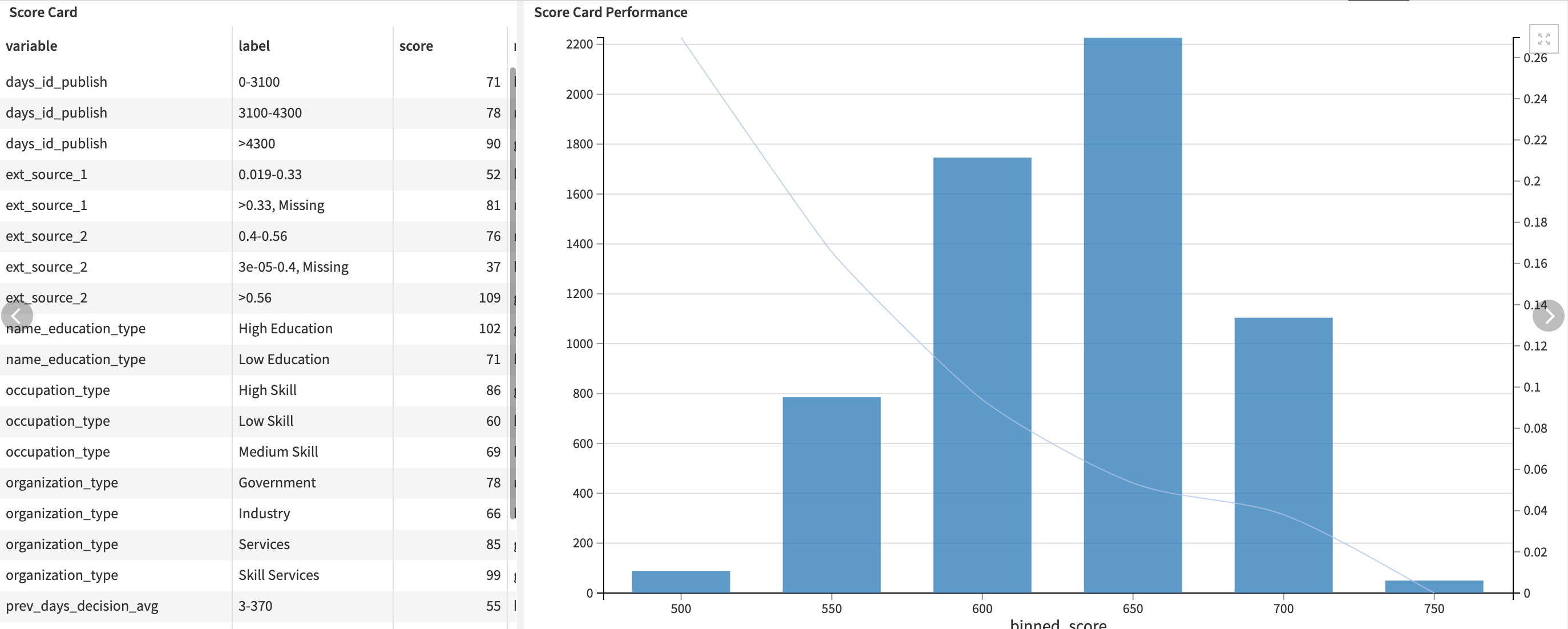
Finally, the Responsible Credit Scoring page focuses on the aspect of the project that follows the Responsible AI (RAI) framework. First, two tests check the relationship between the sensitive variable and the target. Then, the chi-square test looks at the independence of sensitive_variable and target. If they’re not independent and/or their means differ, this raises a concern about bias in the data and how it can affect populations.
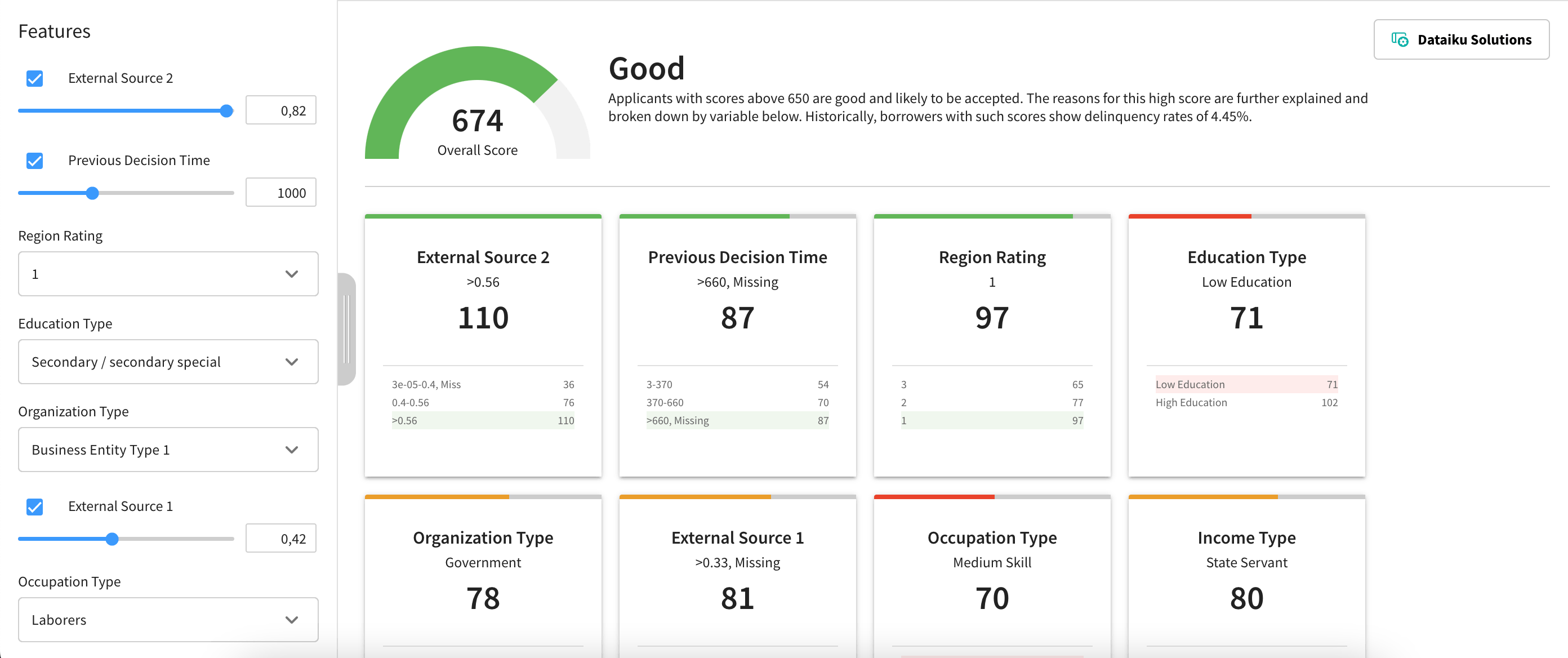
Webapp, API and responsible AI#
The webapp provides an interactive experience to navigate the scorecard. It uses the parameters defined in the Dataiku app. Users can modify input values on the left-hand side panel and visualize the results on the main screen.
For each variable, a card shows all the possible buckets a value can belong to and their corresponding number of points. The final score will be the sum of the points from each variable. Hence, depending on the number of points attributed to a variable, it might contribute positively or negatively to the final score.
The Flow exports two datasets to a CSV format to be usable in the API service. Indeed, the API is a feature that allows exposure of a model outside of the project and makes it usable. In this case, the score isn’t a direct output of the model. It outputs a prediction and a probability from the raw logistic regression. It’s the result of further computation to scale the score.
As previously mentioned, credit scoring impacts people’s lives. To fight bias, statistical techniques appear to have removed human-biased judgment in making these decisions, as the quantitative measures seem more objective. However, the ways in which you process data and design models can also create or perpetuate bias that would continue to affect some groups of people. So that’s why this project follows the Responsible AI framework developed by Dataiku.
Reproducing these processes with minimal effort for your data#
This project equips credit risk analysts to create a credit-worthiness model building scorecards using Dataiku.
By creating a singular Solution that can benefit and influence the decisions of a variety of teams in a single organization or across multiple organizations, credit teams can immediately benefit from the value of an ML-assisted approach, establish a foundation on which to build dedicated AI credit scoring models, all while remains connected to their current customer base and systems.
This documentation has provided several suggestions on how to derive value from this Solution. Ultimately however, the “best” approach will depend on your specific needs and data. If you’re interested in adapting this project to the specific goals and needs of your organization, Dataiku offers roll-out and customization services on demand.