Troubleshoot | Dataiku isn’t using the optimal engine for a visual recipe#
In the case of a visual recipe, two general causes for slow performance are using an inefficient execution engine or using data formats that don’t allow for the most optimal execution engine.
Inefficient execution engine#
Let’s say you are trying to join a local filesystem dataset with a PostgreSQL dataset. To use the more optimal “In-database (SQL)” engine, you can sync your filesystem dataset to a PostgreSQL dataset, so that both of your input datasets are in PostgreSQL.
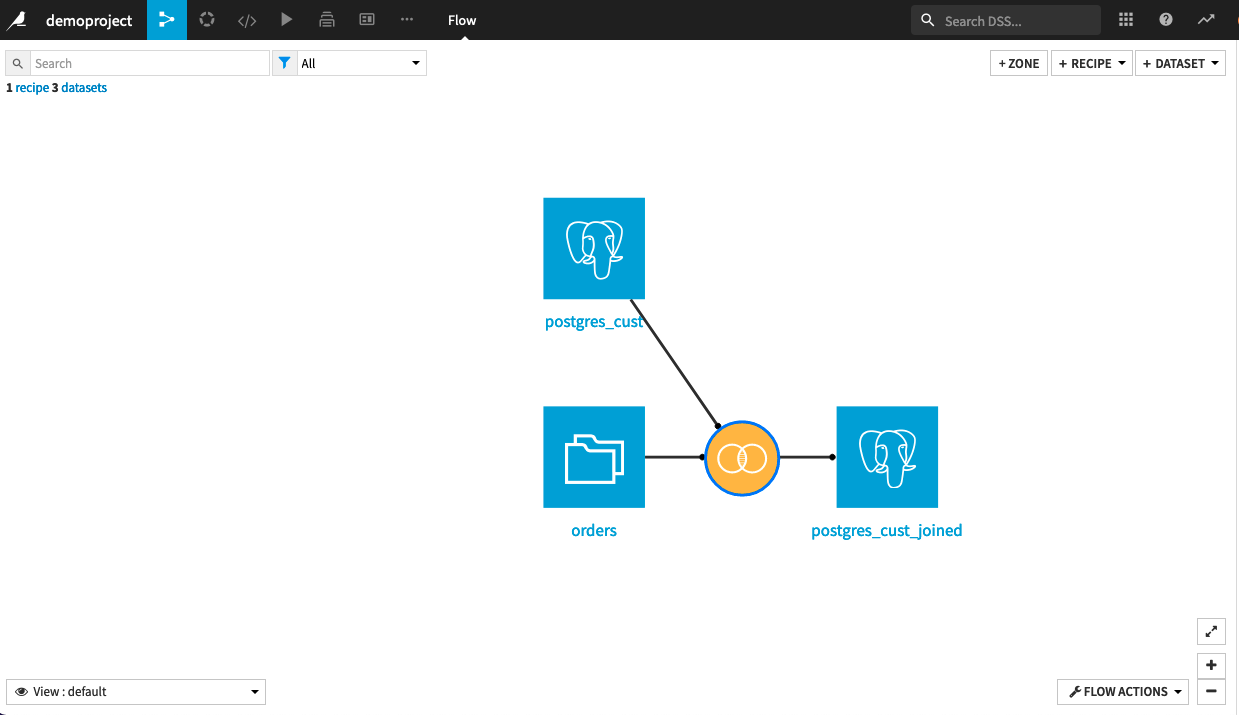
Let’s imagine that this was your initial flow, joining a PostgreSQL table with a filesystem dataset, and you’re experiencing that the job takes a while to run:
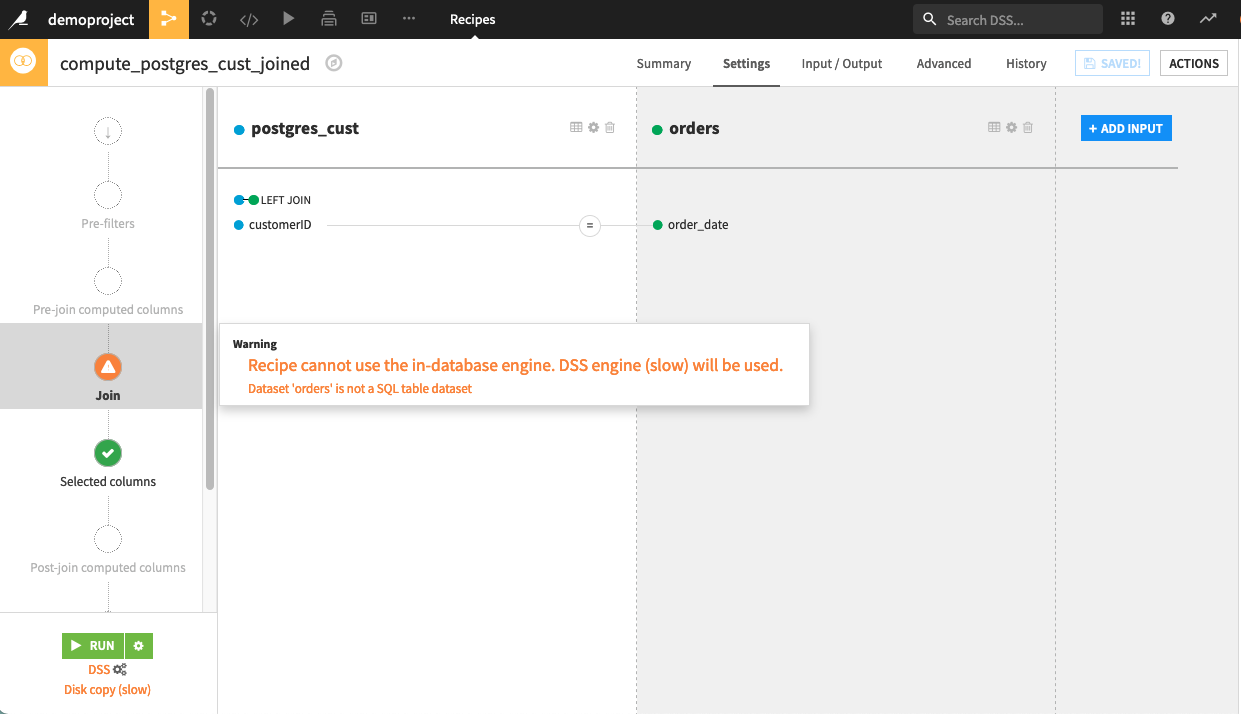
In this case, within the Join recipe, you’ll see a warning that alerts you that Dataiku will use the DSS engine, and that this engine is indeed not optimal for this particular setup:
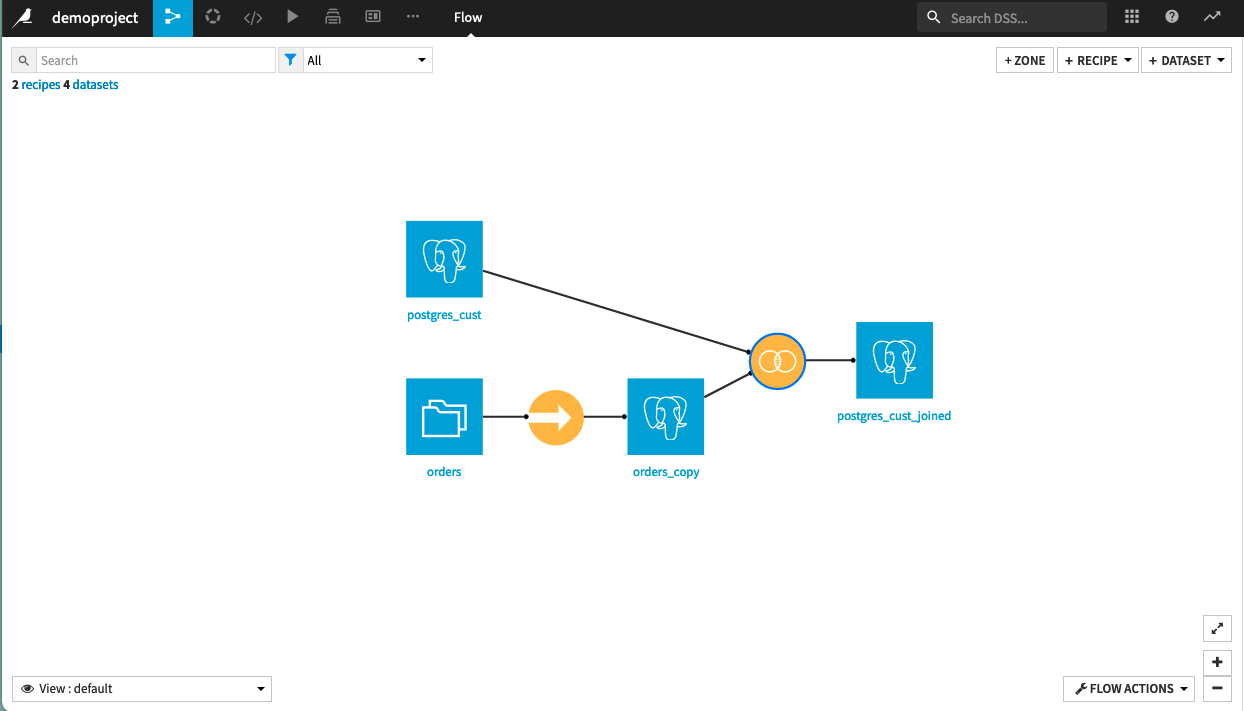
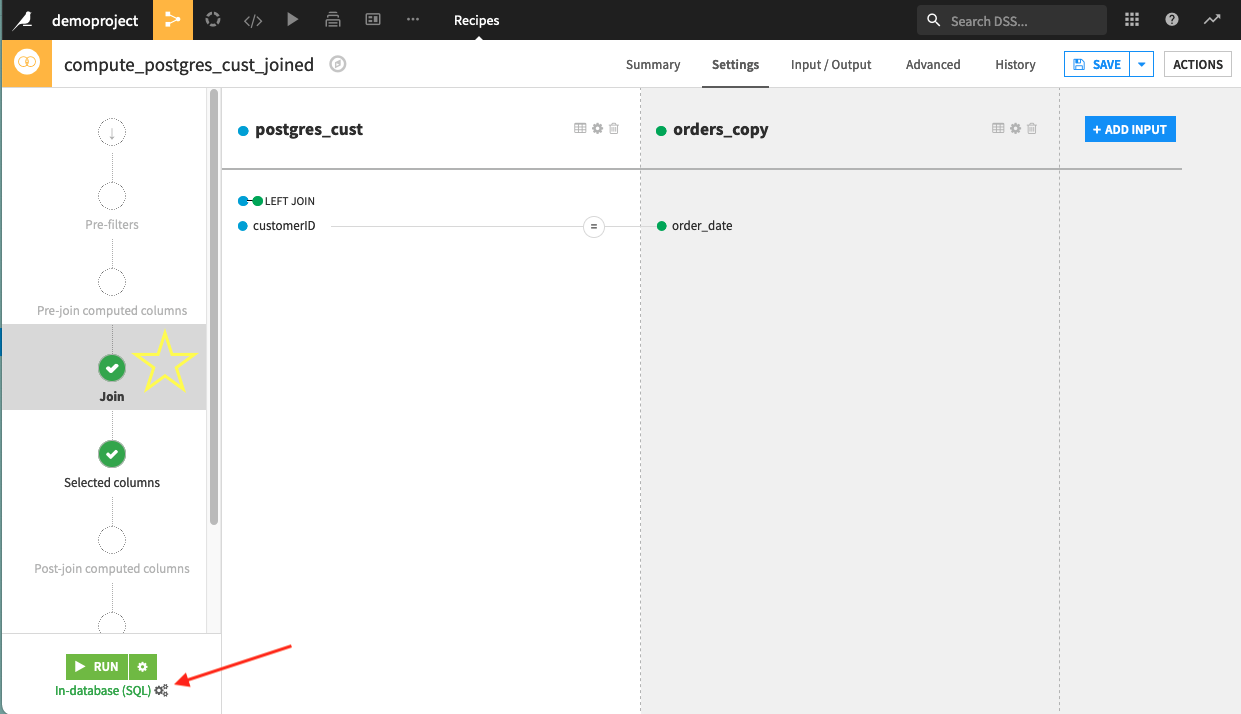
You can optimize this Flow by syncing your filesystem dataset to PostgreSQL, and then performing your Join recipe on two input PostgreSQL datasets instead. This is what the Flow would look like after optimizing it:
This will allow you to select the In-database (SQL) engine for your Join recipe. As a general rule of thumb, if your data is stored in a database, the In-database (SQL) engine is the best choice for computation and will be the most performant.
Like the example above, DSS provides specific fast-path engines that will usually be the most performant. You’ll want to investigate if any recipe could be using a fast-path engine if configured differently.
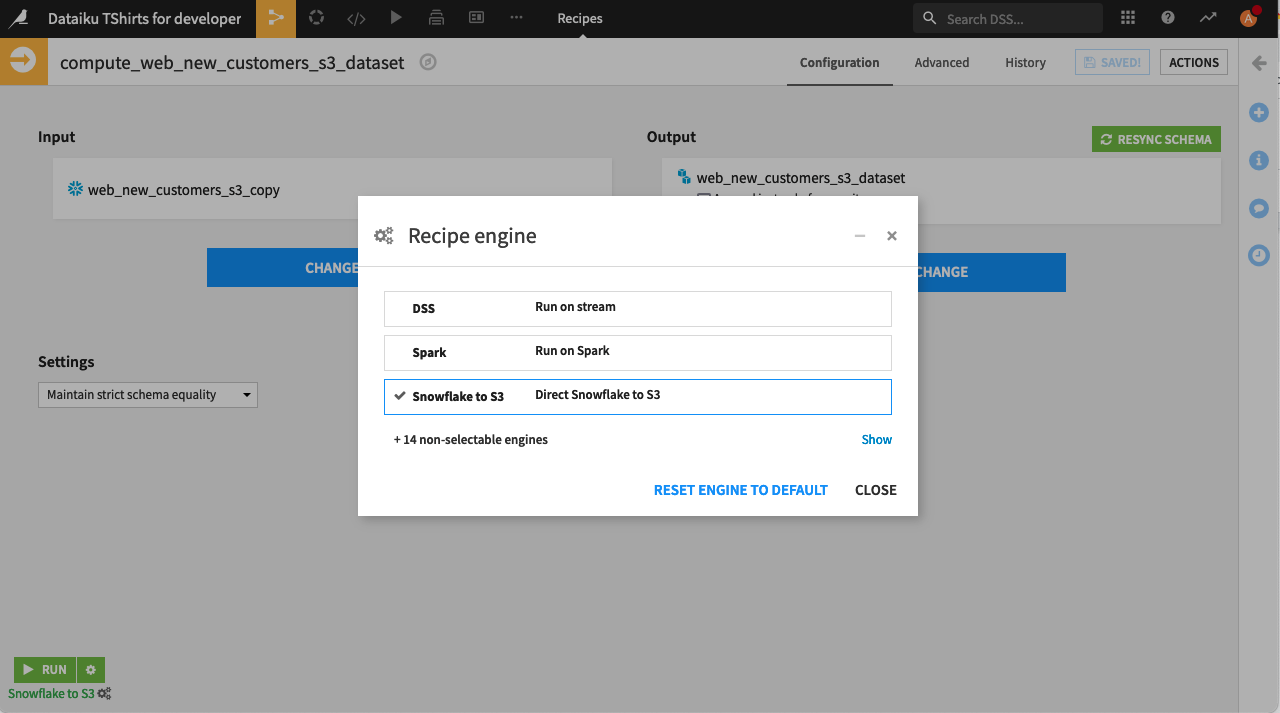
You can check which engine you are using for a recipe by looking at the bottom left-hand side of the visual recipe. You will see all selectable engines by clicking on the wheel icon next to your engine selection: