
Solution | Customer Segmentation for Banking#
Overview#
Business case#
Insightful customer segmentation is a cornerstone of effective business management, marketing, and product development within consumer banking. Many firms have developed deep business knowledge which is applied to their customer pools using business rules logic, slicing the overall customer base into subgroups based on actual or potential revenues, product mix, digital engagement, and much more.
These existing customer analytics provide powerful insight and are often driven by qualitative insights or historical practice. Yet 82% of bank executives say their teams have difficulties identifying new customer segments, which can drive up acquisition costs and reduce retention rates. Leveraging a purely data-driven approach to segmentation introduces the possibility of new perspectives, complementing rather than replacing existing expertise.
The goal of this plug-and-play Solution is to use machine learning in the form of a clustering algorithm to identify distinct clusters of customers, which are referred to in our analysis as Segments. Further analysis is carried out to understand these clusters, and how they relate to the bank’s product mix and existing customer tiering approaches.
The Next Best Offer for Banking Solution completes the customer segmentation Solution within the marketing suite for banking. The user can plug the same data as in the current Solution, and build an initial model. Additionally, the user can use the segmentation output as an input in the Next Best Offer for Banking Solution.
Installation#
From the Design homepage of a Dataiku instance connected to the internet, click + Dataiku Solutions.
Search for and select Customer Segmentation for Banking.
If needed, change the folder into which the Solution will be installed, and click Install.
Follow the modal to either install the technical prerequisites below or request an admin to do it for you.
Note
Alternatively, download the Solution’s .zip project file, and import it to your Dataiku instance as a new project.
Technical requirements#
To use this Solution, you must meet the following requirements:
Have access to a Dataiku 12.0+* instance.
Have installed the Flow Charts plugin.
The Solution requires a Python 3.6 built-in environment. For instances with a built-in environment of Python 2, users should create a basic Python 3 code env, and set the project to use this code env.
To benefit natively from the Solution’s Dataiku app, you need a PostgreSQL or Snowflake connection storing your data (see Data requirements). However, the Solution comes with demo data available on the filesystem-managed connection.
Data requirements#
This Solution comes with a simulated dataset that you can use to demo the Solution and its components. To use the Solution on your own data via plug and play usage, your input data must match the data model of the demo data. You can find more details in the wiki.
The input data should be separated into five different datasets with the same time frequency:
Dataset |
Description |
|---|---|
revenues |
Includes the revenues generated by each product per customer over time. |
product_holdings |
Includes product information and duration period of each product held by customers. |
customers |
Includes customers’ static information. You can add optional columns to this dataset. |
balances |
Includes balance amounts of each product per customer over time. |
additional_information |
Includes optional additional columns. |
Workflow overview#
You can follow along with the Solution in the Dataiku gallery.
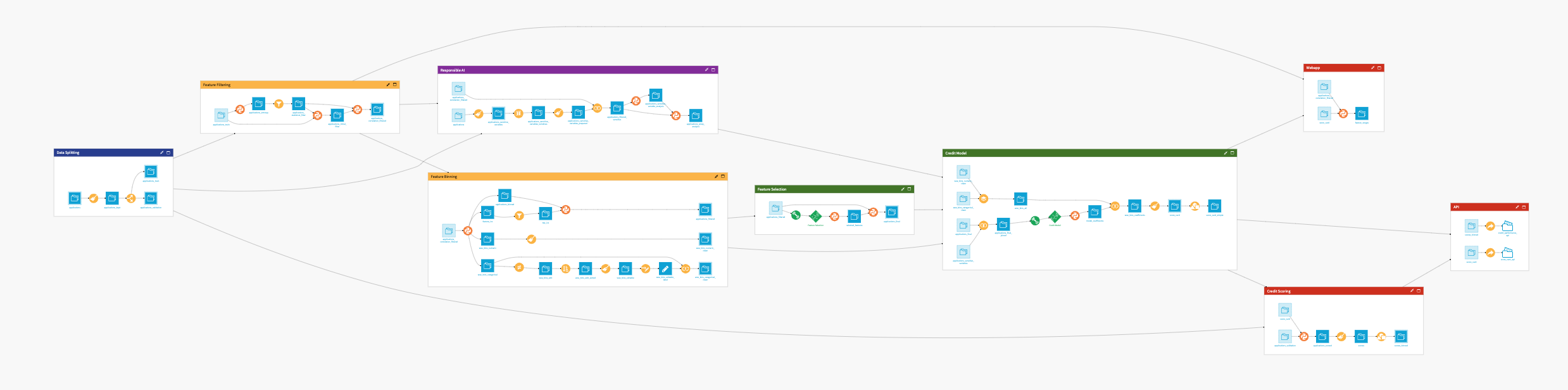
The project has the following high-level steps:
Connect your data as an input and select your analysis parameters via the Dataiku app.
Ingest and pre-process the data to be available for segmentation.
Train and apply a clustering model.
Apply cluster analysis to the identified customer segments.
Interactively explore your customer segments with a pre-built dashboard.
Walkthrough#
Note
In addition to reading this document, it’s recommended to read the wiki of the project before beginning to get a deeper technical understanding of how this Solution was created and more detailed explanations of Solution-specific vocabulary.
Plug and play with your own data and parameter choices#
To begin, you’ll need your own instance of the Dataiku app associated with this Solution.
From the waffle (
 ) menu of the Design node’s top navigation bar, select Dataiku Apps.
) menu of the Design node’s top navigation bar, select Dataiku Apps.Search for and select the application with the name of this Solution.
Then, click Create App Instance.
The project includes sample data. You can replace it with your own data, assuming that it adopts the data model described above.
You can do this in three ways:
Upload data directly from the filesystem in the first section of the Dataiku app.
Connect data from your database of choice by selecting an existing connection.
You can copy connection settings and data from an existing Next Best Offer for Banking project.
In option 1 and 2, users must click the Check button, which will load the data and verify the schema.
Important
Be sure to refresh the page so that the app can dynamically take your data into account.
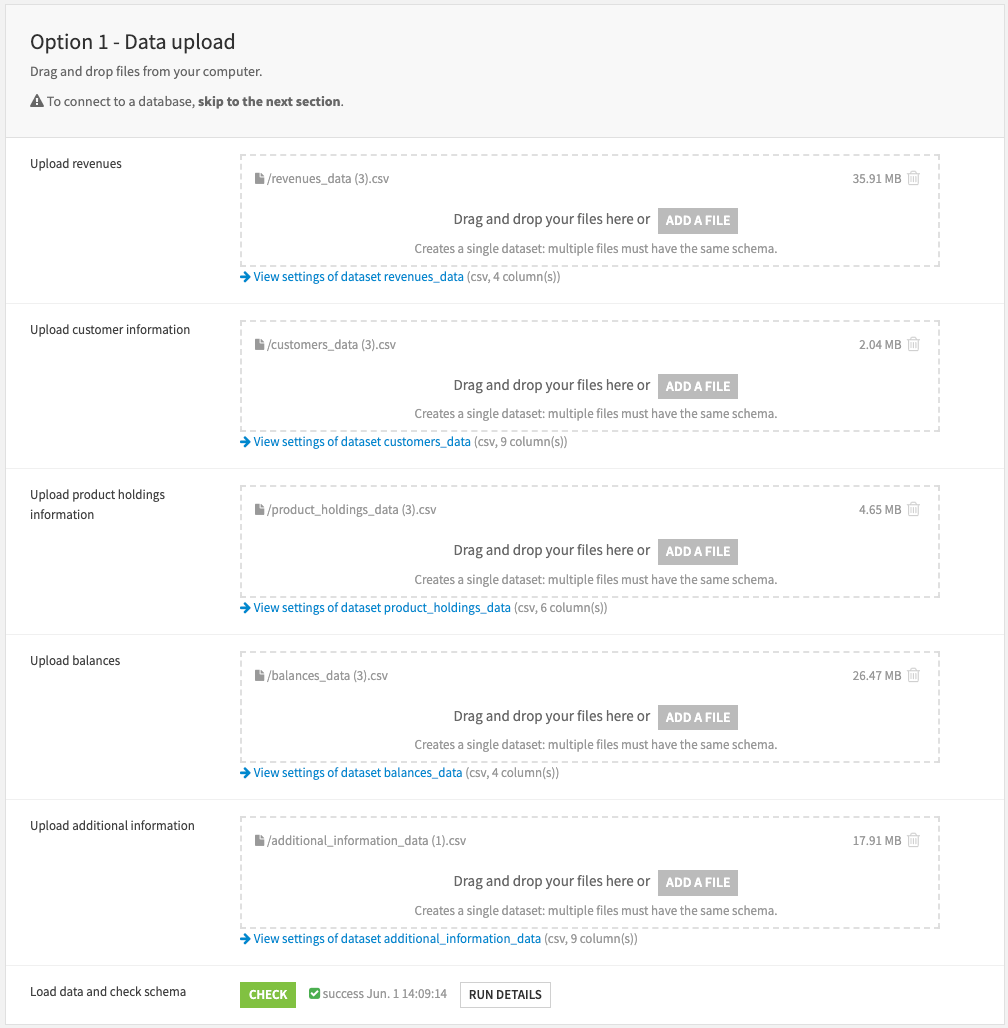
With your data selected and loaded into the Flow, you can move to the following app section:
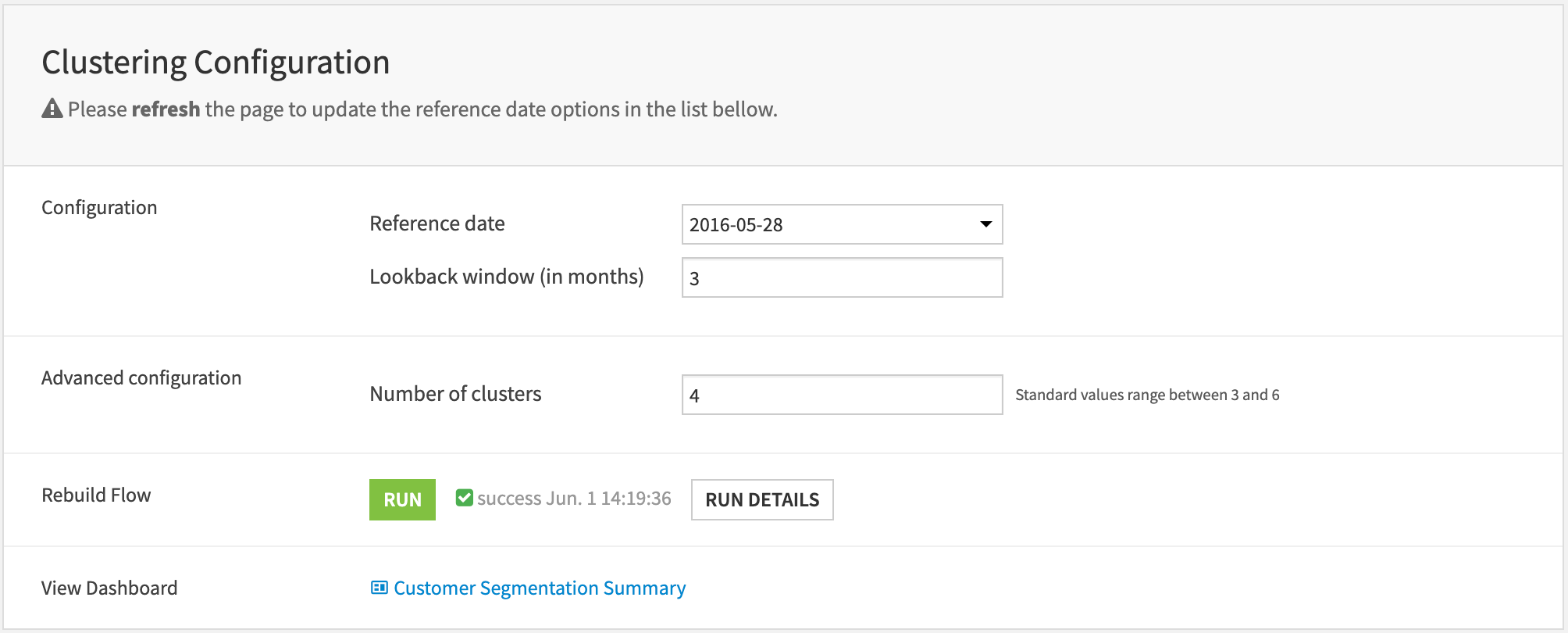
The user needs to input a few parameters to configure the project. Before doing so, press the refresh button to update the reference date dropdown with the available ones. Then select the reference_date: a natural choice for this date is the latest.
Define the lookback period, which you can also interpret as a reference period: features will be computed both on a monthly basis and on a reference period basis. The value is expressed in number of months.
Next, select the number of clusters, standard values range between 3 and 6 but depending on the particular use case, this number can be higher although it would require some more extensive work to interpret each of them.
Then Run button will trigger the scenario that will rebuild the whole Flow. This action will take from a few minutes to hours if the input data is large. Finally, click the link to the dashboard to access ready-made insights on this segmentation.
Ingesting and preparing the data#
Five Flow zones comprise the data preparation.
Flow zone |
Description |
|---|---|
Data Input |
When uploading new data to the Solution via the Dataiku app, the starting five datasets in this Flow zone are reconfigured and refreshed to incorporate the new data. |
Date Preparation |
Creates the initial dates dataset necessary for subsequent data transformations. It does this by identifying unique dates in the product_holdings dataset, extracting year and month values, retrieving the last date per month, and adding the project_reference_date. This value is stored in the product variables and defined in the Dataiku app. |
Customer Data Preparation |
Takes in customer data, as well as the optional additional customer information, and applies a similar methodology to both datasets. The Solution uses a Join recipe to replicate the datasets of customer information as many times as the number of rows in the dates_history dataset to allow historical computation for every period. Following this, the Solution takes the customer data to compute customer age and account age. Meanwhile, it filters out rows that aren’t in the lookback period defined by the Dataiku app before finally using a Group recipe to compute each feature per customer on the last month and the average of each feature per customer on the reference period. |
Product Preparation |
Outputs two key datasets.
|
Balanced and Revenues Preparation |
Handles the preparation of the balances_renamed and revenues_renamed datasets. The Solution joins these datasets and enriches them with the correspondence table of products from the last Flow zone. Repeating the similar methodology of previous Flow zones, the data is joined with dates_history to contextualize the data relative to the reference date. The output of the Flow zone is a dataset containing, for each product type:
|
With the data sufficiently prepared, you’re ready to train and deploy a model.
Train and deploy a clustering model#
The Segmentation Model Flow zone begins by joining all previously prepared datasets to create the customer_full_data dataset. It uses a filter to keep only active customers at the given reference date and then split the data to separate historical data from the reference data (which will be used to train our model).
Before training, the Solution takes logs of the variables for income and those coming from customer behaviors, revenues, and balances. The reason behind this decision is to avoid having too many outliers. Most of these variables exhibit log-normal distribution, with high density around low values and a few large values.
Clustering isn’t an exact science. The way features are preprocessed and included in the analysis hugely impacts the result. You must put great care into ensuring that the business hypothesis is well reflected in the model.
Before training, the Solution includes some feature handling, depending on whether the features are numerical or categorical: categorical variables are dummy encoded and numerical variables are rescaled using standard rescaling.
You can also make choices on the set of variables to include in the model. For instance, you can segment by focusing mostly on revenues and ignoring demographics. Similarly, you can build segments by using behavioral data and dismissing revenues.
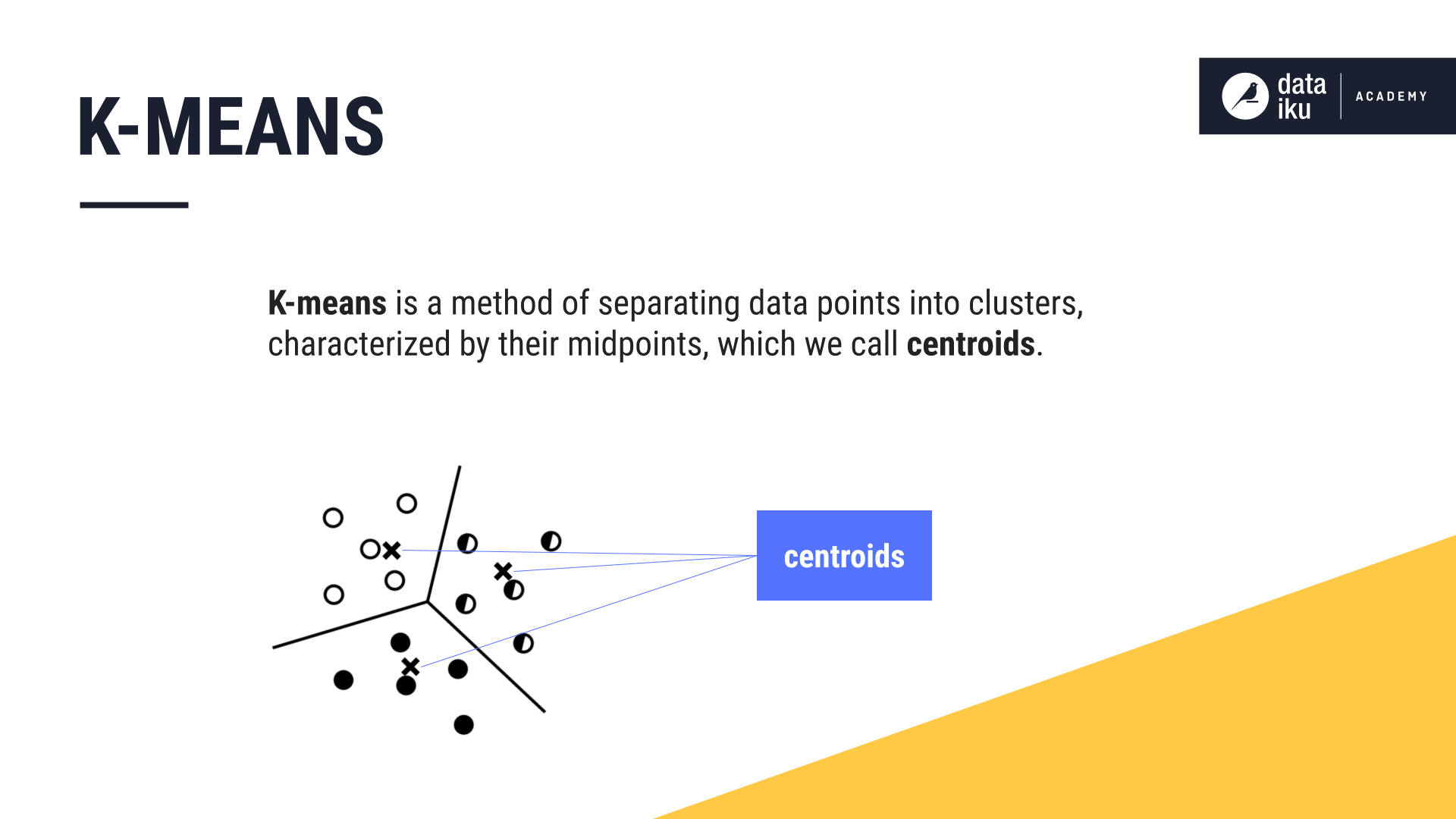
The clustering model is a KMeans algorithm, with the number of clusters set programmatically according to the value input in the Dataiku app. You can adjust this number depending on how diverse the customers are.
This example chose not to detect outliers as we don’t want to have customers not belonging to any of the segments. Clusters have been automatically renamed based on the variables that mostly define them.
However, the user has the possibility to summarize this information with a more human-readable name thanks to the edit button and rebuild the graph using the rebuild_graphs scenario provided with the Solution. The model is deployed on the Flow and used to score the reference data and historical data with identified segments.
Analyzing clusters for smarter customer engagement#
The Solution uses several Flow zones to analyze the identified customer segments. Each Flow zone has output datasets that you can explore for additional analysis, but they all are used to create the visualizations provided in the pre-built dashboard.
Flow zone |
Description |
|---|---|
Summary |
Computes the quintiles for customer income, age, and account age. The project applies Prepare and Group recipes to count the customers per category, for each segment and tier. The two output datasets serve as the base for several graphs on the dashboard providing in-depth descriptive statistics about the segmentation and tiers. |
Cross Sell |
Analyzes the output of the segmentation with respect to cross-sell, and also creates insights about tiers and cross-sell without the need for any segmentation. |
Product Mix |
Computes the distribution of product portfolios for each tier and segment. |
Transition Analysis |
Focuses on how customers move between segments and serves as the underlying dataset to create the interactive Sankey charts in the dashboard. |
Historical Analysis |
Groups the scored historical data to compute the count of customers, the sum of revenues, and the average of revenues for each segment and reference date. |
Create customer data input for NBO |
Creates a dataset similar to the input customers dataset with one additional column including the segmentation result. |
Further explore your segments and tiers with pre-built visualizations#
The Customer Segmentation Summary dashboard contains five pages.
Page |
Description |
|---|---|
Segmentation Model Analysis |
Contains visualizations published from the model results. You can find additional visualizations and more details on the segmentation model within the saved model interface linked from the dashboard. As mentioned, you can edit cluster names from the saved model interface. You can run the scenario to rebuild the graphs from this first tab of the dashboard. The graphs on this tab provide a summary of identified clusters, a cluster heatmap, and variables’ importance to the clustering model. 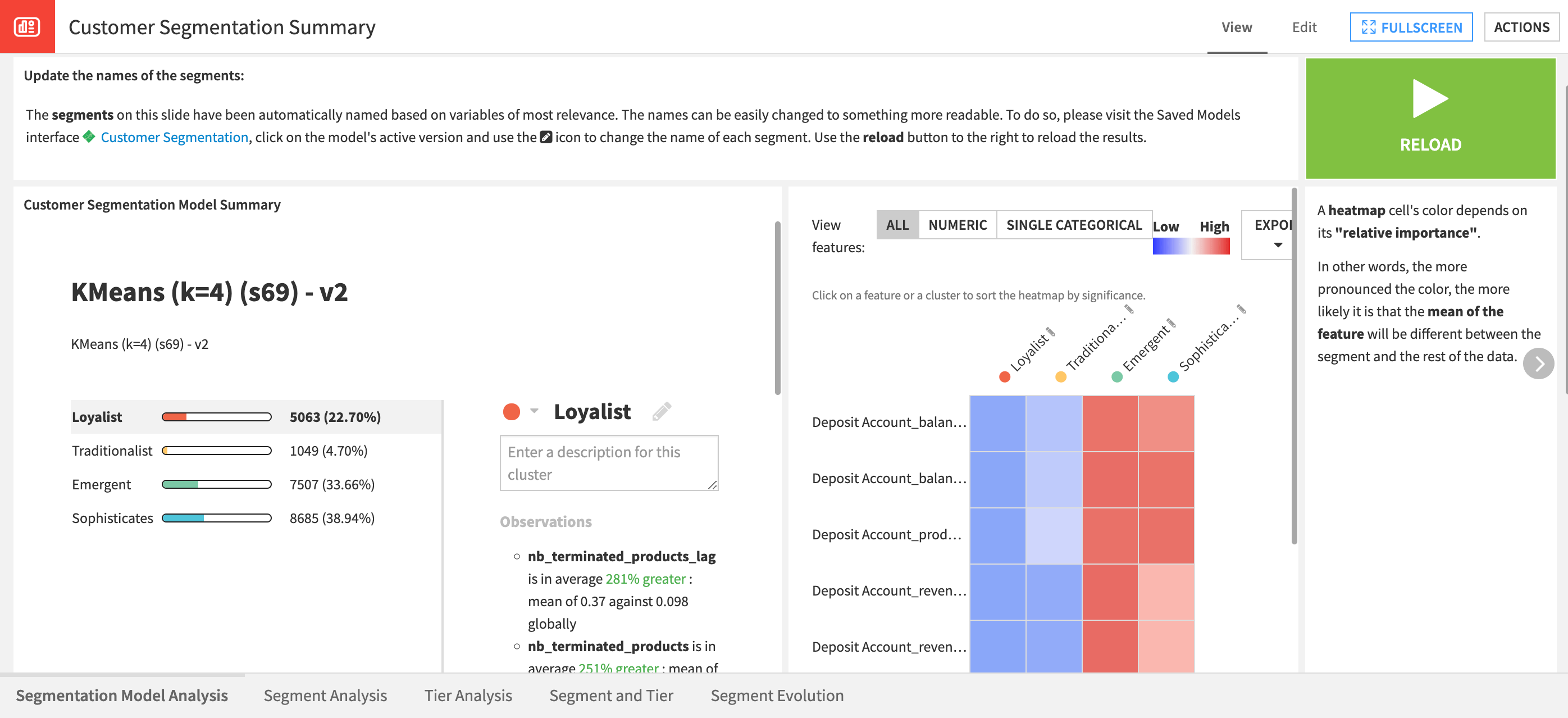
|
Segment Analysis and Tier Analysis |
Contain the same graphs with the only difference being whether charts are created according to tiers or segments. These charts are a starting point to understanding how segments/tiers are constituted but you can build additional charts. The graphs provide four areas of analysis per segment/tier: revenue and cross sell, age distributions, product mix, and pivot tables with total revenue, average revenue per customer, and customer number. 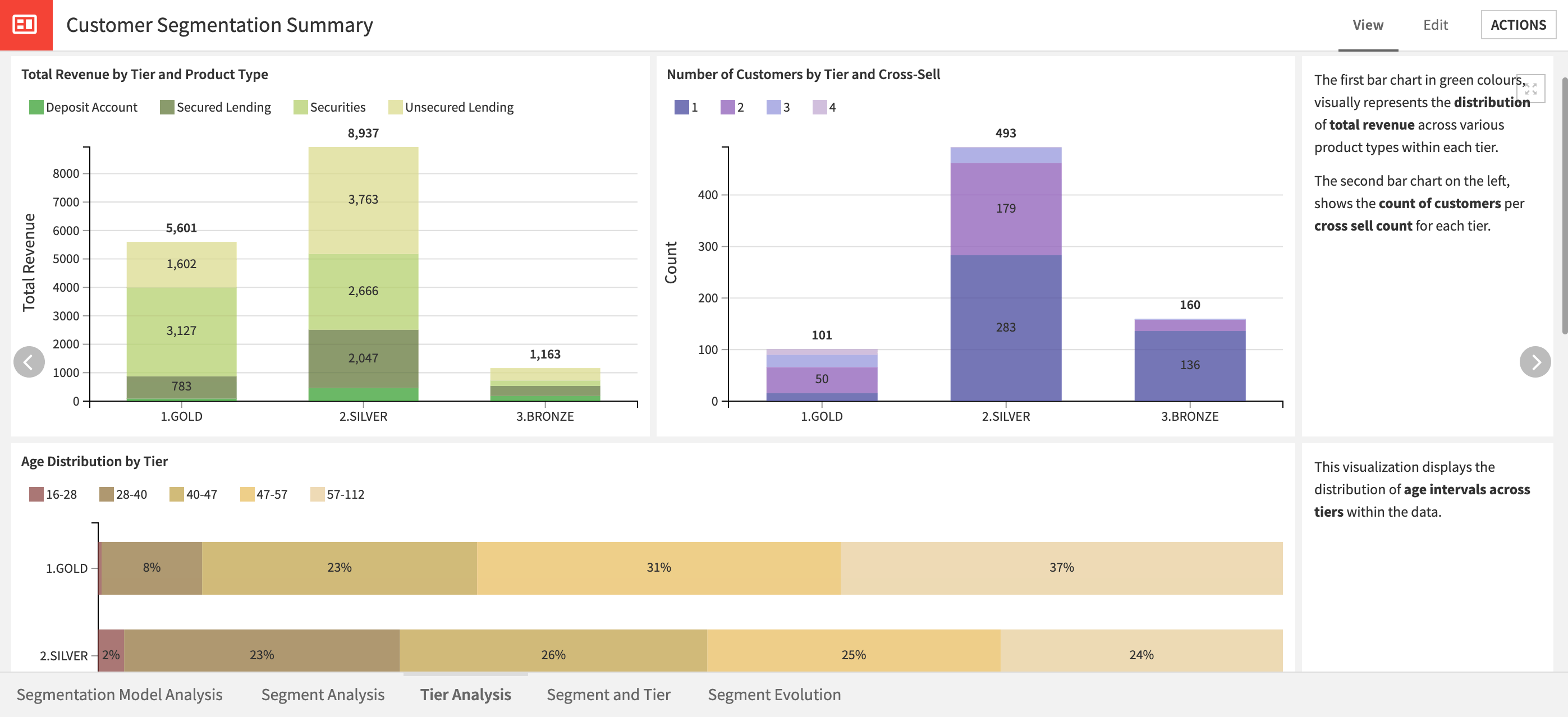
|
Segment and Tier |
Is a comparison of the segmentation created by the project using a data-centric approach to business tiering. The first two graphs allow for understanding if there are close links between the tiers and segments, or if they’re built independently. The second pair of graphs focus on the revenue repartition between tiers, or segments. This approach helps to pinpoint the most profitable areas, and from which tier and segment. Additionally, there are two Pivot tables to aid in the understanding of the revenue repartition. 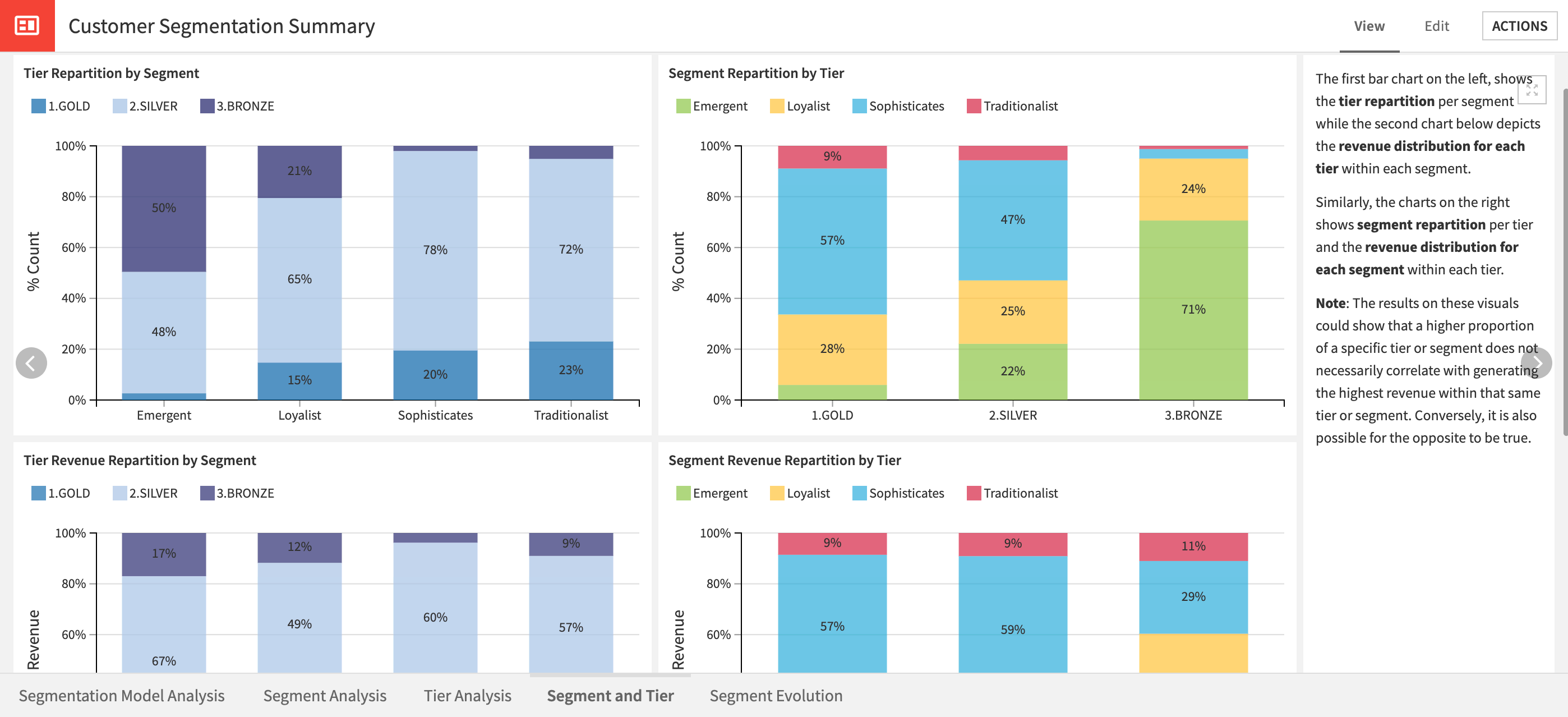
|
Segment Evolution |
Presents a new way of looking at segments as dynamic identifiers. In looking at the Segment Stability, Transition, and Evolution graphs, you can see how customers move between different segments over time and what might be the causes of these transitions. The Sankey charts are interactive and allow users to click on other segments to change the focus. 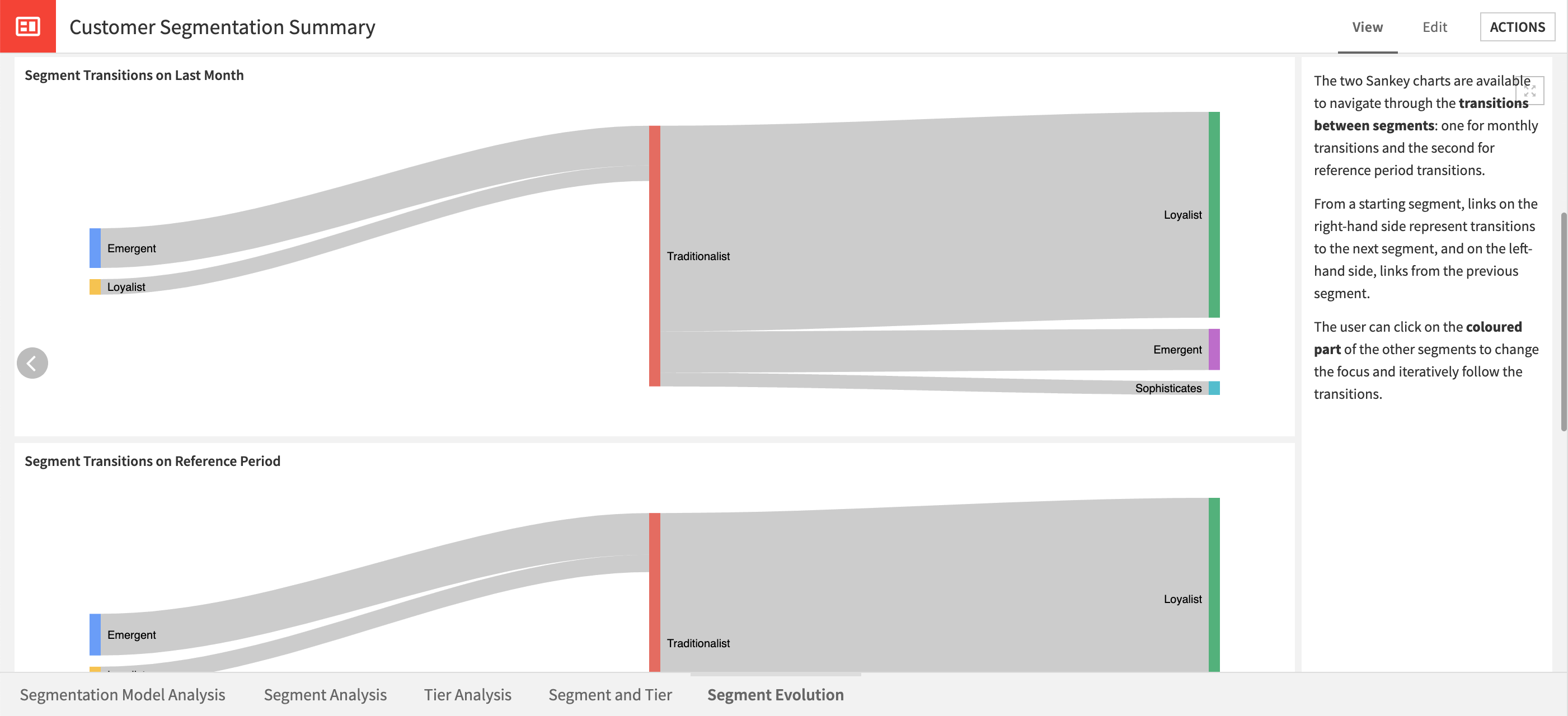
|
Reproducing these processes with minimal effort for your data#
This project equips business management, marketing, and product development teams in consumer banking to identify new and existing customer segments using Dataiku.
By creating a unified space where existing business knowledge and analytics (for example, on Cross Sell and Tiering) are presented alongside new and easily generated Machine Learning Segmentations, business teams can immediately understand the incremental value of an ML approach, without disrupting or separating their existing analytics and subject-matter expertise.
This documentation has provided several suggestions on how to derive value from this Solution. Ultimately however, the “best” approach will depend on your specific needs and data. If you’re interested in adapting this project to the specific goals and needs of your organization, Dataiku offers roll-out and customization services on demand.