Reference | Querying datasets from metastore-aware engines#
You can query datasets from metastore-aware engines, including datasets that are synced to the metastore from Hive, Impala, SparkSQL, and Athena.
Querying HDFS Managed Datasets#
Once the dataset definitions are synchronized to the Hive metastore (through HiveServer2), you can query HDFS managed datasets from metastore aware engines.
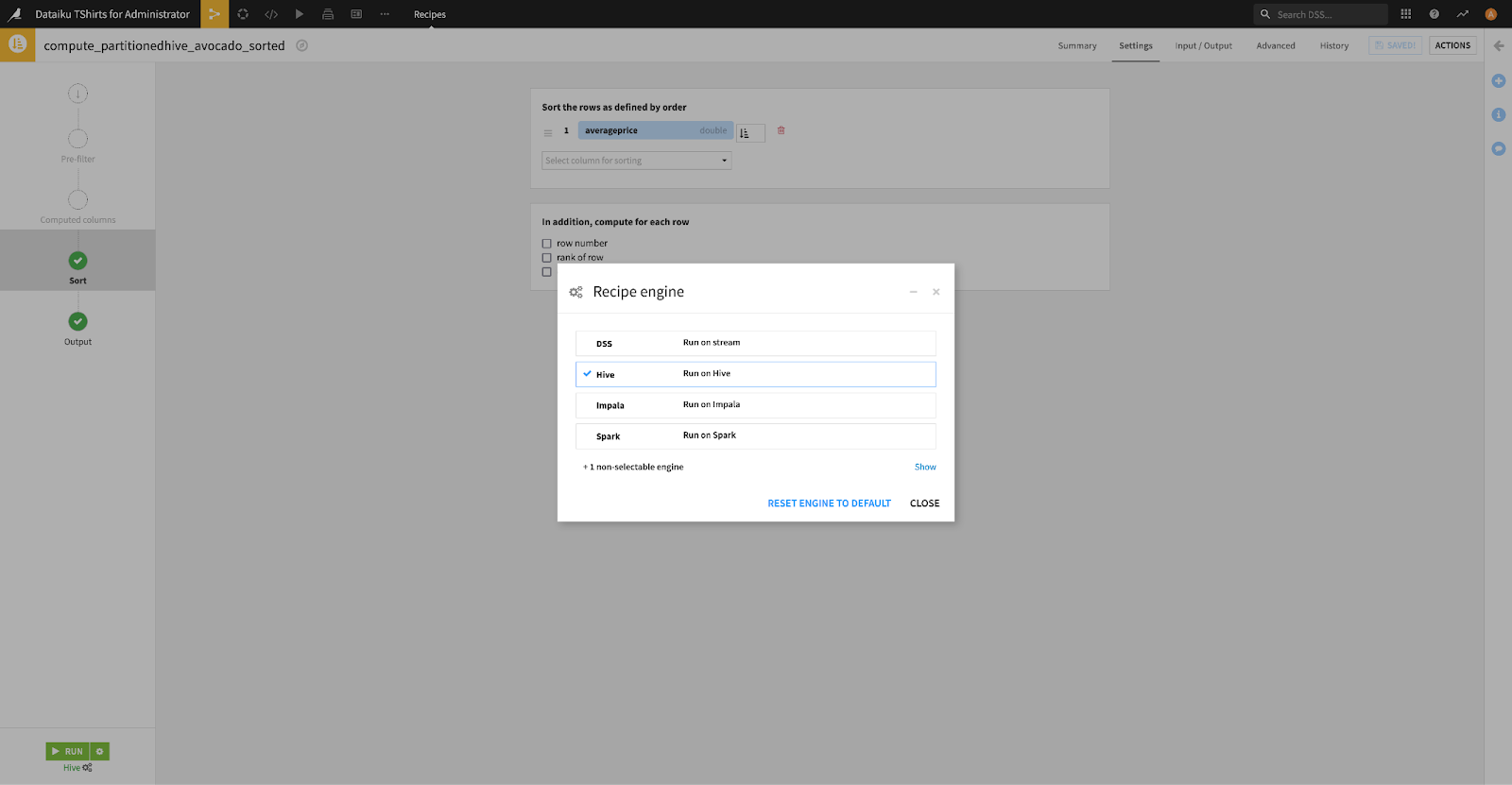
In the following example, we’re using a Sort recipe to sort the rows of our dataset by averageprice. Since our dataset definitions are synchronized to the Hive metastore, we can successfully run the recipe with Hive or Impala engines.
Querying S3 Datasets#
Similarly, you can query S3 datasets from metastore aware engines.
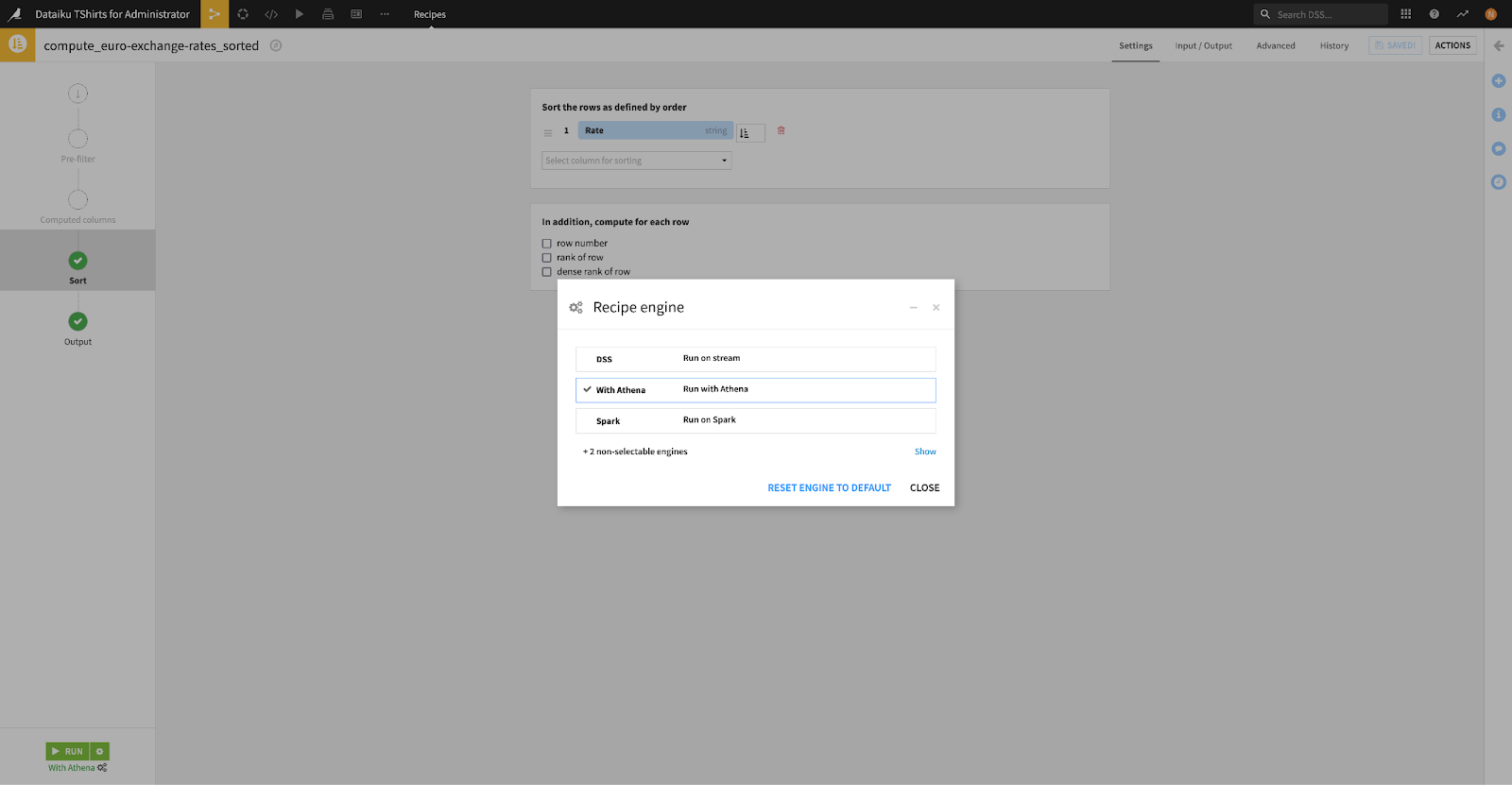
In the following example, we’re using a Sort recipe to sort the rows of our dataset by Rate.
Since we configured DSS to use the Glue metastore and made sure the S3 connection has the “keep datasets synced” metastore property, Athena is able to find the definition of the input dataset to successfully query it.
The Athena engine uses the metastore catalog to get the dataset definition.