
Reference | The Dataiku elastic AI stack#
A Dataiku instance is made up of one or more nodes.
The Dataiku elastic AI stack is a single platform made up of nodes.
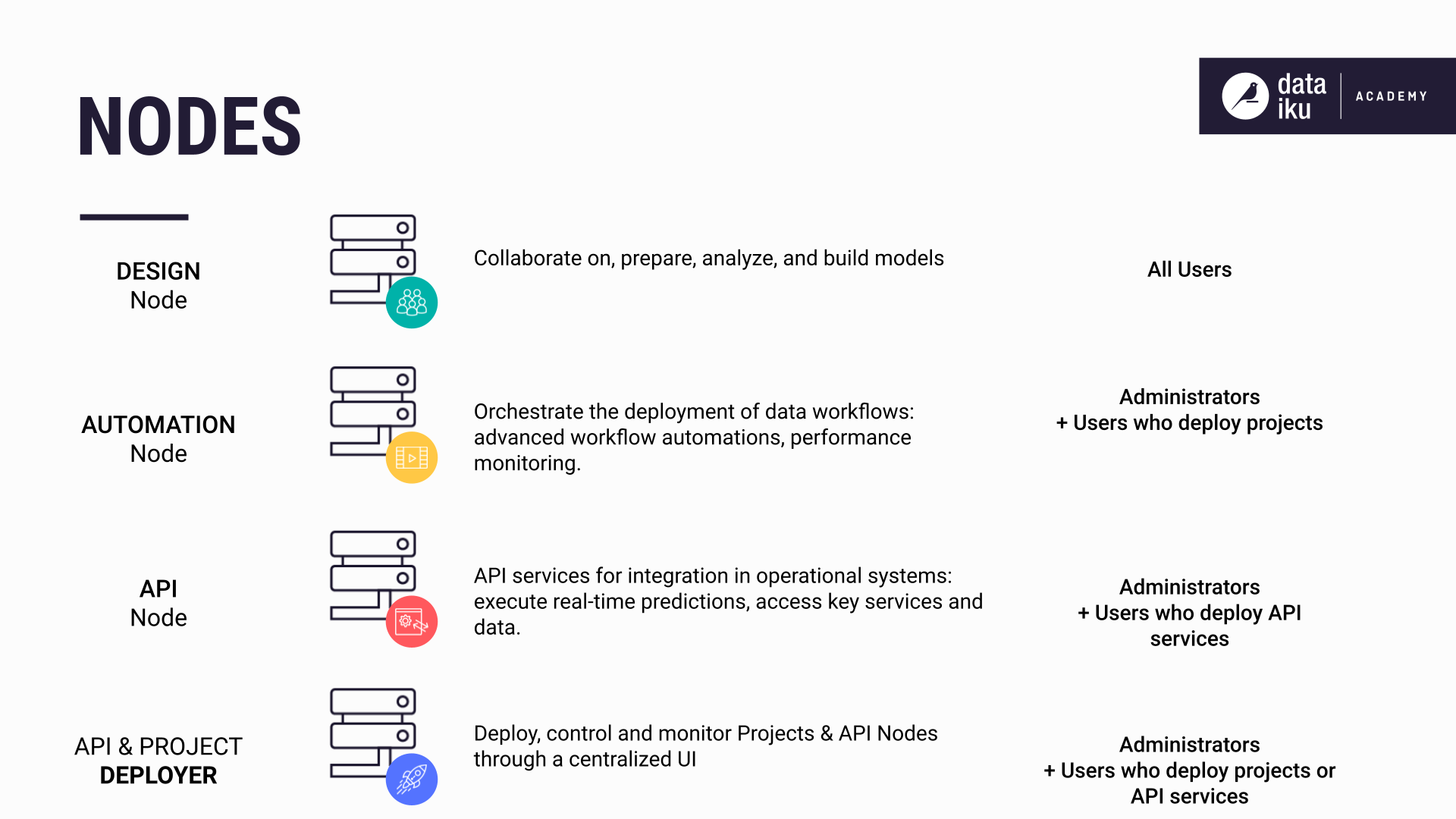
Design node#
The Design node is a dedicated node serving all Dataiku users. Users collaborate and create data science pipelines (also known as Flows) in the Design node. You can think of the Design node as a sandbox environment for building or improving data logic and even building machine learning models. The Dataiku user can test the logic they design before deploying it to a production environment.
Deployment is managed through the Deployer.
Deployer#
The Deployer is the centralized place for managing deployment to production. The Deployer can run as a dedicated node or run locally on a Design or Automation node.
Once a Dataiku user has created a project and tested its logic on the Design node, they can deploy their project or certain parts of it by using the Deployer. If deploying a project, it must be exported to one or more Automation nodes as a bundle. If deploying specific components from your project, you’ll need to create an API service that will be deployed to the API node.
The Deployer has two separate but similar components: the Project Deployer, for deploying project bundles, and the API Deployer, for deploying API services.
The Project Deployer component makes it easy to:
manage all your Automation nodes,
deploy bundles to your Automation nodes, and
monitor the health and status of your deployed Automation node projects.
Bundles are automatically versioned so that you can roll back to a different version of the project as needed. To learn more, visit the Project Deployer.
The API Deployer component allows you to:
Define API infrastructures, each pointing to either installed API nodes or a Kubernetes cluster,
Deploy your API services on an infrastructure (that is, to all the API nodes in the infrastructure), and
Monitor the health and status of your deployed API services.
Automation node#
The Automation node is a dedicated node that acts as the production environment, sometimes referred to as the execution node. It provides a way to separate your development and production environments and makes it easy to deploy and update projects in production.
Flows deployed to the Automation node can take minutes or hours to execute, depending on the size and complexity of each flow.
API node#
The API node is a dedicated node that does the job of answering HTTP REST API requests. API nodes are horizontally scalable and highly available. The API node can be deployed either as a set of servers or as containers through Kubernetes (The latter allows you to deploy either on-premises or on a serverless stack on the cloud).
The API node is suited for short pipelines that run on demand and return an answer in seconds, not hours.
Govern node#
The Govern node is a dedicated node for managing governance of data science projects. Similar to the Automation and Deployer nodes, the Govern node is an additional node in your Dataiku cluster.
The Govern node requires an enterprise license.
Permissions#
The Design and Automation nodes need permissions to connect to the Deployer via HTTP(S). The Design node connects to the Deployer to deploy project bundles or API services. The Automation node connects to the Deployer for reporting metrics related to the health of deployed services.
Optional: Kubernetes in the cloud#
You can also use Kubernetes clusters in the cloud (Azure Kubernetes Service (AKS), Elastic Kubernetes Service (EKS), or Google Kubernetes Engine (GKE)) for distributed Spark computing or for powering notebooks or recipes.
You must provide the Design or Automation node with the permissions they need to interact in the Kubernetes-in-the-cloud ecosystem. This includes container registries, autoscalers, key management systems, and security policies. For more information, visit Installing and setting up.