How-to | Query datasets from a metastore-aware notebook#
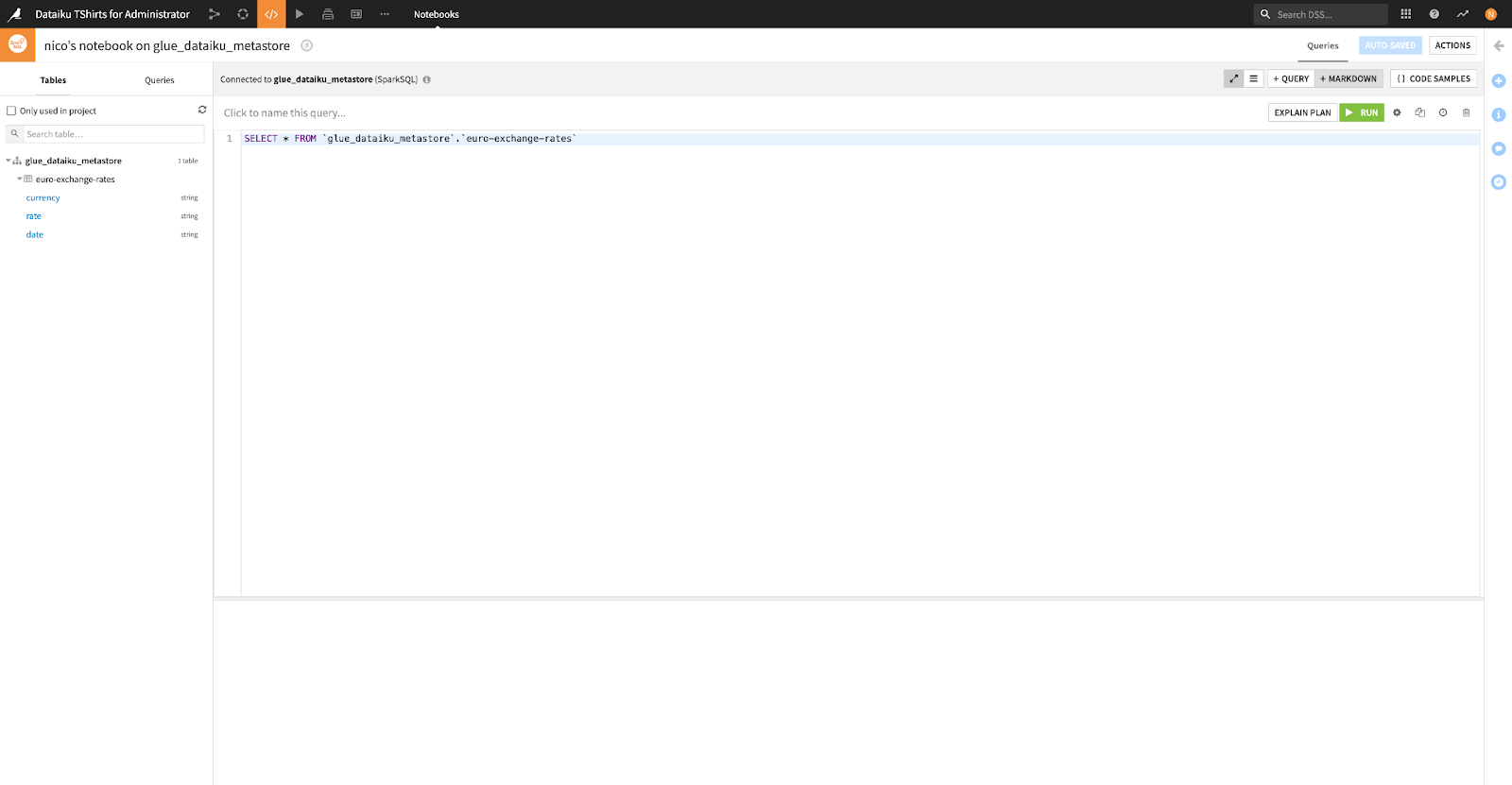
Another advantage of having your datasets’ definitions synchronized to the metastore is that you can directly query the datasets from metastore-aware engine notebooks including Hive, Impala, and SparkSQL notebooks.
Note
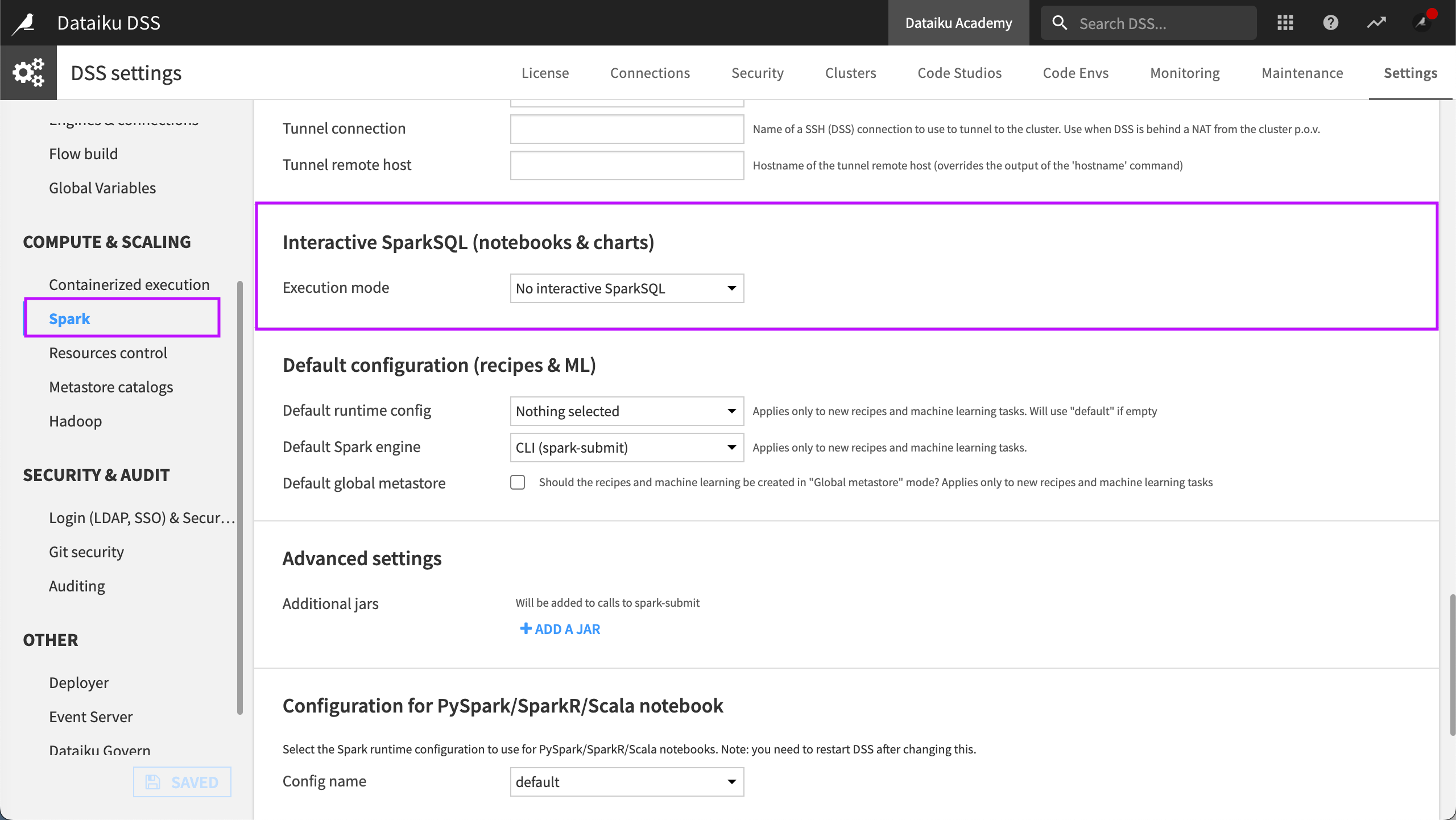
To query an S3 dataset from a SparkSQL notebook, configure the Interactive SparkSQL Execution mode. You’ll find this by visiting Administration > Settings > Compute & Scaling > Spark.