
Concept | Cleaning text data#
Watch the video or read the summary below.
The article on NLP challenges looked at some of the problems you might run into when using the bag of N-grams approach and ways to solve those problems.
Having introduced these concepts, let’s see how we can implement these techniques in Dataiku.
Consider a simple dataset of SMS messages. One column is raw SMS messages. The other is a label, 1 for a spam message and 0 for a non-spam message. The task is to train a model that can classify SMS messages into these two categories.
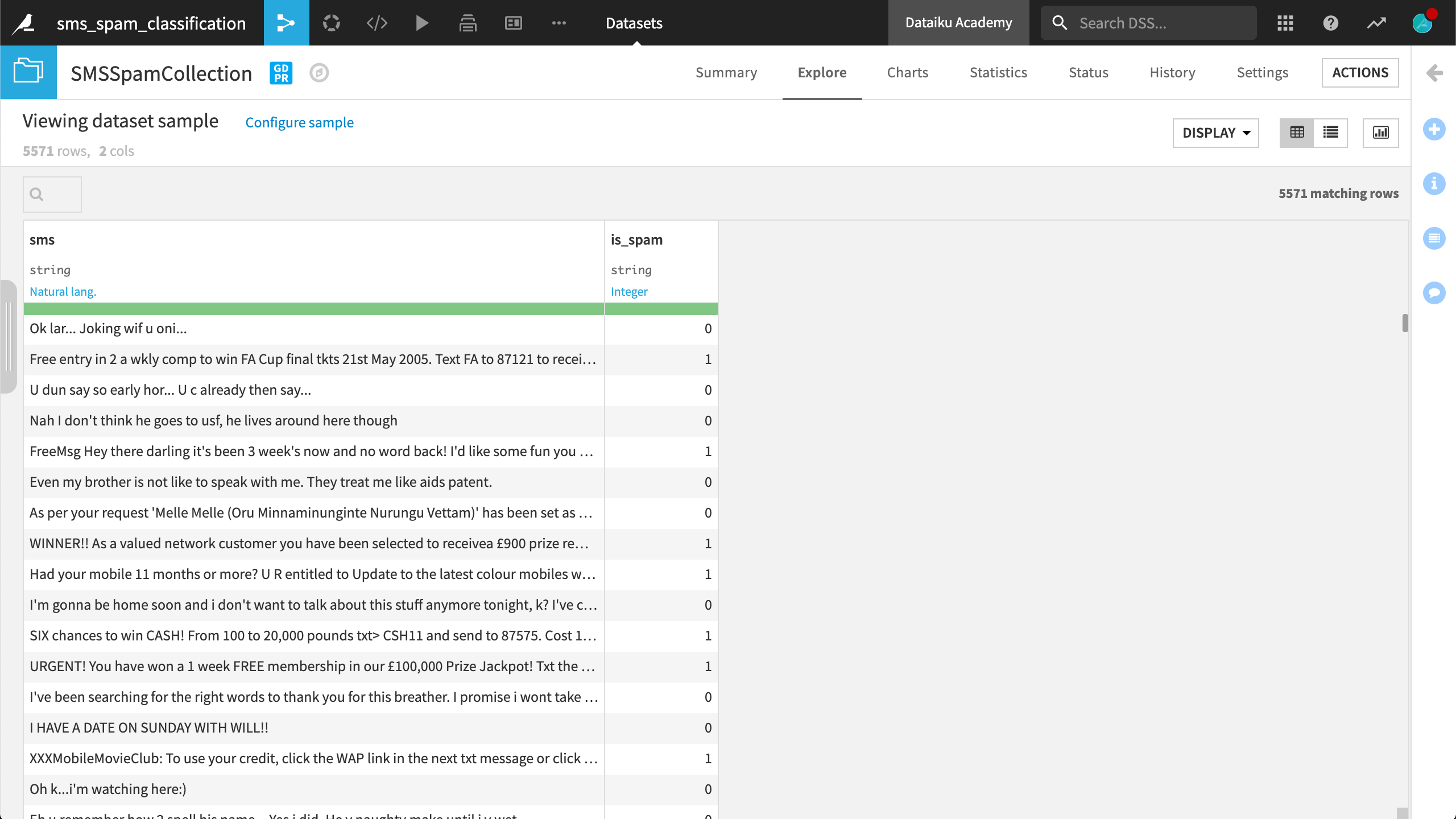
Just browsing these messages, you can see that normal human language is far from clean. It’s filled with abbreviations, misspellings, and unusual punctuation.
It’s helpful to explore the data using the Analyze window before cleaning it with a Prepare recipe or attempting to create a model.
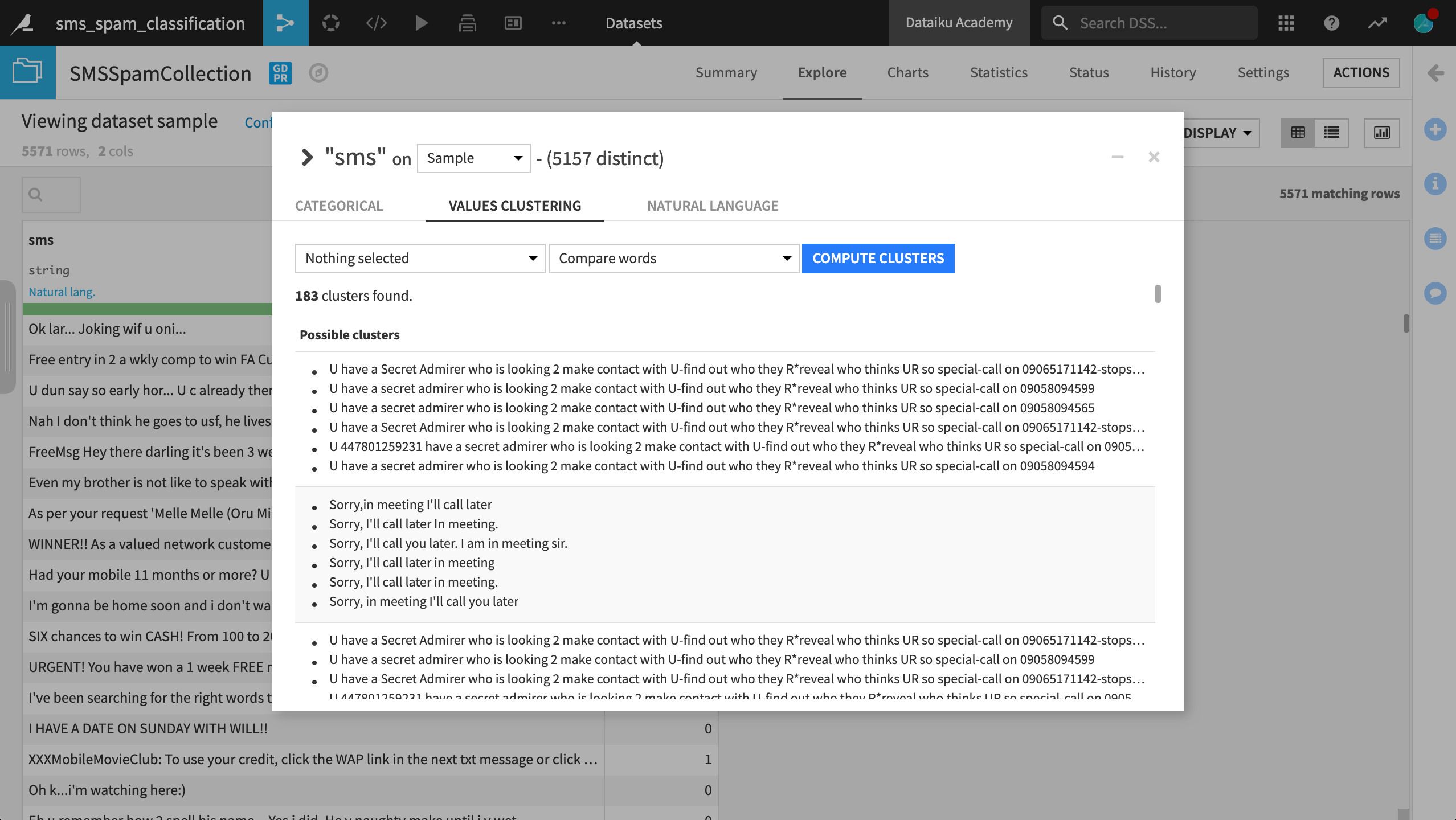
After computing clusters, you can see that many messages, particularly spam messages, follow similar formats, perhaps only changing the phone number where the recipient should reply.
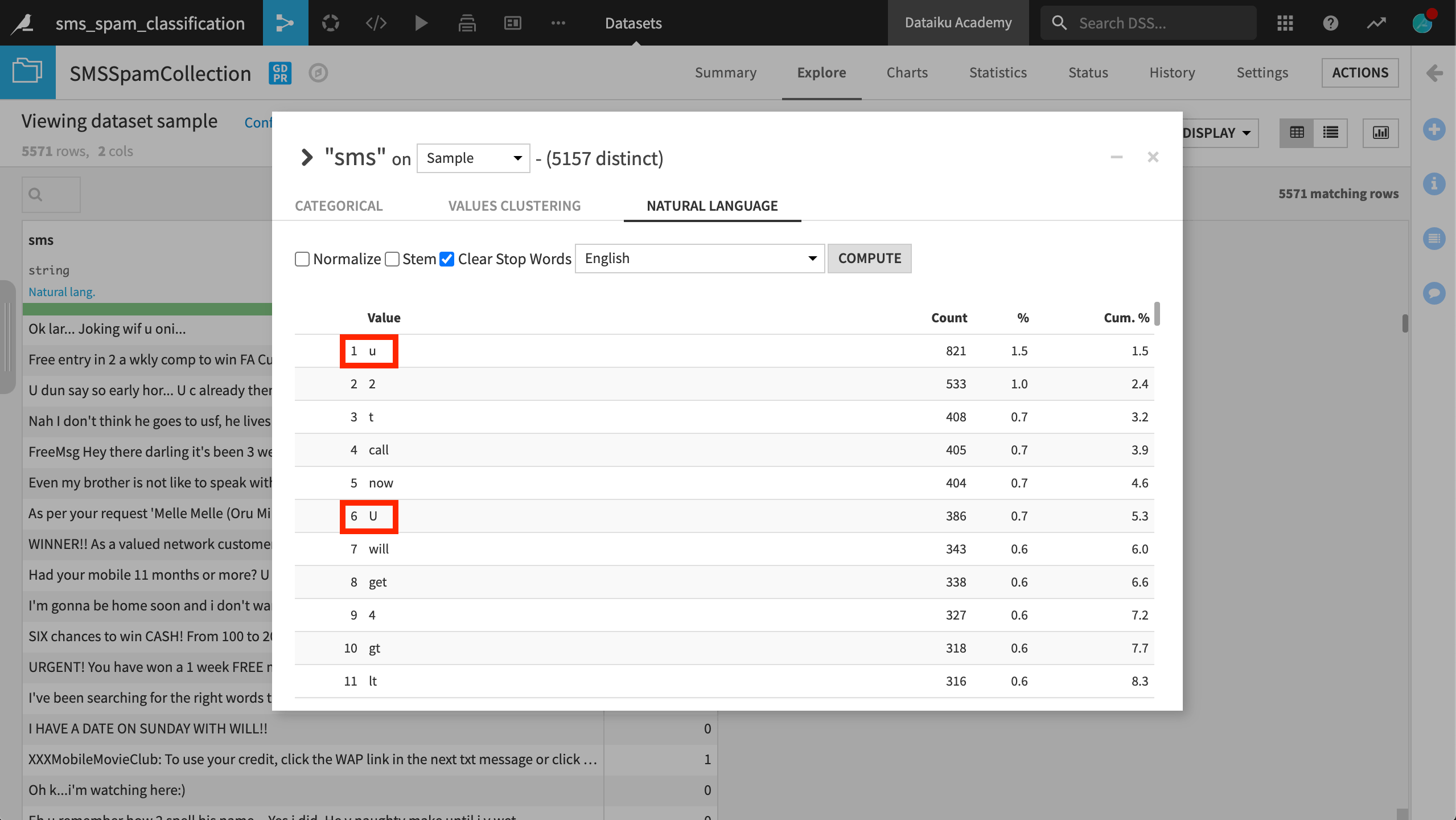
You can also compute counts of the most common words. If you fail to normalize text, you can see that lowercase and uppercase “u” are treated as two different words. Keeping this distinction probably won’t help the classifier, as it will have to learn that these two words carry the same information.
Cleaning text data#
With some knowledge of the dataset, let’s start cleaning in a Prepare recipe.
Simplify text#
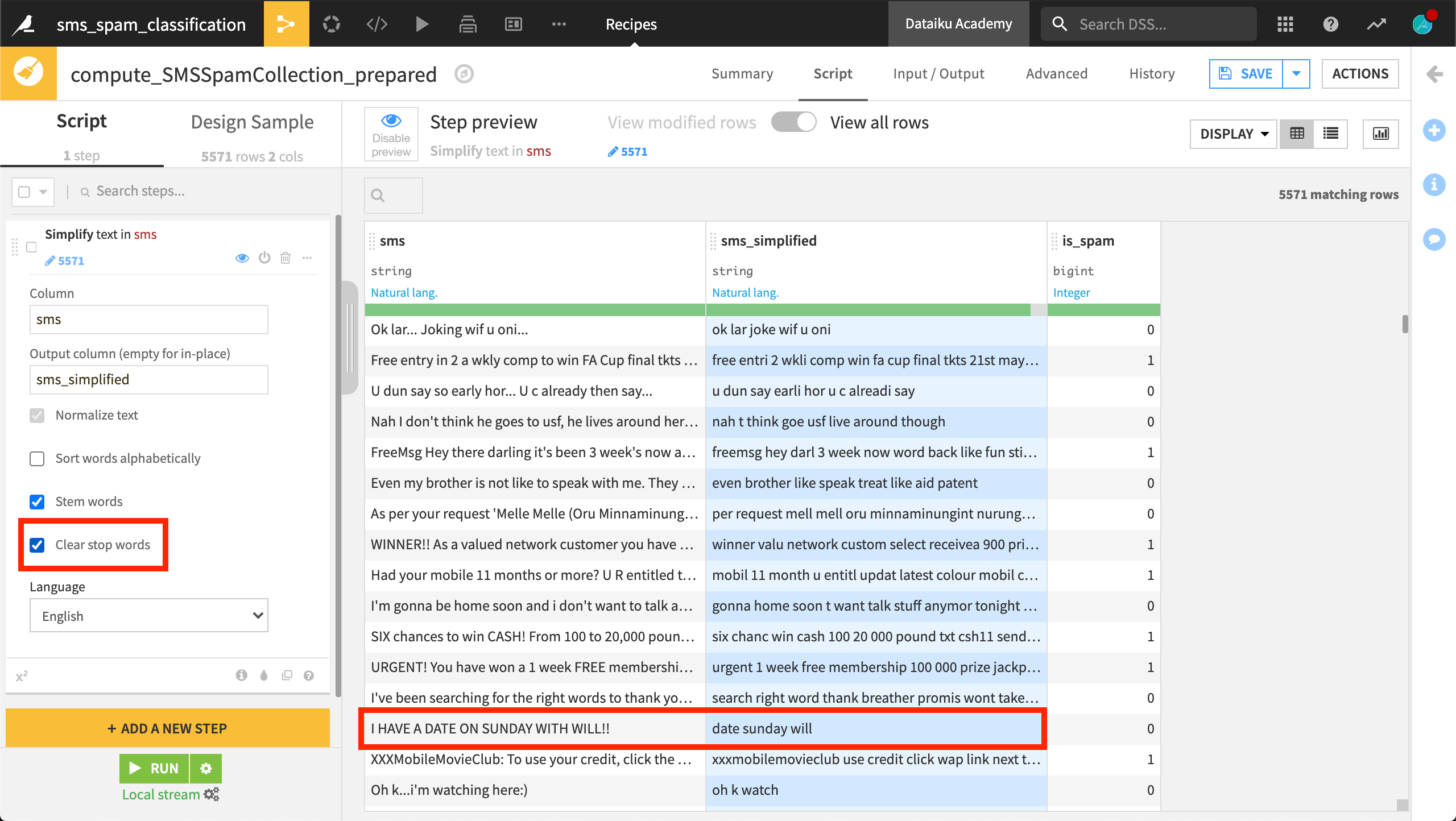
In the processors library, the most important step for text cleaning is to apply the Simplify text processor.
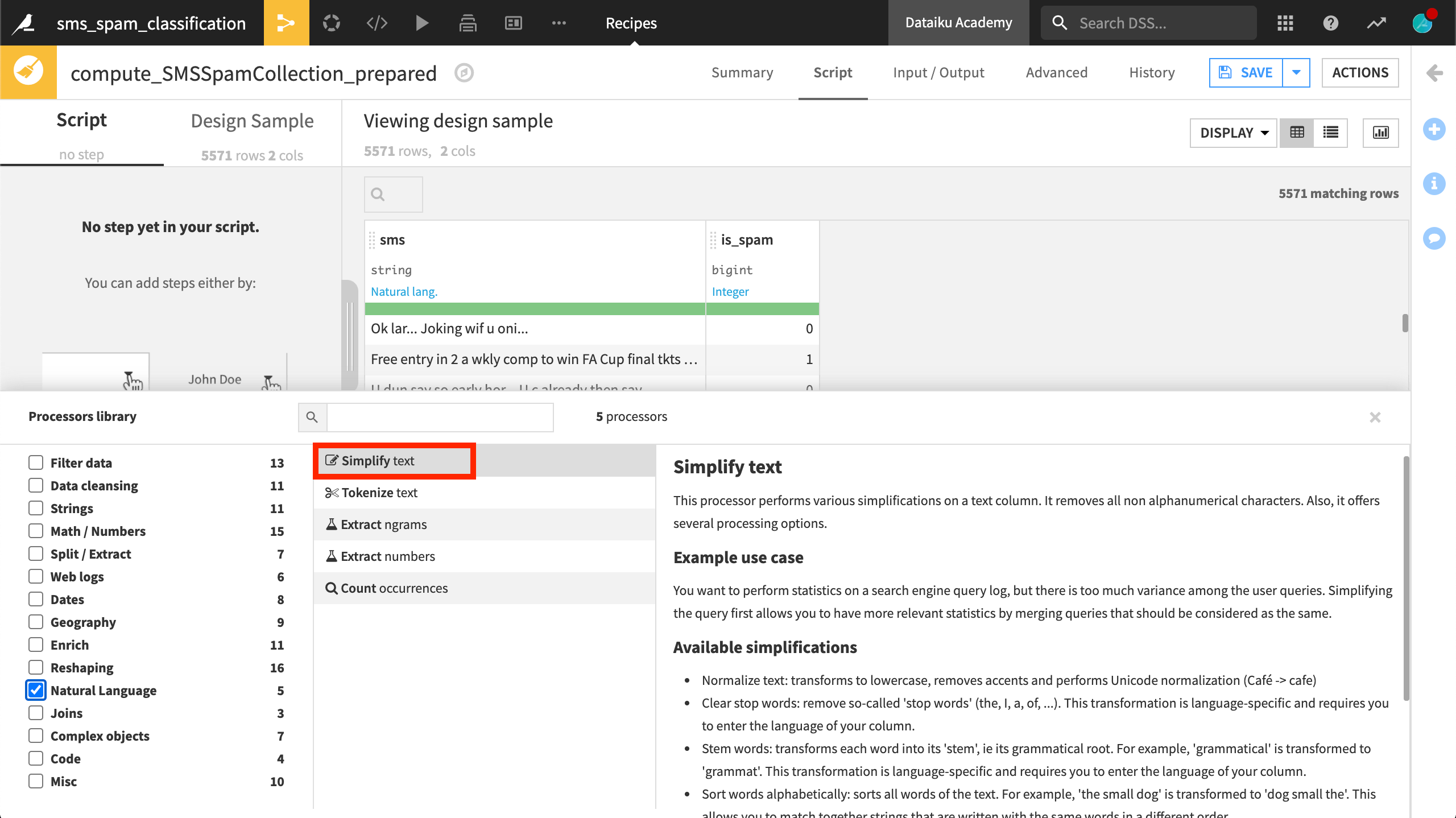
The Simplify text processor takes a column of text as input, and outputs the transformed text to a new column, or in place if the output column field is left empty. This processor offers four kinds of text transformations.
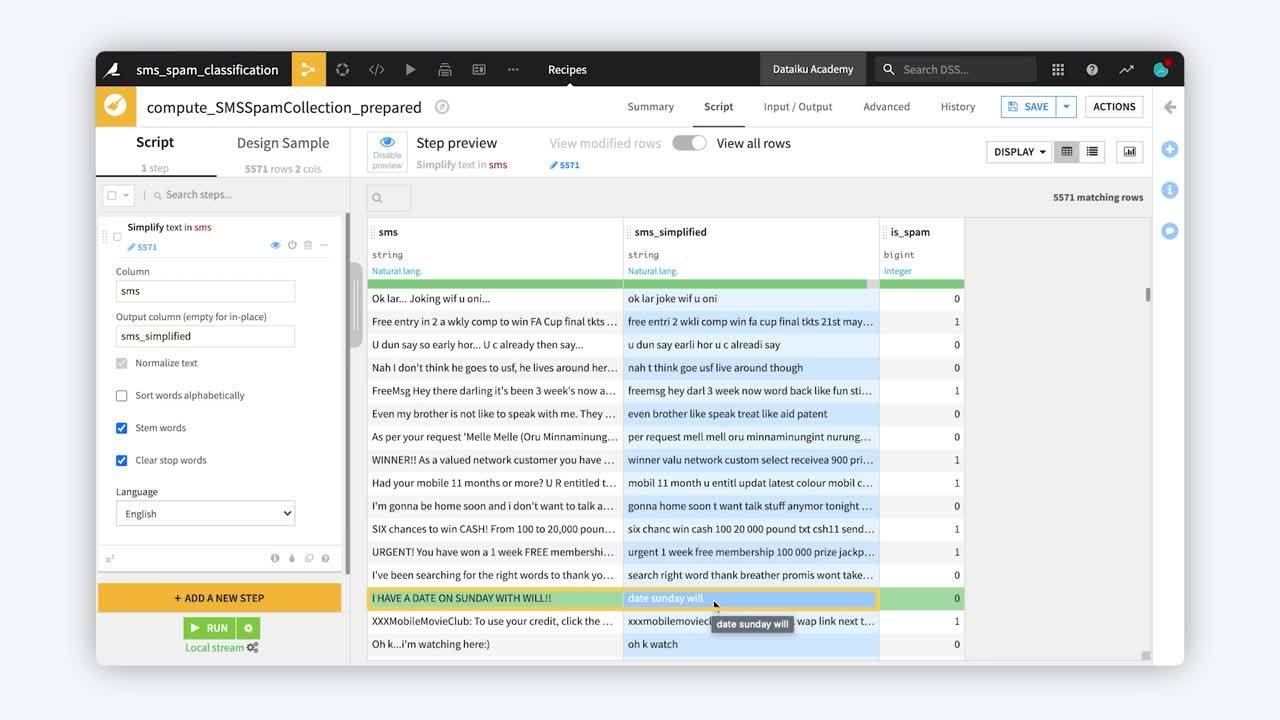
The first, Normalize text, transforms all text to lowercase, removes punctuation and accents, and performs Unicode normalization.
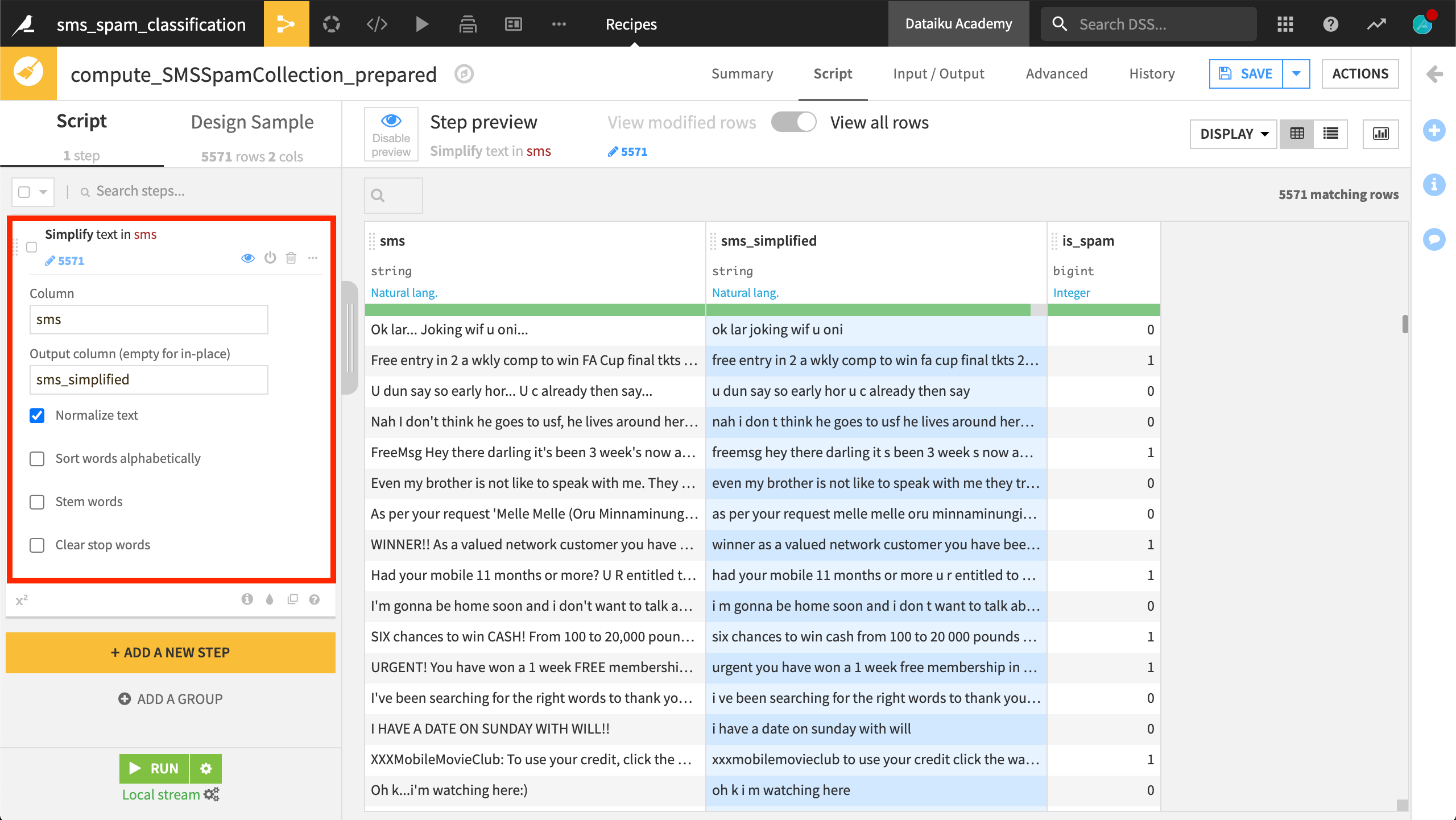
The second, Sort words alphabetically, returns the input string with words sorted in alphanumeric order. This allows for matching together strings written with the same words, but in a different order.
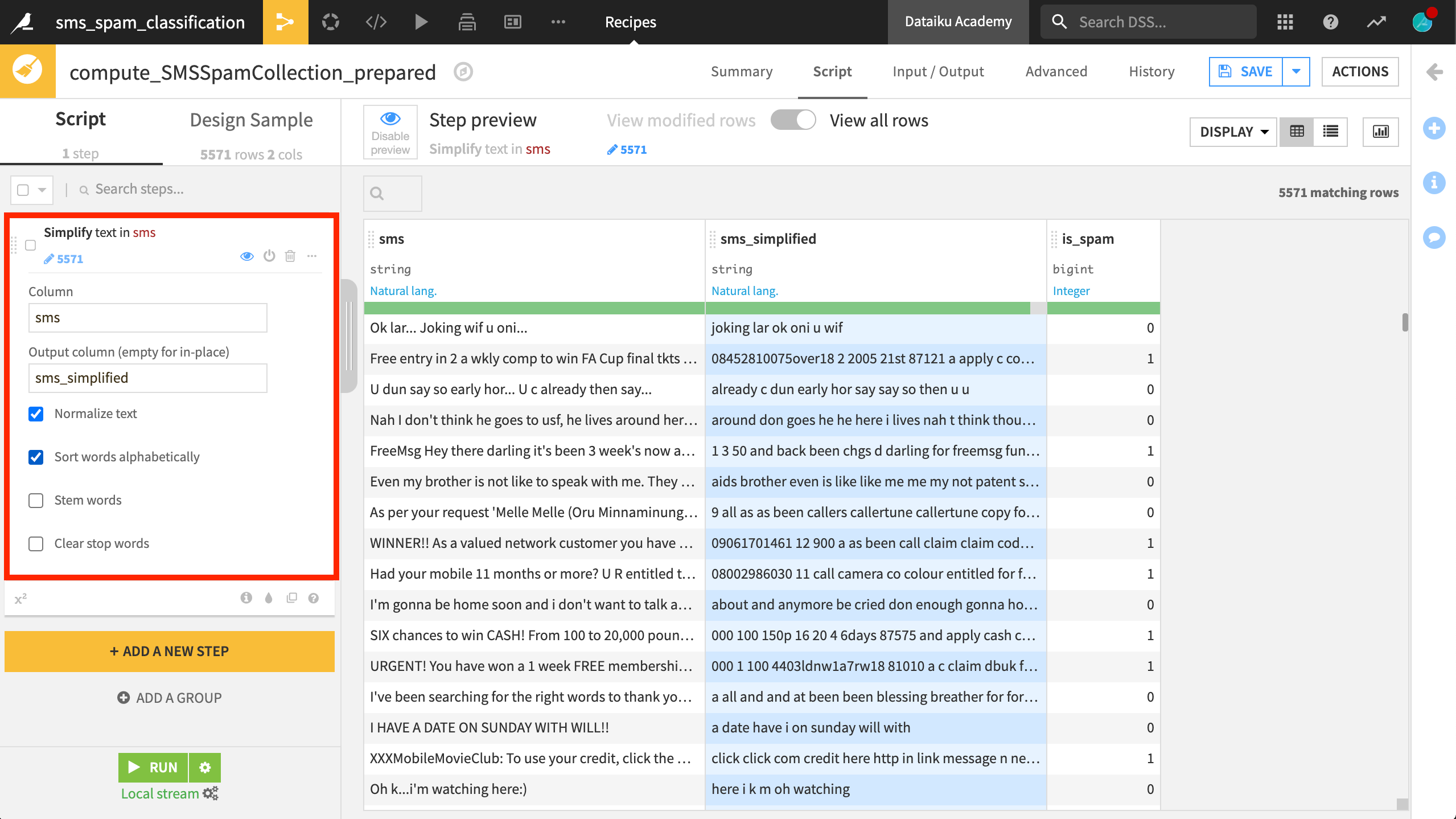
The third option, Stem words, tries to reduce words to their grammatical root. This option is available in several different European languages. Note how a word like watching becomes watch. But it’s not without consequences. Note how remember becomes rememb.
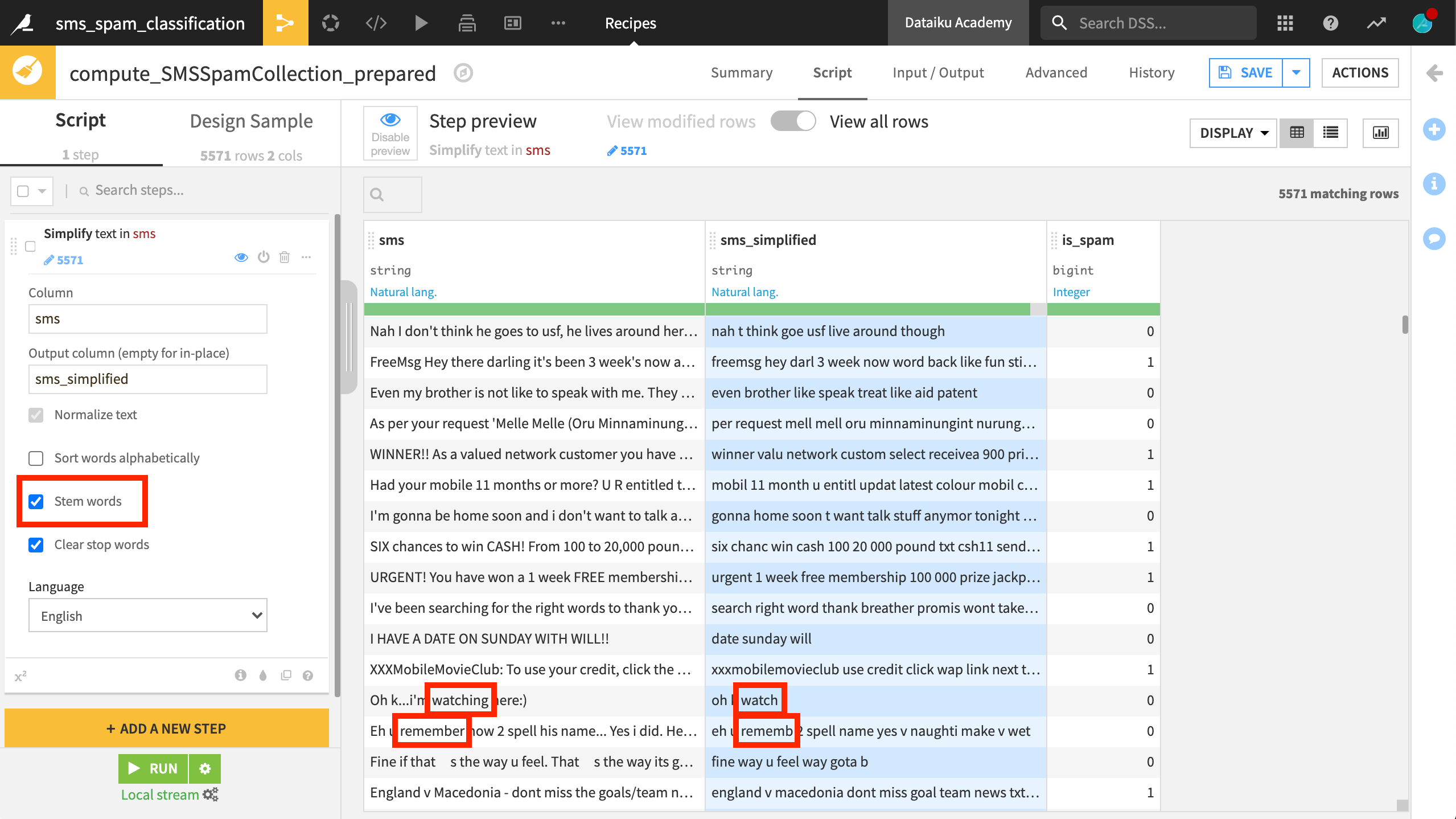
The last option is to remove stopwords. Recall that stopwords are common words like the, I, a, and of that don’t carry much information. Thereby, they create noise in the text data. This transformation is also language-specific.
You can see that a message like I have a date on Sunday with Will becomes just date sunday will.
Other processors#
The Simplify text processor isn’t the only tool to help you prepare natural language data in Dataiku.
Other processors, for example, can help you extract numbers or count occurrences of patterns. The Formula language can also be helpful to build new features from text data.
A built-in function like length(), for example, may provide useful information to classify spam messages.
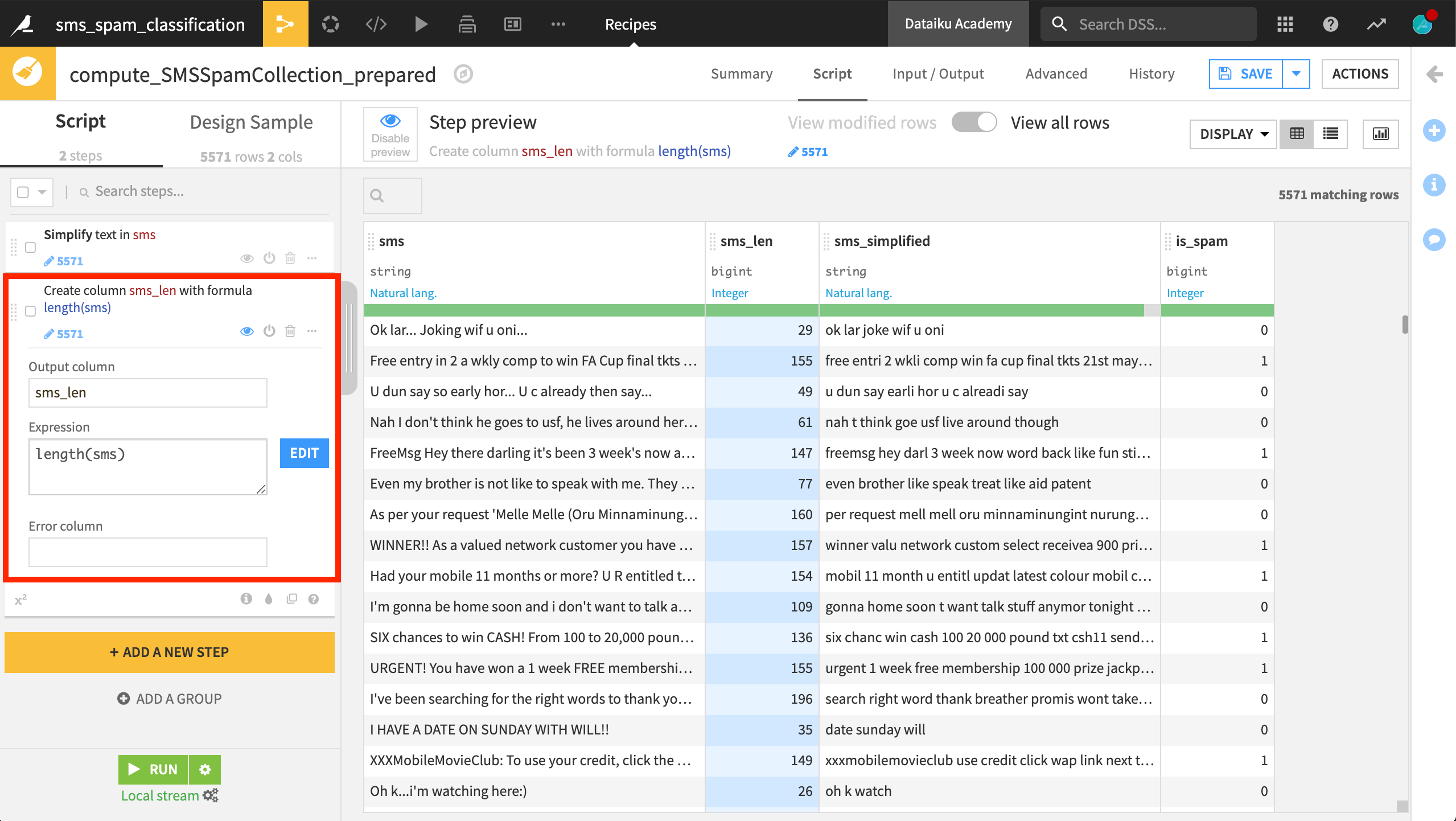
Perhaps a feature like the ratio of the length of the raw SMS to the length of simplified SMS may also contain some useful information.
When you’re satisfied with the data cleaning and preparation steps, you can run the Prepare recipe to apply the steps to the whole dataset.
Next steps#
Thus far, you’ve seen three problems linked to the bag of words approach and introduced three techniques for improving the quality of features. You then walked through how to implement these techniques in Dataiku.
Now, as we’ll show in the next section, you’re ready to start building models!