
Concept | Model comparisons#
In search of the best performance, it’s common to iteratively build a range of models with different parameters. Then, to select the best model for one’s particular use case, one must be able to directly compare candidate models across key metrics side-by-side.
Let’s walk through the process in Dataiku for creating a model comparison, interpreting its information, and using it to select a champion model.
The use case shown in the screenshots below is a credit card fraud use case. The Flow contains a binary classification model to predict which transactions will be authorized (labeled as “1”) and which will fail authorization (labeled as “0”).
Creating a model comparison#
You can create a model comparison by selecting models from:
Saved model versions from the Flow.
Lab models.
Evaluations from model evaluation stores.
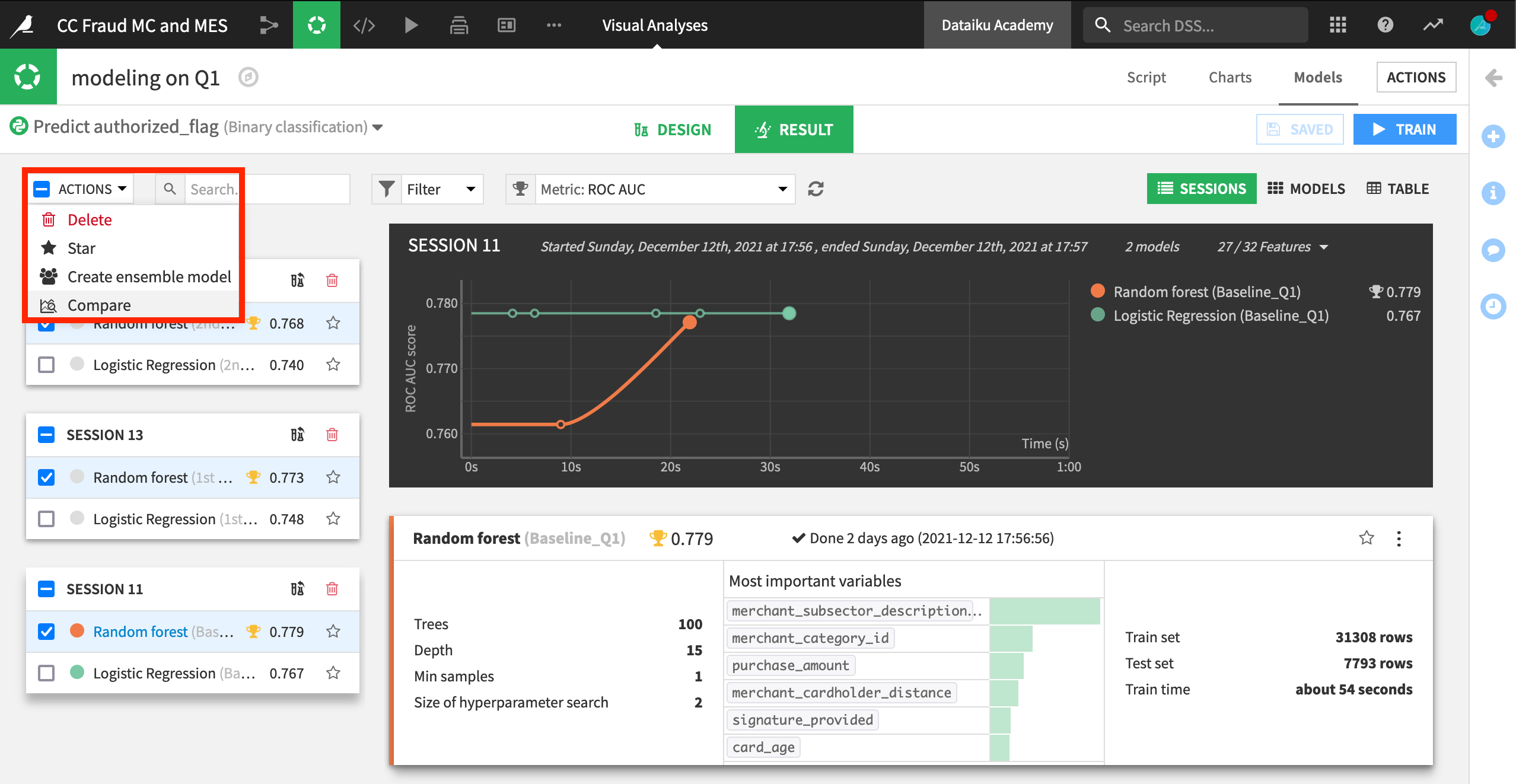
Dataiku users will be familiar with the Models page of a visual analysis. In the screenshot below, we’ve trained many models, but want to compare random forest models from three different sessions side-by-side.
From the Result tab of the Models page within a visual analysis, check the box of the models you want to compare, and then select Compare from the Actions menu.
You have the option of comparing the models in a new or an existing comparison.
Using a model comparison#
Once a user has created a model comparison, you can access it at any time from the top navigation bar in the ML (![]() ) menu > Model Comparisons page.
) menu > Model Comparisons page.
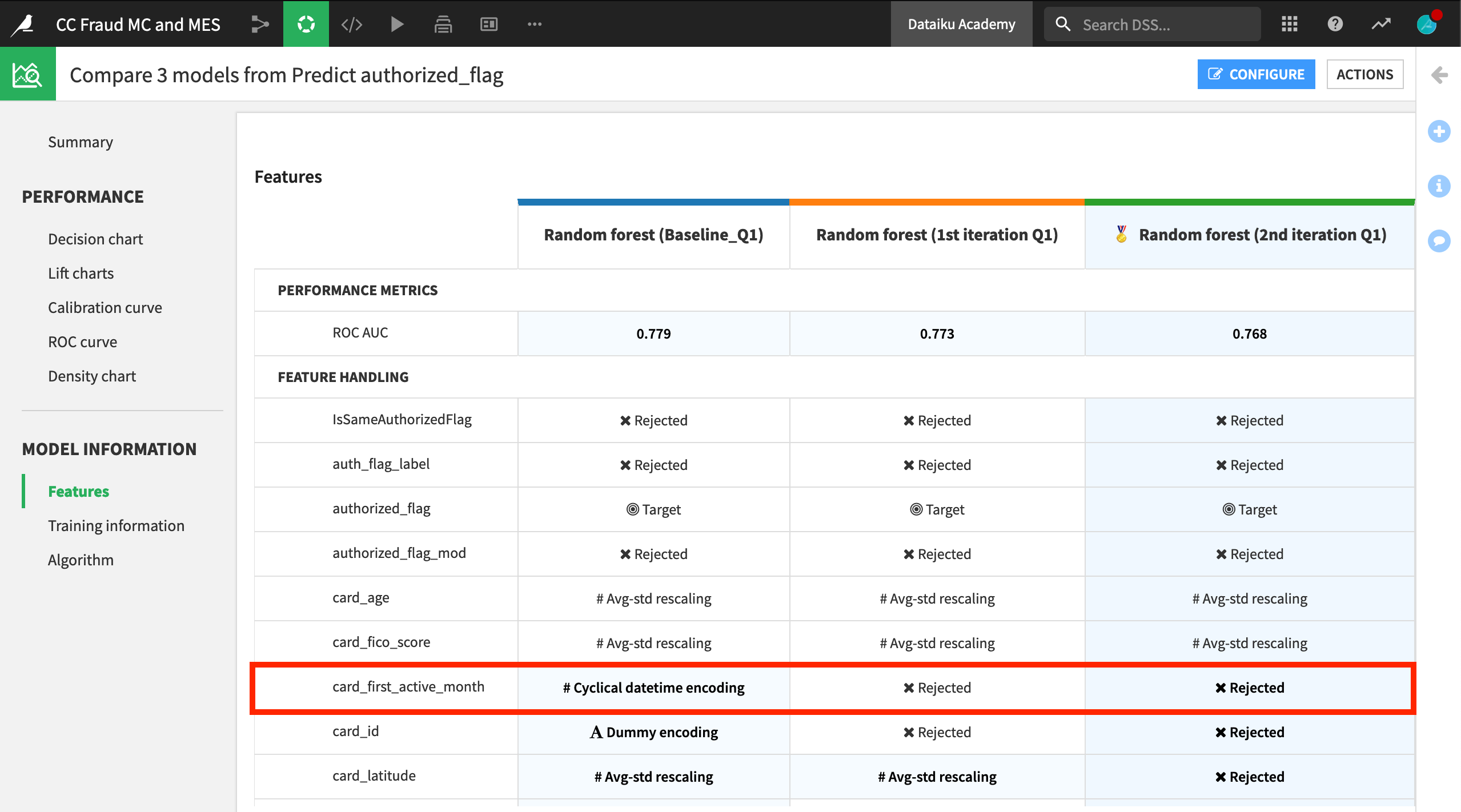
A model comparison includes key information not only about the performance of the chosen models, but also training information and feature handling.
For example, you can see that the baseline model included certain features, such as card_active_first_month, which were rejected in the other two candidate models.
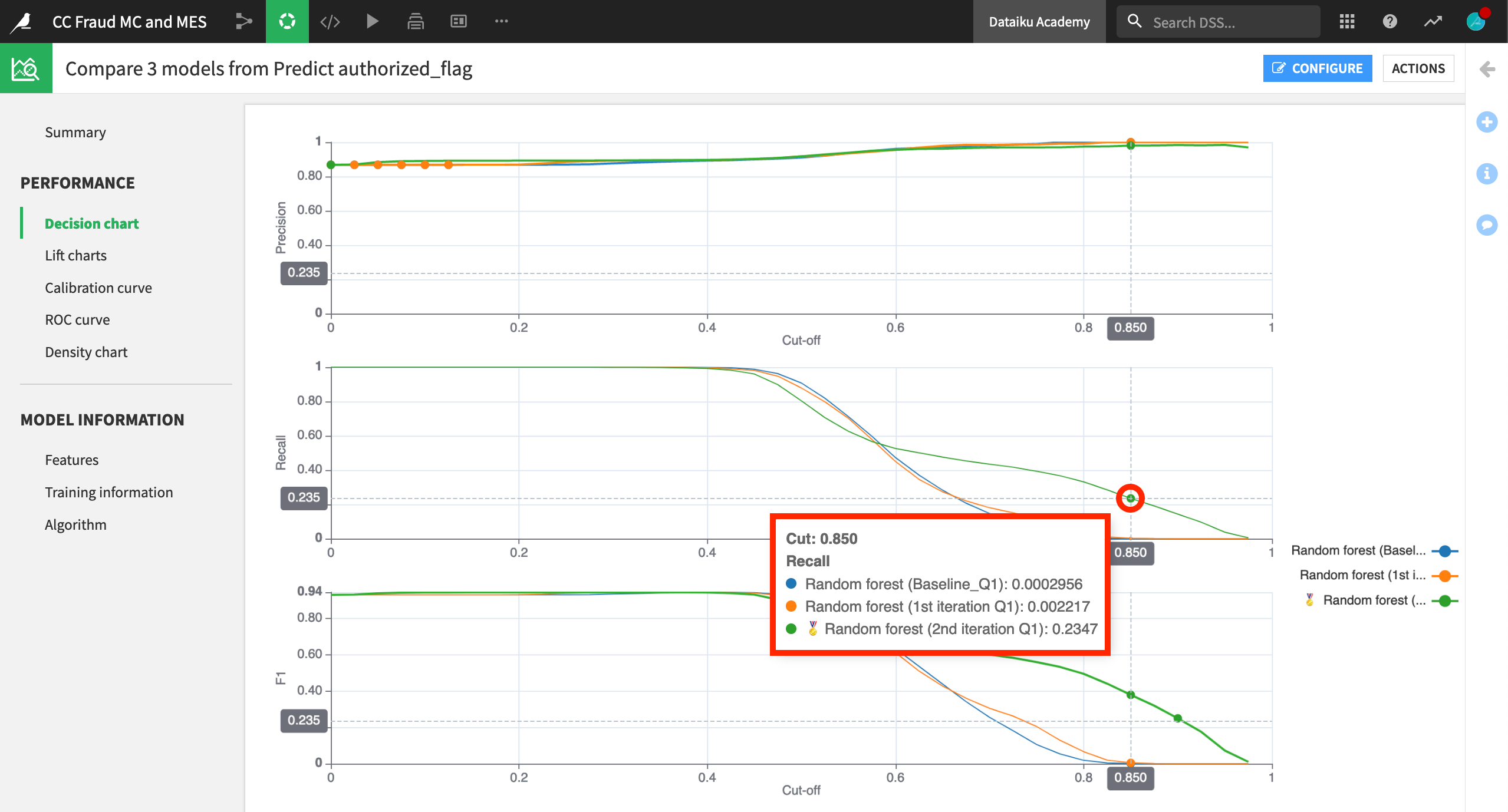
You can now compare many of the same kind of performance visualizations found for any individual model in the Lab. For example, below is a decision chart showing precision, recall, and F1 scores for the three candidate models.
Choosing a champion#
Comparing performance metrics side-by-side makes it easier to choose a champion model.
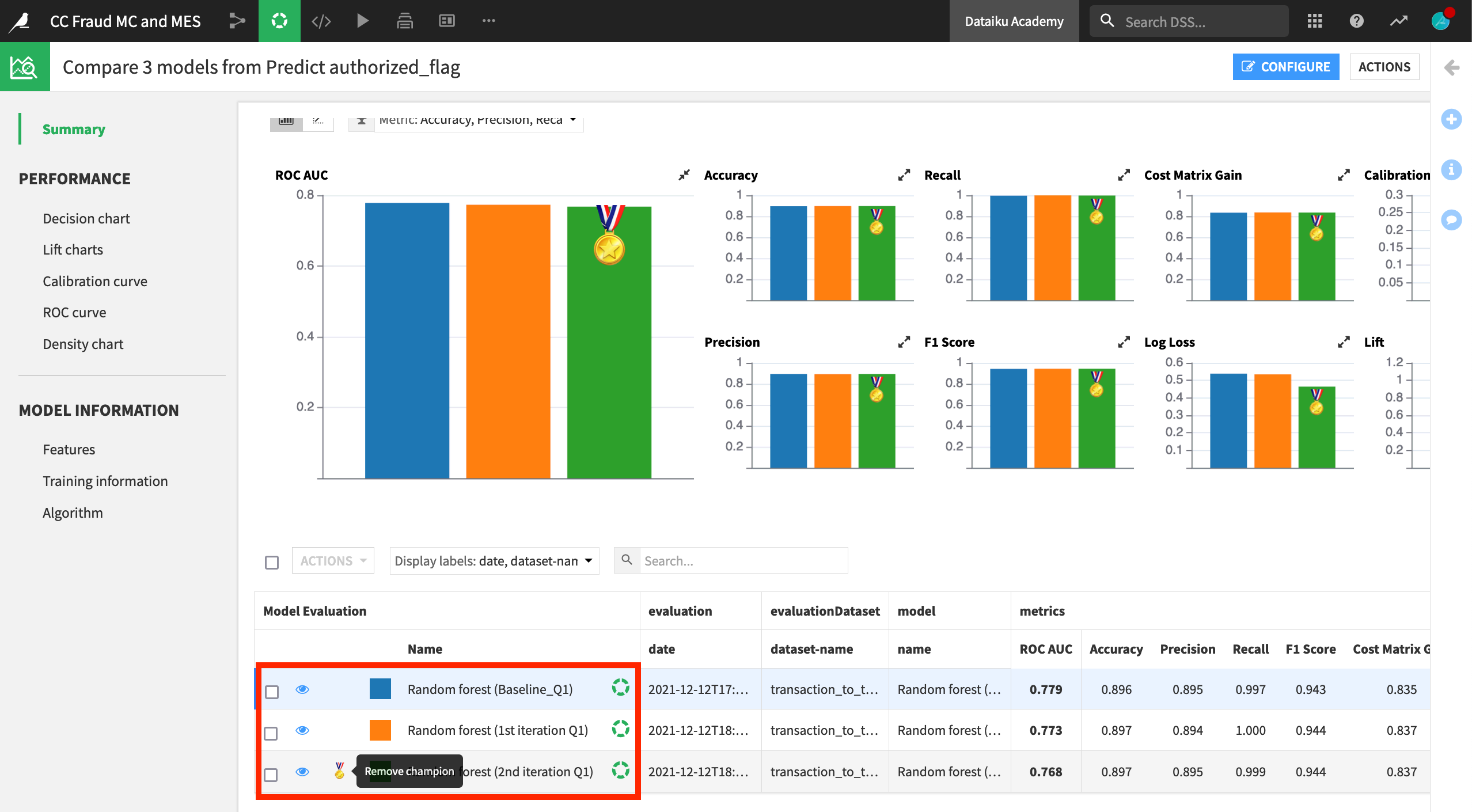
Consider a credit card fraud use case where a fraudulent transaction is labeled as 0 and an authorized transaction is labeled as 1. Having a high precision, which would minimize the number of false positives, may be the most valuable metric. Among these three candidates, the precision metric is quite similar. Therefore, let’s choose the “2nd iteration” model in green, which has the highest recall when precision is also high.
In the Summary panel of the Model Comparison, click to assign or remove the champion status from any model.
Note
In other situations, the saved model deployed to the Flow may already be the current champion. In that case, you can also use the model comparison feature to evaluate the champion against possible challenger models under development in the Lab.
See also
See the reference documentation to learn more about Model Comparisons.