
Concept | Model fairness#
In the framework of Responsible AI, practitioners build reliable and robust models from the vantage point of fairness and interpretability. In fact, the discussion of model fairness is important in each stage of the model lifecycle, from planning to deployment and monitoring!
Thus, you’ll need to learn all about model fairness before you start to build your model. Let’s begin!
Defining fairness#
Fairness is a complex idea that will always vary according to context. It has multiple meanings across law, social sciences, philosophy, and even data analytics. Although fairness is subjective, there are ways to define and measure this socio-technical concept within model building. To do so, we must ask questions like:
What kind of harm do we want to minimize and what kind of benefit do we want to maximize?
What level of analysis is appropriate to determine if a model is fair?
Is the context in which the model is deployed different from our own, and how?
Questions like these ground our technical approach in a social context. They help us think through what kind of impact we want the model to have for both the business and the people who will be affected by it.
We’ll now begin to cover how model fairness can be assessed and measured in a quantitative sense. Note that this is a specific way to assess fairness in models, rather than entire AI systems that would raise different questions around what’s fair when it comes to the implementation or best use of AI.
Types of harm#
To build a fair model, we first need to look at the potential harms caused by unfair models (and, accordingly, by those who built those models). Understanding different types of harm will help us determine the right context and metrics for model fairness later on. Researcher Dr. Kate Crawford distinguishes two types of harm in her NIPS 2017 Keynote presentation:
Harms of allocation, when systems withhold a good or service from certain groups.
Harms of representation, when systems reinforce negative stereotypes about certain groups.
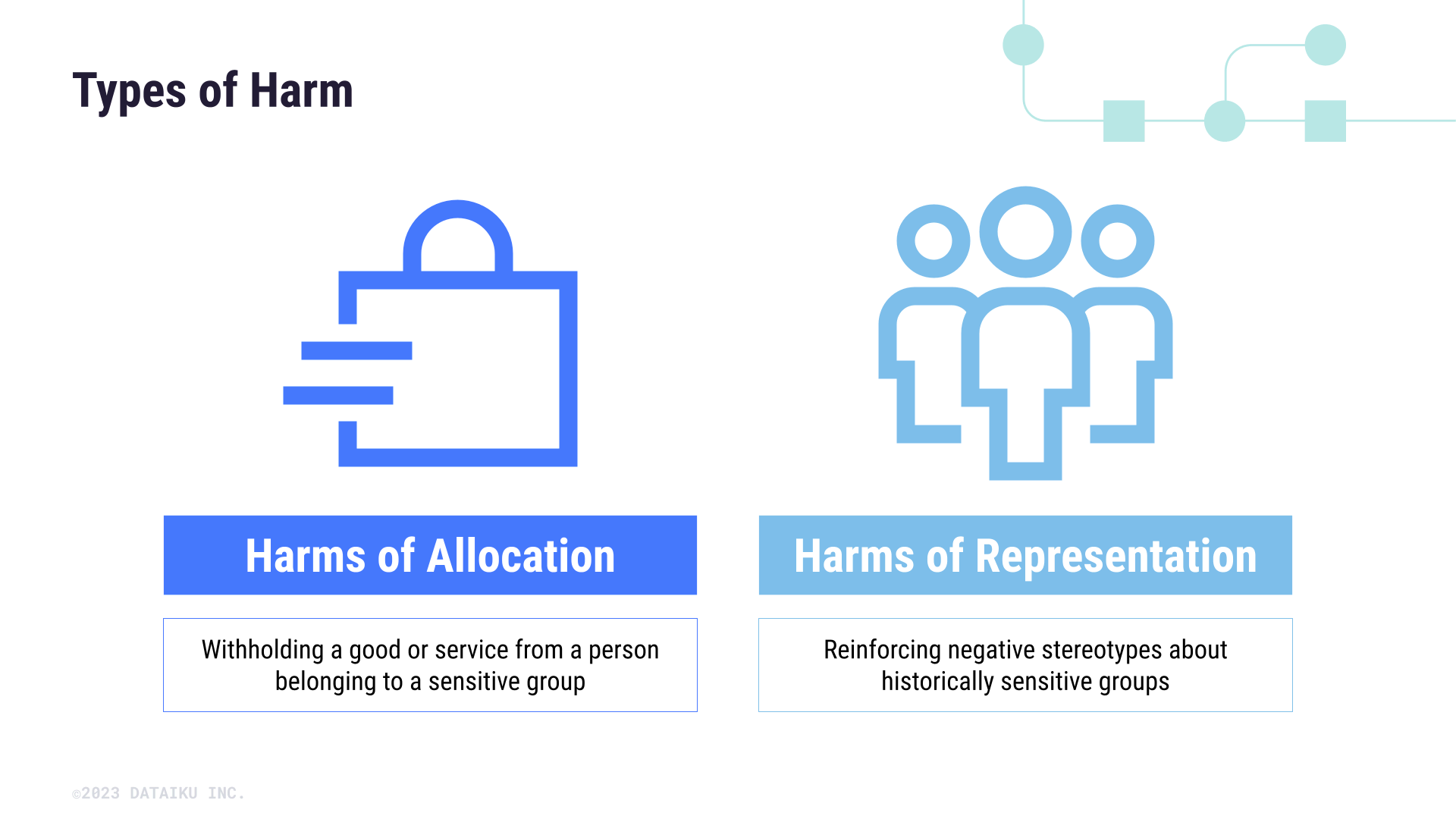
Harms of allocation#
Let’s consider a real-world instance that demonstrates harms of allocation. In 2019, Apple Card applicants discovered men were offered higher credit lines than women with the same credit qualifications. In this case, women weren’t offered the same level of service as men because of their gender (a sensitive attribute). This discrepancy demonstrates that Apple’s credit assessment algorithm caused a harm of allocation.
Harms of representation#
Now, take a look at harms of representation. This type of harm can occur in domains such as image classification, ad targeting, and speech detection. In the realm of image classification, facial recognition algorithms are notorious for their varying accuracy between different racial groups and genders, with highest error rates when classifying Black women. This variation manifests in harm when, for instance, Black people are mistakenly arrested due to facial recognition errors.
Harms in a use case#
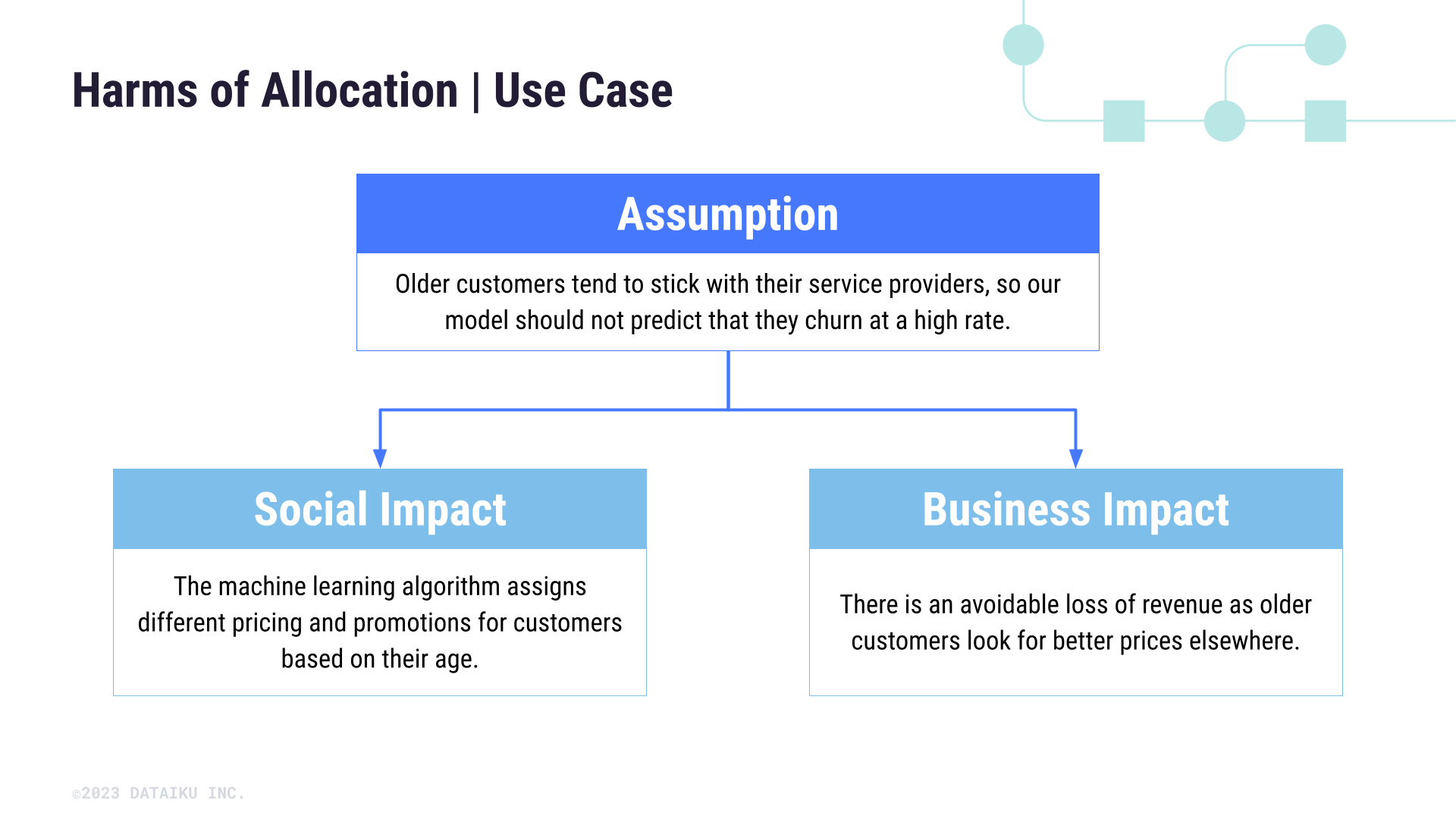
What’s a practical example of harm? Let’s consider a use case where a marketing team is trying to predict customer churn, or likelihood that they will lose the customer.
Assume that there is a common belief that older customers tend to stick with their service providers no matter what. This belief may be assimilated into our model, which can cause the model to predict that older customers won’t churn at a high rate.
This might produce a harm of allocation. In other words, if older customers aren’t expected to churn, the marketing team may decide that they don’t need promotional pricing (a service) to prevent churn.
This line of thinking leads to two real impacts—both social and business—as promotional pricing and avoidable loss of revenue will affect the bottom line.
By thinking through the potential harm from this model before we start experimenting, we can better determine what risks need to be minimized and use that information to guide the development process.
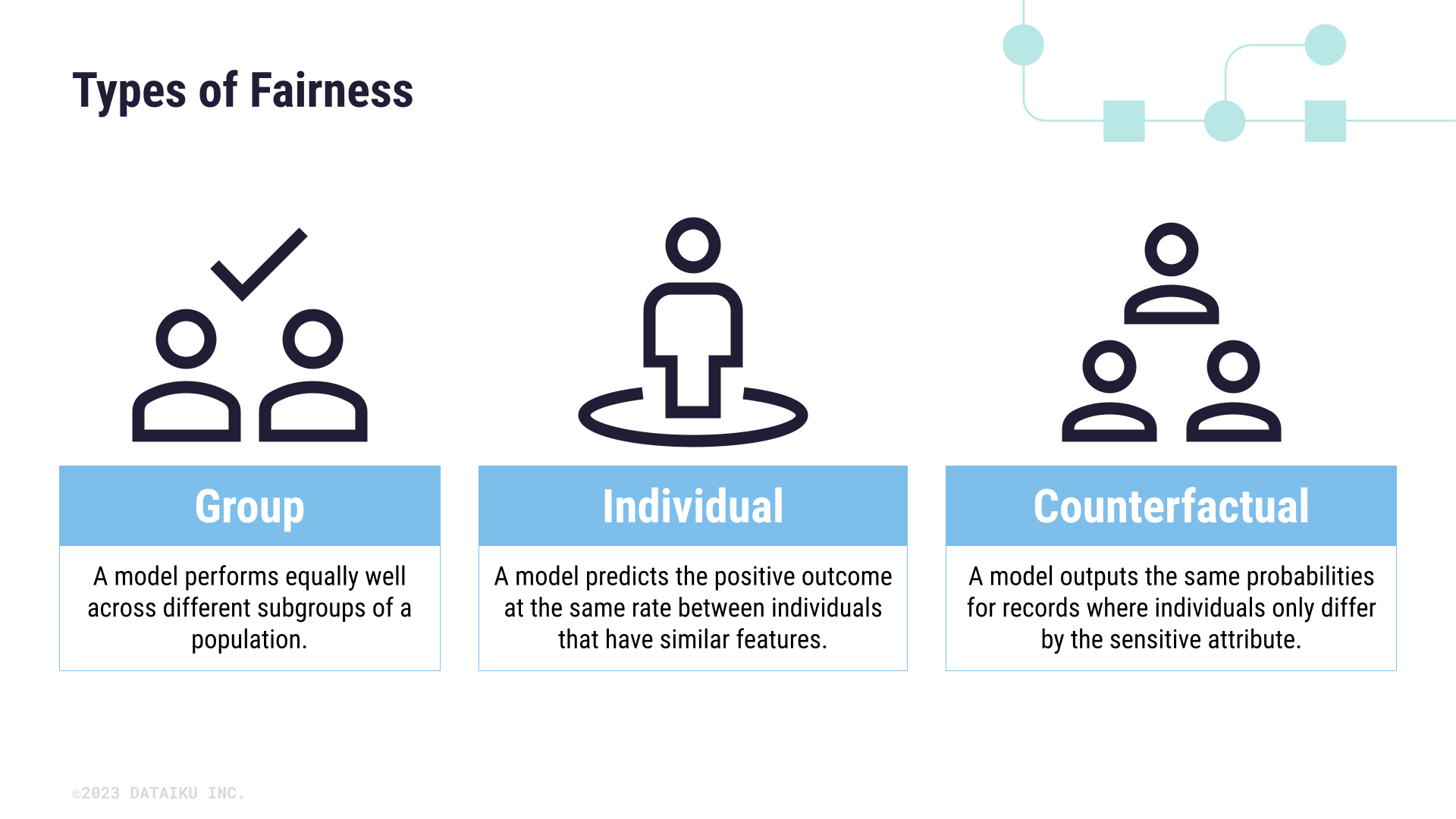
Three types of fairness#
Now that we’re familiar with different types of harms, we need to investigate how they relate to the concept of model fairness. At a baseline, evaluating model fairness involves comparing the outputs of a model across groups, individuals, or features. Therefore, we can categorize model fairness into three different types:
Group fairness: a model performs equally well across different subgroups of a population.
Individual fairness: a model predicts the positive outcome at the same rate between individuals that have similar features.
Counterfactual fairness: a model outputs the same probabilities for records where individuals only differ by the sensitive attribute.
In the case of churn prediction, we’re primarily concerned with group fairness, making sure our model performs equally across people of different age groups. In fact, group fairness is the most common form of fairness used to assess model bias and is most closely linked to existing regulations (for example on financial institutions).
Limitations#
Be aware that it’s impossible to remove or prevent all unwanted biases in a model. However, being able to find, reflect on, and document these biases is important to create more accountable and transparent models. Moreover, in knowing how a model could be biased, we can tweak parameters and settings to minimize bias and maximize fairness.