
Concept | Workflow documentation in a wiki#
You should document your project workflow before deploying it to production. A well-documented workflow:
Facilitates reproducibility.
Eases maintenance.
Supports collaboration between team members.
This article presents steps to document your workflow using a project wiki. Throughout, you’ll notice we’ve used the sample project Detect Credit Card Fraud. Using this sample project, you’ll walk through what could appear in a project wiki. Your own wikis may look different!
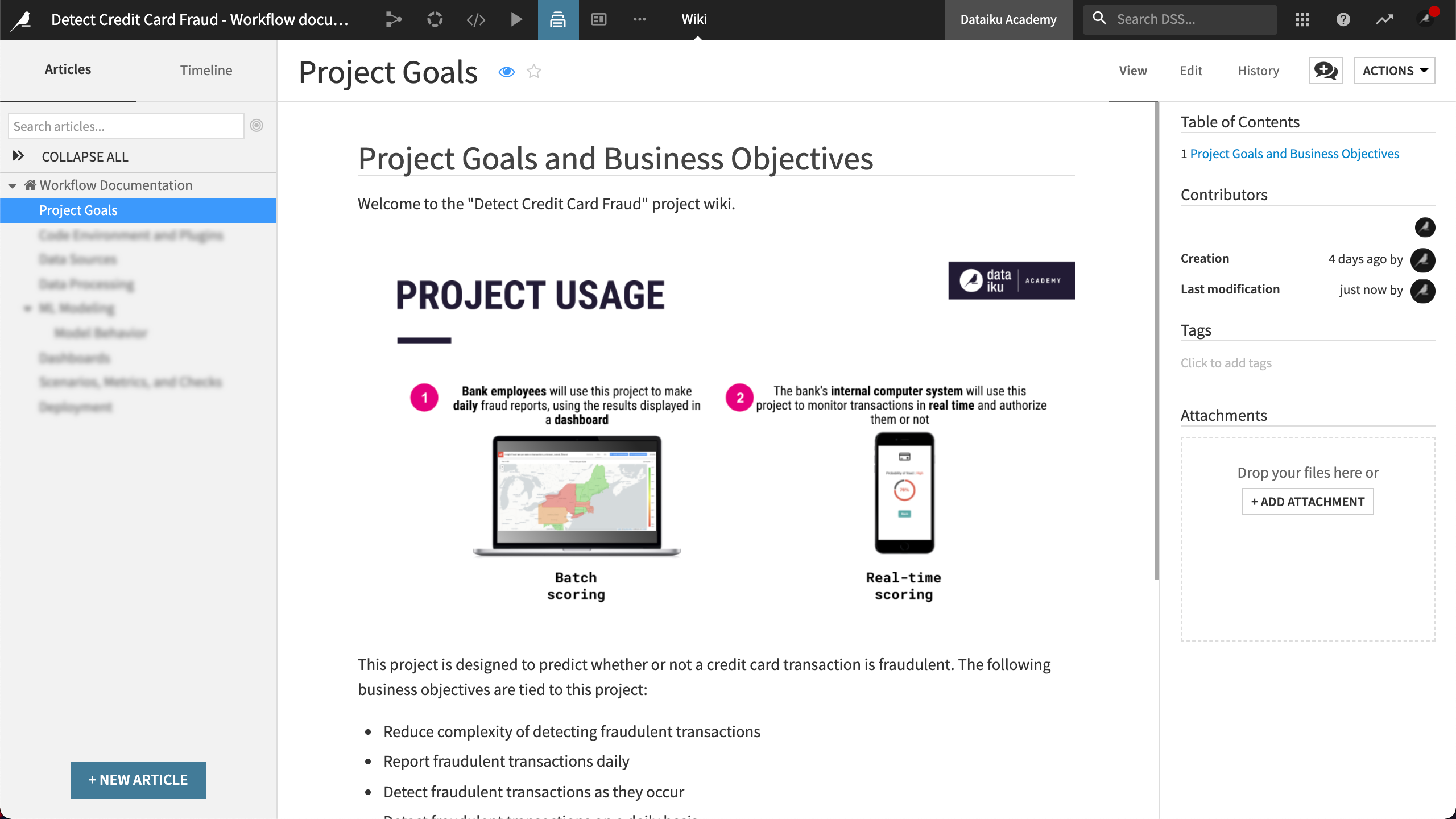
Project goals#
The first section of the wiki documents the project goals. The documentation helps stakeholders understand the purpose of the project.
As an example, the wiki contains information that answers the following:
What’s the purpose of the project, including project goals?
Who will be using the project in production?
What problem does the project solve?
Code environment and plugins#
Next, you’ll document the project’s code environment and plugins to ensure that the development and production environments are identical.
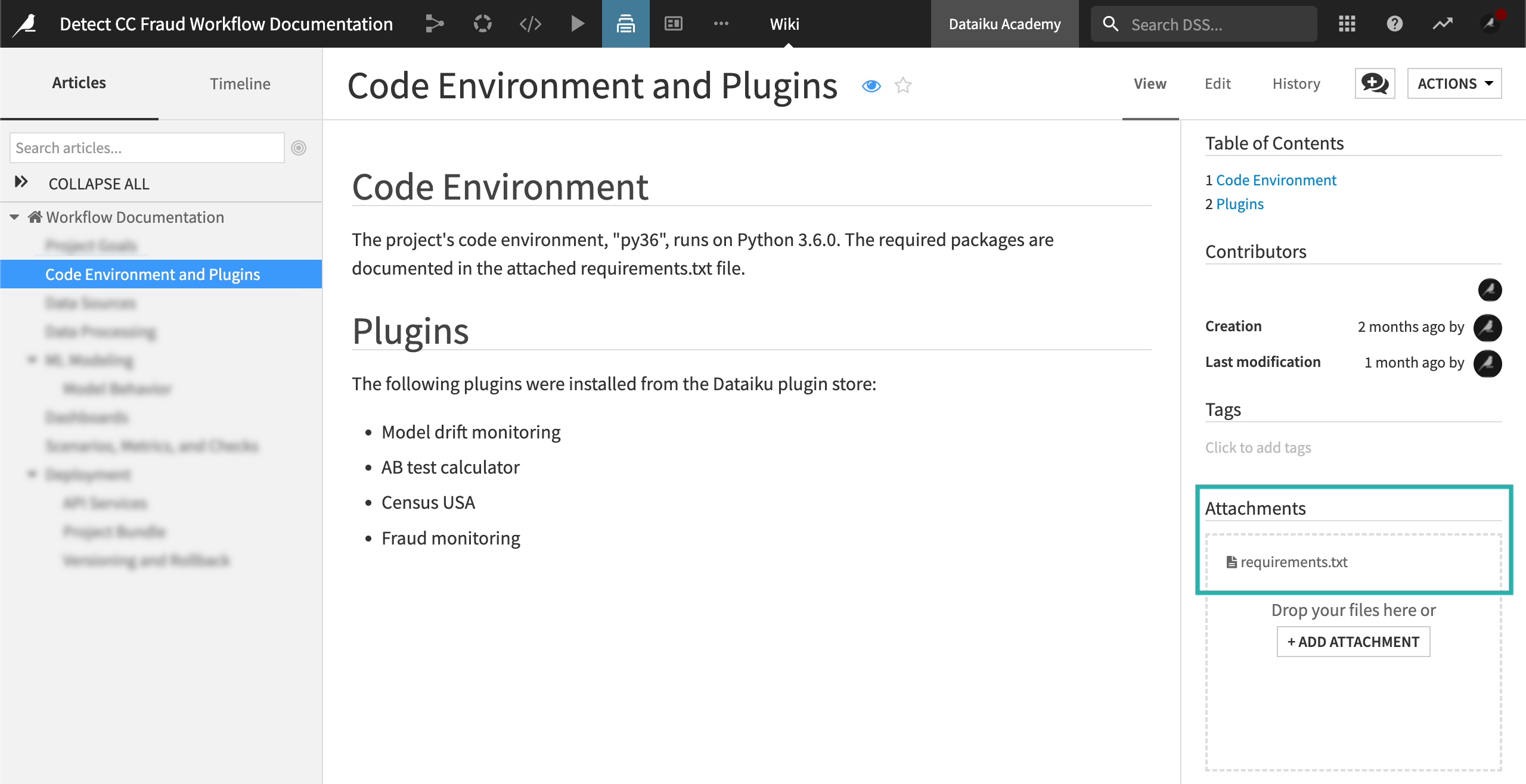
Code environment#
As described in Automation nodes, you can version the code environment on an Automation node. You can link each project bundle to a specific version of a code environment. For these reasons, we’ll want to document the code environment.
The sample project has a single Python code environment. The wiki includes the following information:
Environment name
Python version
Required packages
Plugins#
When you use a plugin anywhere in the project, you’ll need to document it to ensure the plugin is added to the production environment.
In the wiki, we’ve manually listed the plugins used to design the workflow. The plugins were installed from the Dataiku plugin store. Datasets, recipes, processors, custom formula functions, and more can be added through plugins. This makes the use of plugins not always obvious and therefore essential to document.
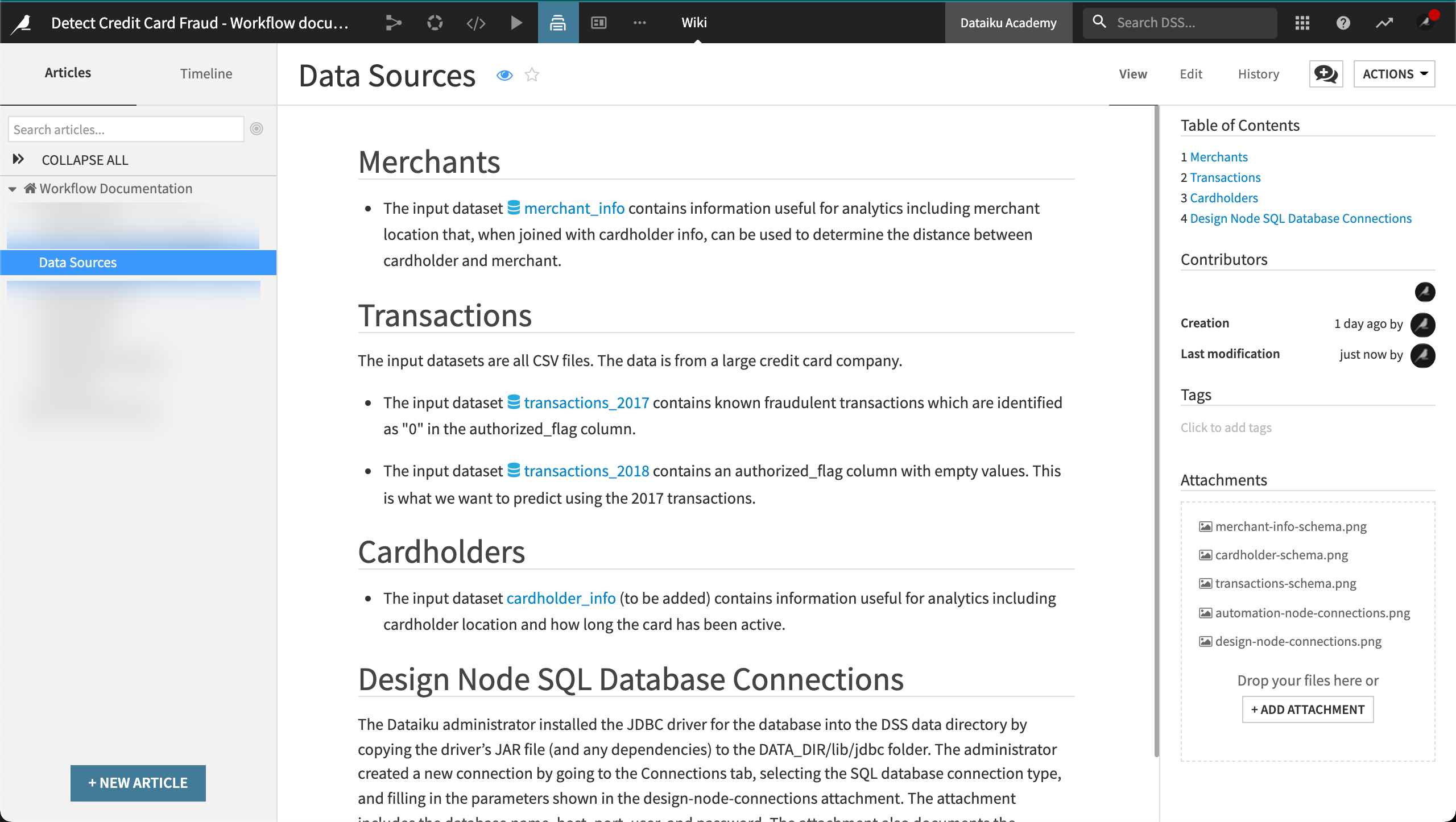
Data sources#
Unexpected behavior can happen when the databases in the development and production environments have different schemas. Documentation of these independent versions of the databases can help prevent unexpected behavior.
Data source documentation should include the following:
Data source
Data availability
Data ownership
Schema
Column description
Data connection configuration between Dataiku and the database
Note
Descriptions can be handy. You can add descriptions throughout your project, including in the project’s homepage, the summary tab of a dataset, column details, and in the code of your custom recipes.
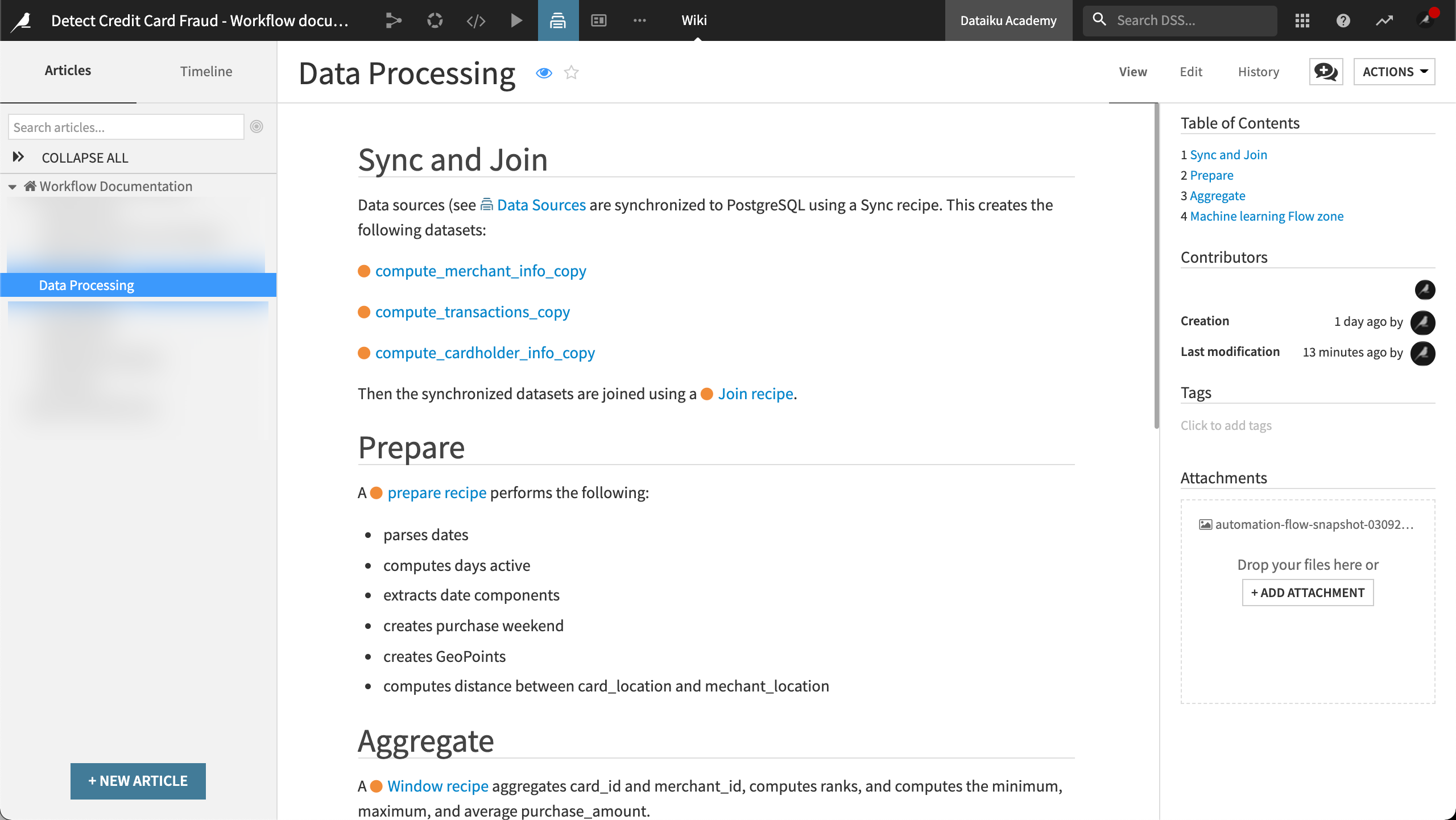
Data processing#
The time-consuming nature of workflow design involves making decisions — decisions that can become lost or forgotten if they’re not documented. Documentation of dataset preparation and computation provides the necessary transparency for maintenance and improvement of the workflow. The documentation could also be used to help reproduce or restore the workflow.
The data processing section documents:
How each input dataset was prepared.
How each output dataset was computed.
ML modeling#
You make many decisions during the development of a machine learning model. You might iterate on a model’s design many times and make multiple design choices with each new iteration. It’s easy to forget the decisions behind each iteration and why each model version exists.
Documentation design decisions provides transparency in the MLOps process. We can take advantage of model documentation features in Dataiku to generate machine learning model documentation.
Model summary#
The goal for the model summary documentation is to help stakeholders identify the following model information:
The dataset the model was trained on.
What the model does.
How the model was built, tuned, and validated, including which features were selected.
To document the model, we used the Model Document Generator to generate a Microsoft Word™ .docx file. We then attached the file to the wiki.
Note
To use the Model Document Generator, you must set Dataiku up to export images. For more information, see Setting Up Dataiku Item Exports to PDF or Images.
Model behavior and monitoring#
The goal for the model behavior documentation is to help stakeholders identify the following model information:
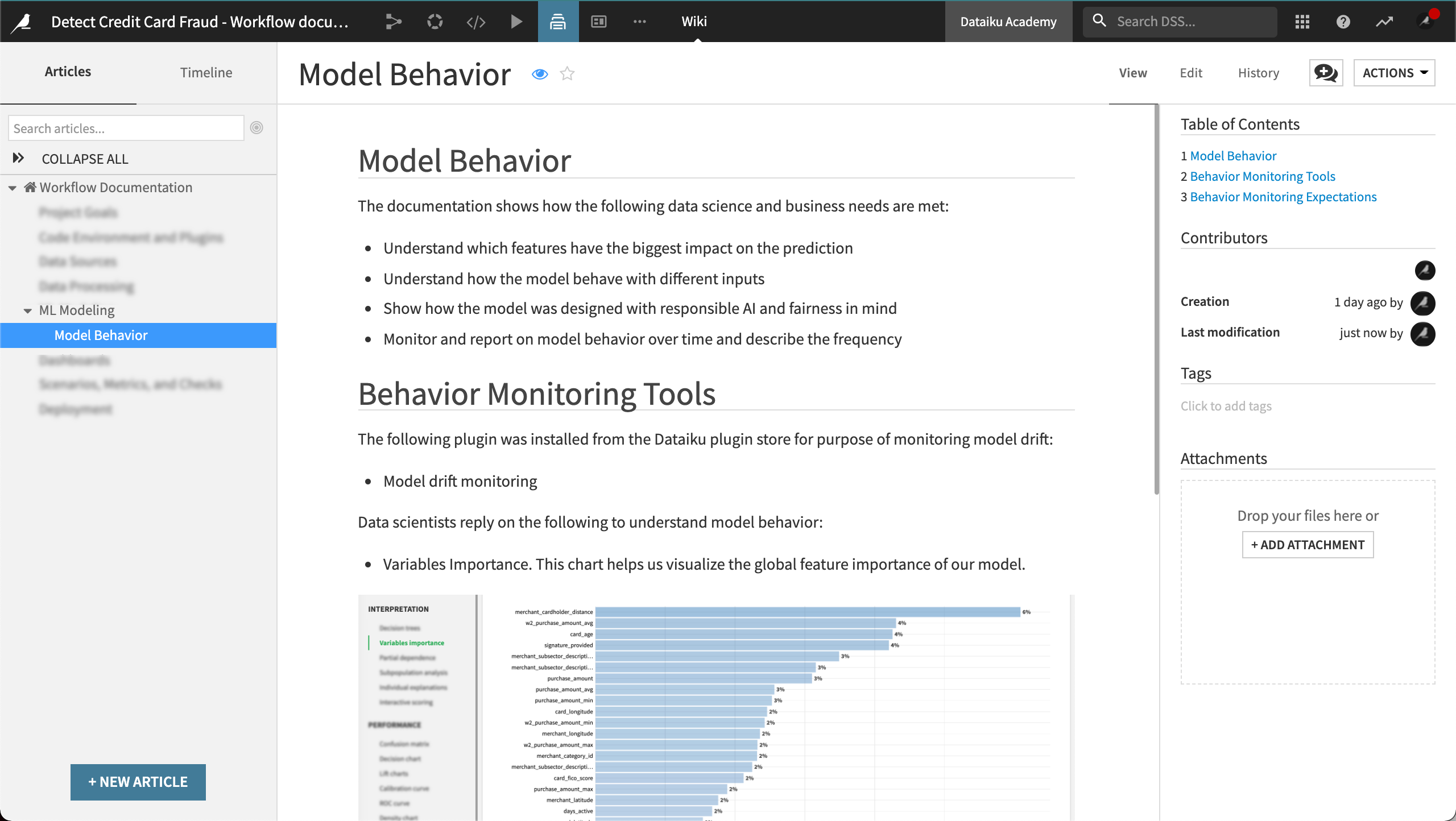
Which features have the most significant impact on the prediction?
How does the model behave with different inputs?
Was the model designed with responsible AI and fairness in mind?
If new data is significantly different from the data used to train the model, the model will likely no longer perform well. Therefore, stakeholders will also want to know how we plan to monitor model behavior, including model drift.
In addition, the documentation describes the reason for monitoring model behavior. This includes the following:
Model monitoring frequency
Expected performance drift (in metrics)
Expected prediction drift
We’ve also documented that the project uses a specific plugin to examine if new data waiting to be scored has diverged from the training data.
Dashboards#
You can document your dashboards. The Dashboards section includes the following information:
Dashboard title and purpose
Steps to create the insights published to the dashboard
Whether or not dashboards are re-created in production
Scenarios#
Scenarios are the basis for production automation. You may wish to add the following information to the wiki:
A diagram of the Flow
Data quality rules and/or model metrics and checks, as applicable
Scenario settings and steps
Scenario trigger
Scenario reporter including the email template
You can also document if the scenario’s triggers are on, off, or left alone when activating a bundle on the Automation node.
Deployment#
Moving into production is an iterative process. There are many reasons for documenting deployment. One reason is being able to roll back to a prior version. For example, stakeholders will want to understand how the project bundle is deployed to the Automation node and how it’s versioned.
For the sample use case, we’ve included the following deployment documentation:
Deployer infrastructure description
API Deployer
API services
Naming conventions
Versioning
Project Deployer
Project bundles
Versioning
Project version control
Metadata, including information about the last change
Next steps#
To help ensure the project components are reproducible in production, you can maintain the wiki throughout the MLOps process. Documentation can help stakeholders overcome some challenges they’re likely to face including training data that can’t be reproduced, scenario failures, and model training failures.
Note
For further reading, visit the reference documentation on wikis.