
Tutorial | Partitioned models#
Get started#
A partitioned dataset is made up of different subgroups of the data that share the same schema. A partitioned model is created from a partitioned dataset.
Partitioned models can sometimes lead to better predictions when relevant predictors for a target variable are different across subgroups (or partitions) of the dataset.
Let’s see how to build one to predict flight delays for two subgroups of data!
Objectives#
In this tutorial, you will:
Create a partitioned machine learning model to predict how much time a given flight will be delayed based on flight characteristics.
Compare the results of a partitioned and non-partitioned modeling session.
Prerequisites#
Dataiku 12.0 or later.
An Advanced Analytics Designer or Full Designer user profile.
Knowledge of the recommended courses in the Core Designer and ML Practitioner learning paths is encouraged.
Create the project#
From the Dataiku Design homepage, click + New Project.
Select Learning projects.
Search for and select Partitioned Models.
If needed, change the folder into which the project will be installed, and click Create.
From the project homepage, click Go to Flow (or type
g+f).
Note
You can also download the starter project from this website and import it as a ZIP file.
Use case summary#
The Flow contains one dataset, flights_data_partitioned, which is sourced from a managed folder named flights_folder with two directories: florida and california.
The rows of this dataset have already been partitioned by the flight destination state, found in the column dest_state. Let’s explore this dataset.
Open the flights_data_partitioned dataset.
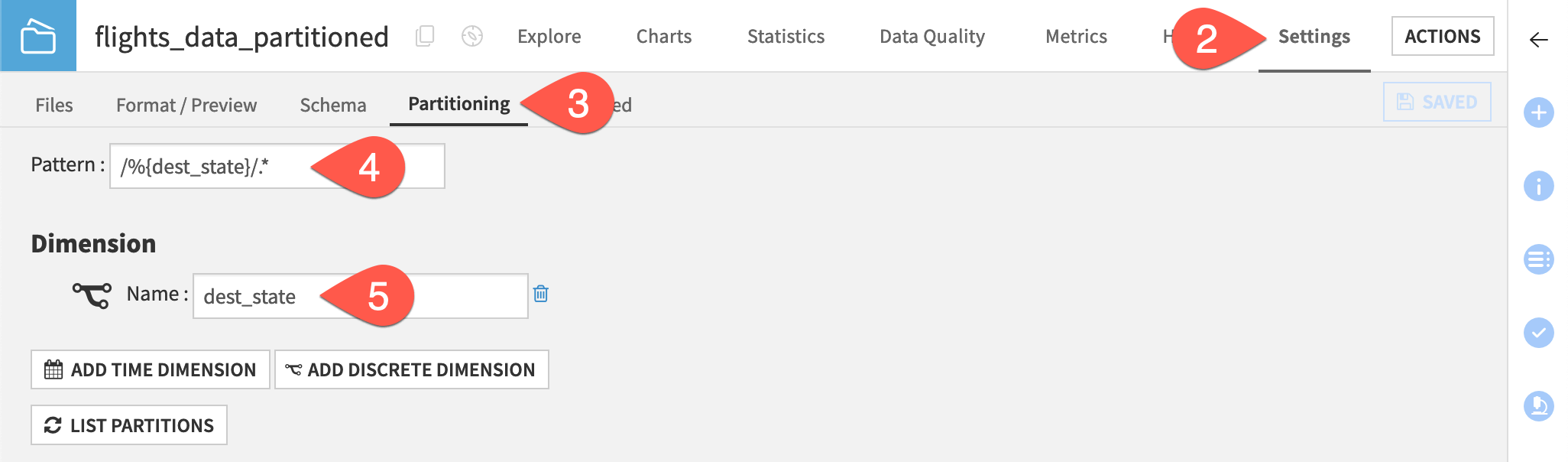
Navigate to the Settings tab.
Go to the Partitioning subtab.
Note that the partitions were created using the pattern
/%{dest_state}/.*.Note that the partitioning dimension is dest_state.
Train a partitioned model#
Partitioning the model by the destination state could help improve model performance if the reasons for arrival delay are different for the two locations.
Because we created our model on a partitioned dataset, we have the option to train partitioned models.
Start with a non-partitioned model#
The goal is to train a partitioned model. However, let’s first create a non-partitioned model on the entire dataset as a benchmark against which we can compare a partitioned model.
From the Flow, select the flights_data_partitioned dataset.
Navigate to the Lab (
 ) tab of the right side panel.
) tab of the right side panel.Select AutoML Prediction from the menu of visual ML tasks.
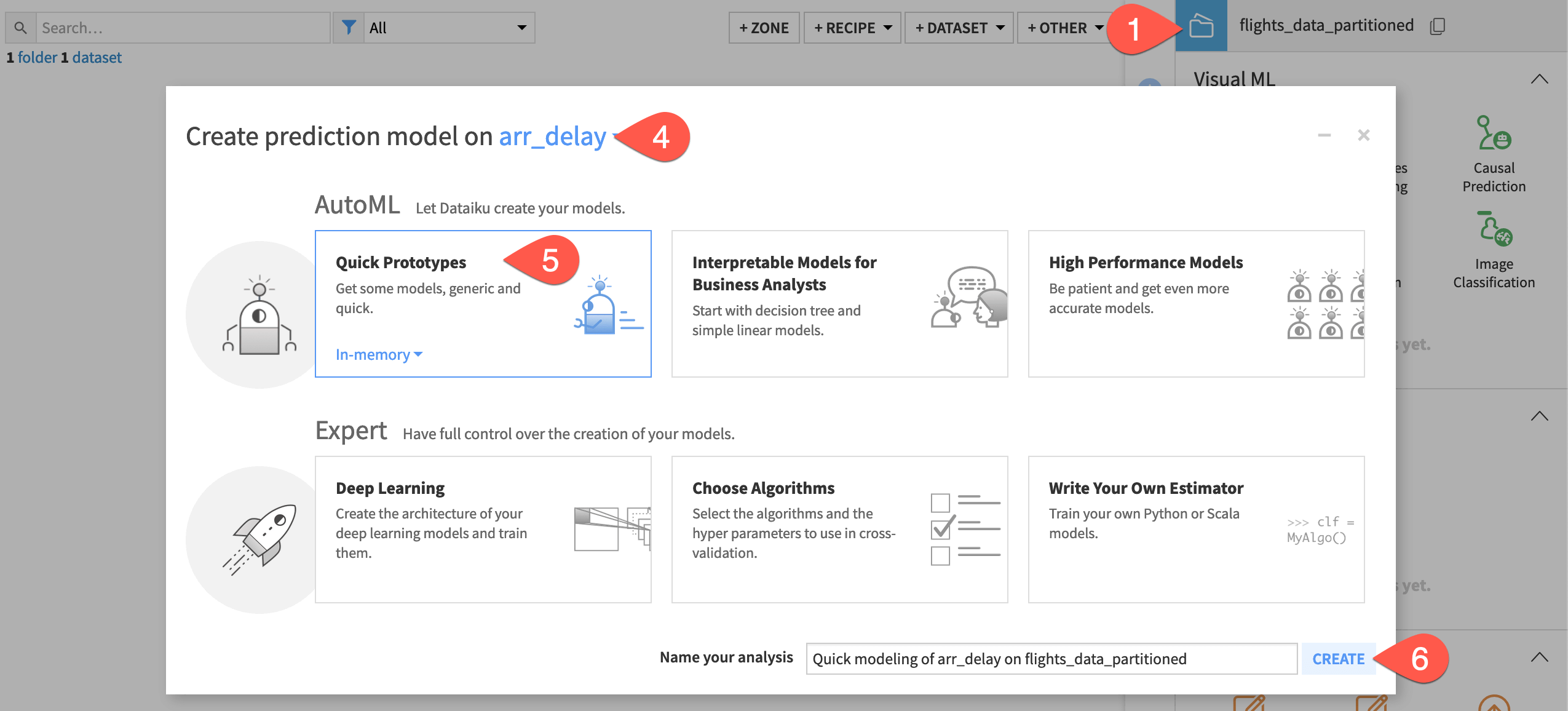
Select arr_delay as the feature on which to create the prediction model.
In the AutoML section, select Quick Prototypes.
Click Create.
Click Train without adjusting any of the Design settings.
Use partitions in a modeling task#
Now that we have this benchmark, let’s train models using the partitions found in the dataset.
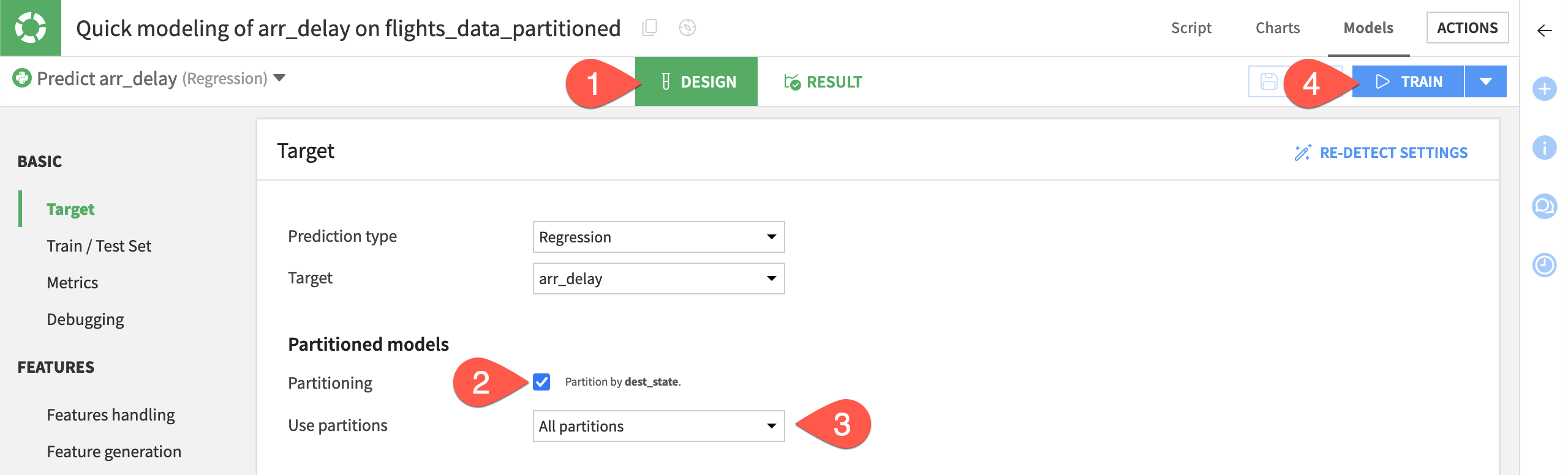
Navigate to the Design tab of the modeling task.
In the Target panel, select the Partitioning checkbox.
For Use partitions, confirm All partitions is selected.
Click Train.
Click Train again to confirm.
Important
If you select multiple algorithms to use for training, Dataiku trains a partitioned model for each algorithm. Each partitioned model consists of one sub-model (or model partition) per data partition. Your results may differ from the results shown.
Evaluate a partitioned model#
We now have two modeling sessions:
Session 1 was trained on the whole dataset even though flights_data_partitioned is a partitioned dataset.
Session 2 (which you initiated) was trained using the partitions.
Let’s observe how the results for a partitioned model differ compared to those for a non-partitioned model.
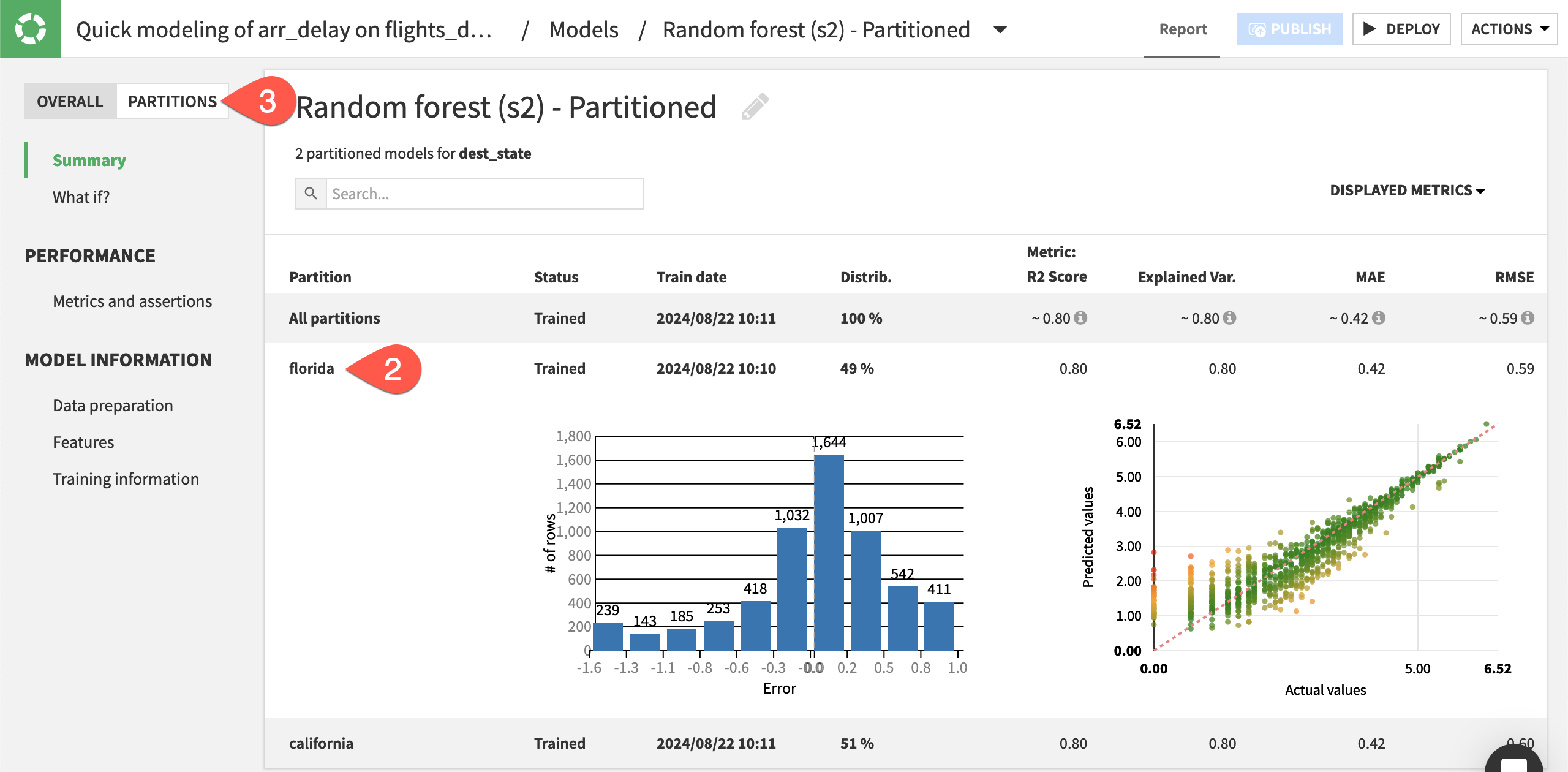
Click on the Random Forest model from the second model training session to view the model report.
From the Summary panel, expand the florida row to view details about this partition.
Click Partitions, and then use the dropdown to view the model report for a specific partition.
Important
Metrics for the overall model are aggregated. When an exact computation isn’t possible, then Dataiku determines the value as a weighted average. The size of each partition (using sample weights, if applicable) determine the weights.
In this example, the partitioned model seems to have performed slightly better than the non-partitioned model. This is because subgroups of a dataset can have dissimilar characteristics that draw different patterns over the features. You can further explore the summary for each partitioned model to investigate whether there are differences between the partitioned model results.
Next steps#
You’ve now seen how to train a prediction model on partitions, or subgroups, of a dataset to test whether a partitioned model can outperform a non-partitioned model.
See also
Learn more in the reference documentation on Partitioned Models.