
Concept | Basics of bias#
Understanding bias is a major component of Responsible AI. Let’s begin with the basics by learning about different types of bias and ways to identify them.
Types of bias#
Think of an iceberg of seen and unseen bias: at the top are common statistical and computational biases that are easy to see. Below the surface, however, are human biases and systematic biases that underpin these biases.
Credit: N. Hanacek, NIST#
We can define each of these biases here:
Systemic biases are defined as the tendency for processes to support certain outcomes, either through historic, social, or institutional means. For instance, the implementation of gender bias through a wage gap , where men are paid more than women for the same job, exemplifies systemic bias.
Human biases are regular errors in thinking that, by extension of systemic biases, manifest in confirmation or implicit bias.
Statistical biases refer broadly to the discrepancies between data (or analytics) and the real world — in other words, when results don’t accurately reflect true population values.
Here are a few examples of each type of bias, some of which you may already be familiar with.

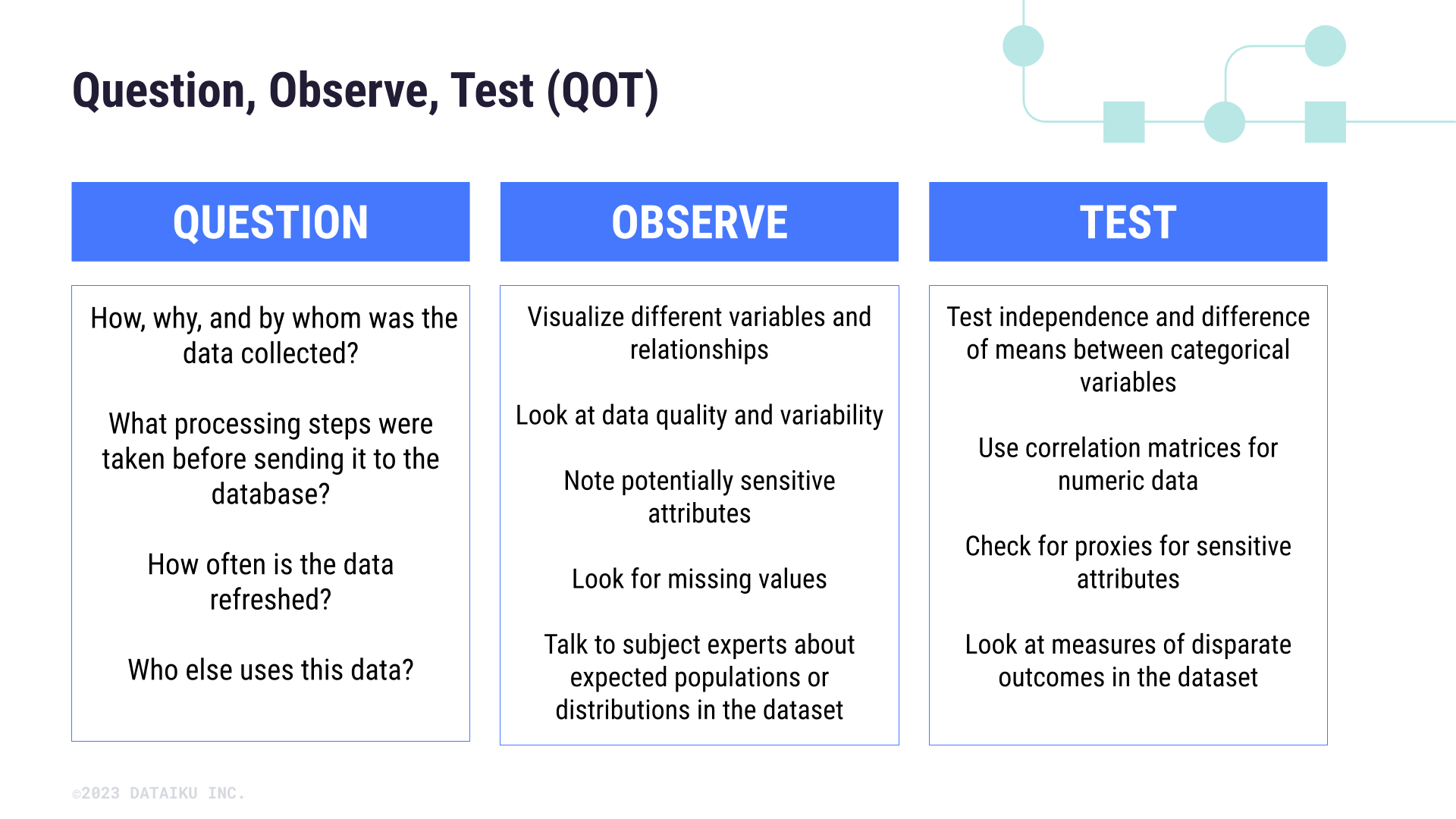
Question, Observe, and Test (QOT) framework#
When beginning a new project, we can follow a question, observe, and test (QOT) methodology to analyze biases in data.
Questions around the nature of the data will provide important context that can inform what kinds of observations and relationships to look for. Based on observations and exploratory data analytics, we can test for different biases using common statistical methods such as independence tests, correlation matrices, and measuring proxies between features of interest.
Below are just a few examples of what we can think about during each stage of the QOT framework.
Mitigating bias#
In most cases, Responsible AI demands more than just identifying and measuring potential biases in a dataset. The next step after finding biases is to determine how to mitigate those issues before moving to the next step of the ML lifecycle.
There are a number of methods to mitigate biases in data, many of which are derived from classic ML methods. For example, in the case of biased datasets, you can create weights based on the expected distribution data. In the case of proxy variables, it’s important to remove them from downstream models and find better measures or indicators of the feature of interest. However, the choices around mitigation are highly context dependent and should be clearly documented for transparency and accountability.