
Tutorial | Fuzzy join recipe#
Get started#
The Fuzzy join recipe performs joins between two datasets when the values of the join keys don’t match exactly.
Objectives#
In this tutorial, you will:
Compare a standard join to a fuzzy join.
Use normalization parameters in a standard Join recipe.
Perform a fuzzy join based on similar but not identical string matches.
Experiment with levels of fuzziness to match your use case.
Prerequisites#
Dataiku 12.0 or later.
Basic knowledge of Dataiku (Core Designer level or equivalent) is encouraged.
Create the project#
From the Dataiku Design homepage, click + New Project.
Select Learning projects.
Search for and select Fuzzy Join Recipe.
If needed, change the folder into which the project will be installed, and click Create.
From the project homepage, click Go to Flow (or type
g+f).
Note
You can also download the starter project from this website and import it as a ZIP file.
You’ll next want to build the Flow.
Click Flow Actions at the bottom right of the Flow.
Click Build all.
Keep the default settings and click Build.
Use case summary#
This project consists of two datasets left-joined using the traditional Join recipe.
Dataset |
Contents |
|---|---|
flight_reviews |
Traveler reviews of flights, including 128 unique arrival cities. |
world_cities |
A table of thousands of cities and their corresponding country around the world. |
flight_reviews_standard_joined |
The output of a standard (equality) left join on the arrival column of flight_reviews and the city column of world_cities, thereby adding the country column. |
unmatched_cities |
Rows in world_cities that didn’t have a corresponding match in flight_reviews. |
Inspect a Join recipe#
The Join recipe performs matches based on equality. In general, the value from the join key column in the left dataset must be exactly the same as the value of the join key column in the right dataset to produce a match.
Examine the results of strict equality matching#
The project’s initial Flow includes an example of strict equality matching.
From the Flow, open the Join (
 ) recipe to inspect the join condition in the Join step.
) recipe to inspect the join condition in the Join step.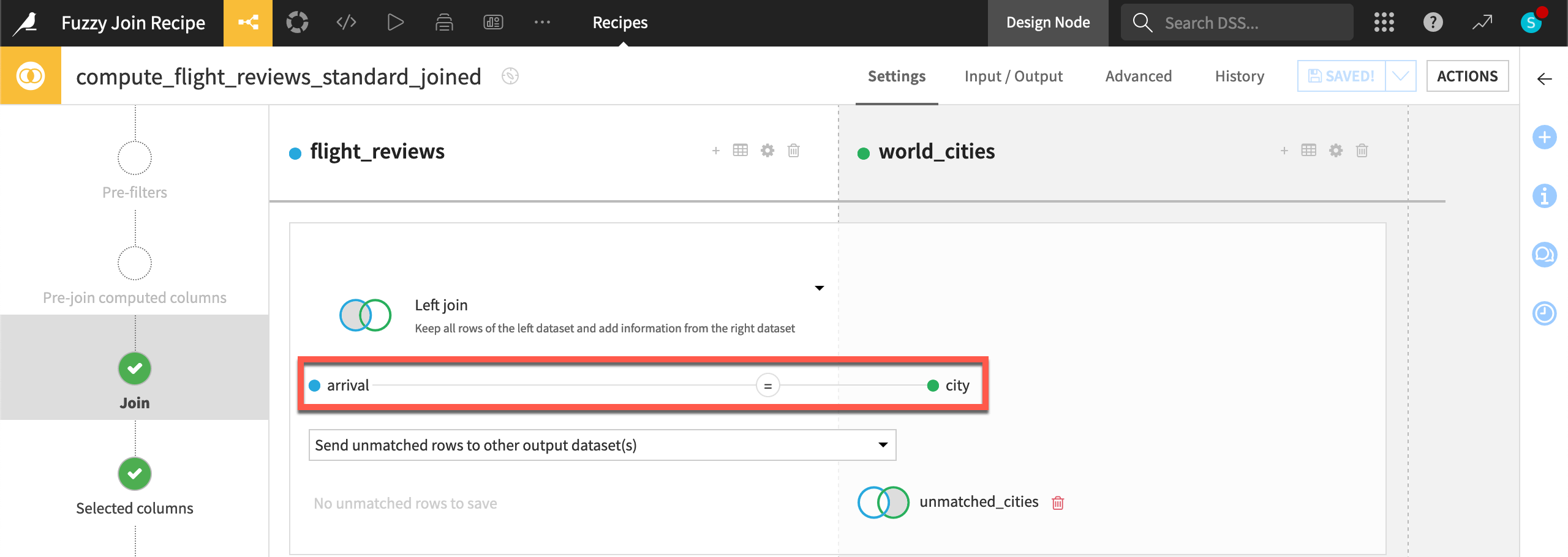
Open the flight_reviews_standard_joined dataset. Compare the arrival and city columns.
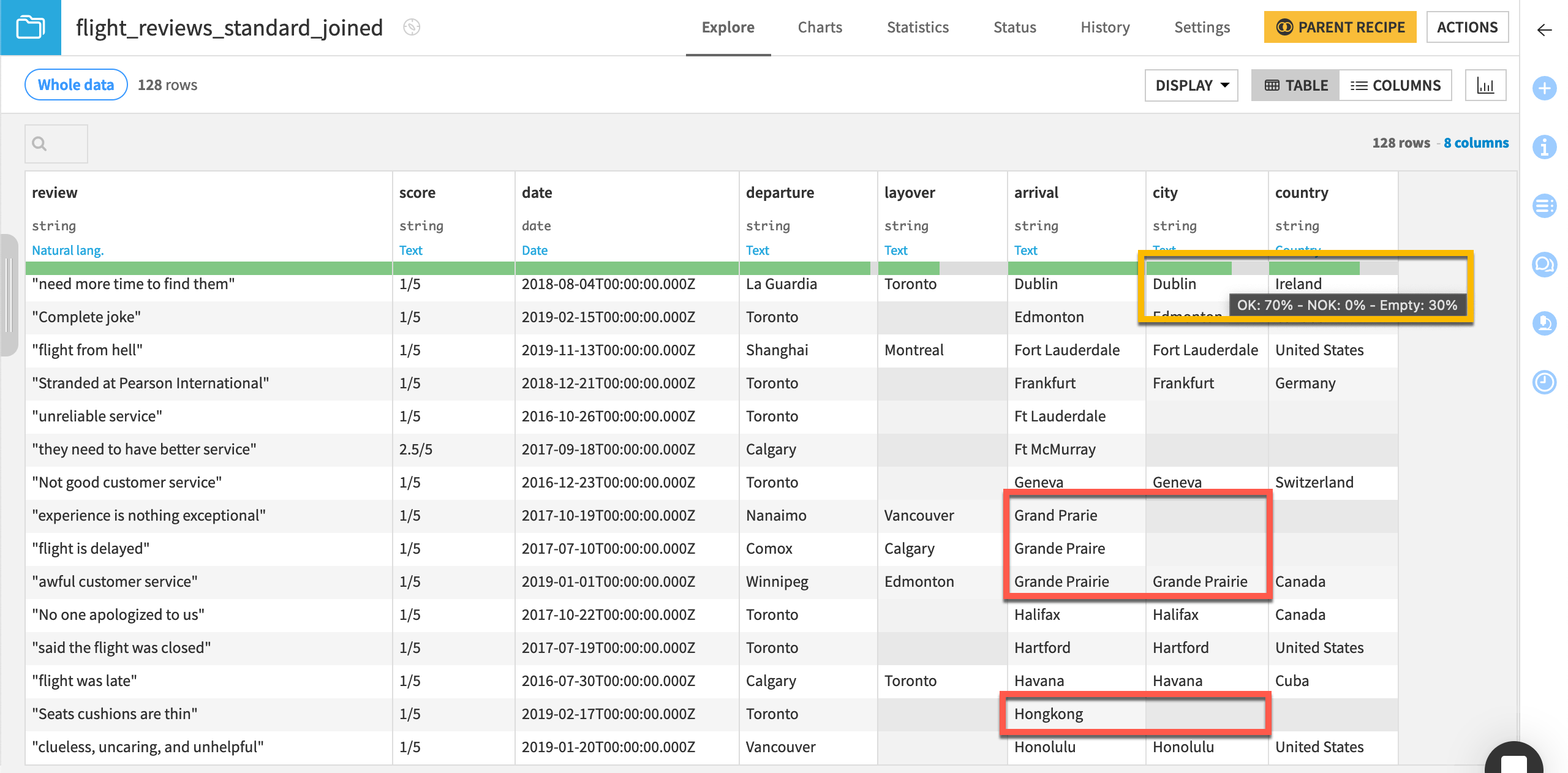
Tip
For any given row, the value of city is either missing or an exact match to arrival. Does this join miss any possible matches? In fact, according to the data quality bar, 30% of the city values are missing.
Normalize text in a Join recipe#
The initial Join recipe found 90 matches based on strict equality. You can find this by using the Analyze tool on the city column of flight_reviews_standard_joined. Look for the number of hapaxes (values appearing only once).
The equality join has some near misses though. For example, the arrival values of Cancun and Hongkong don’t have a matching city value even though the world_cities dataset includes city values like Cancún and Hong Kong.
To create matches for cases like these, you can try setting the condition to ignore case, accents, spaces, and hyphens within a standard Join recipe.
Click Parent Recipe to return to the Join step of the Join recipe.
Click on the join condition to open it, and once more to expand it.
Check the box to Normalize text.
Click OK to close the dialog.
Click Run, and explore the output datasets when finished.
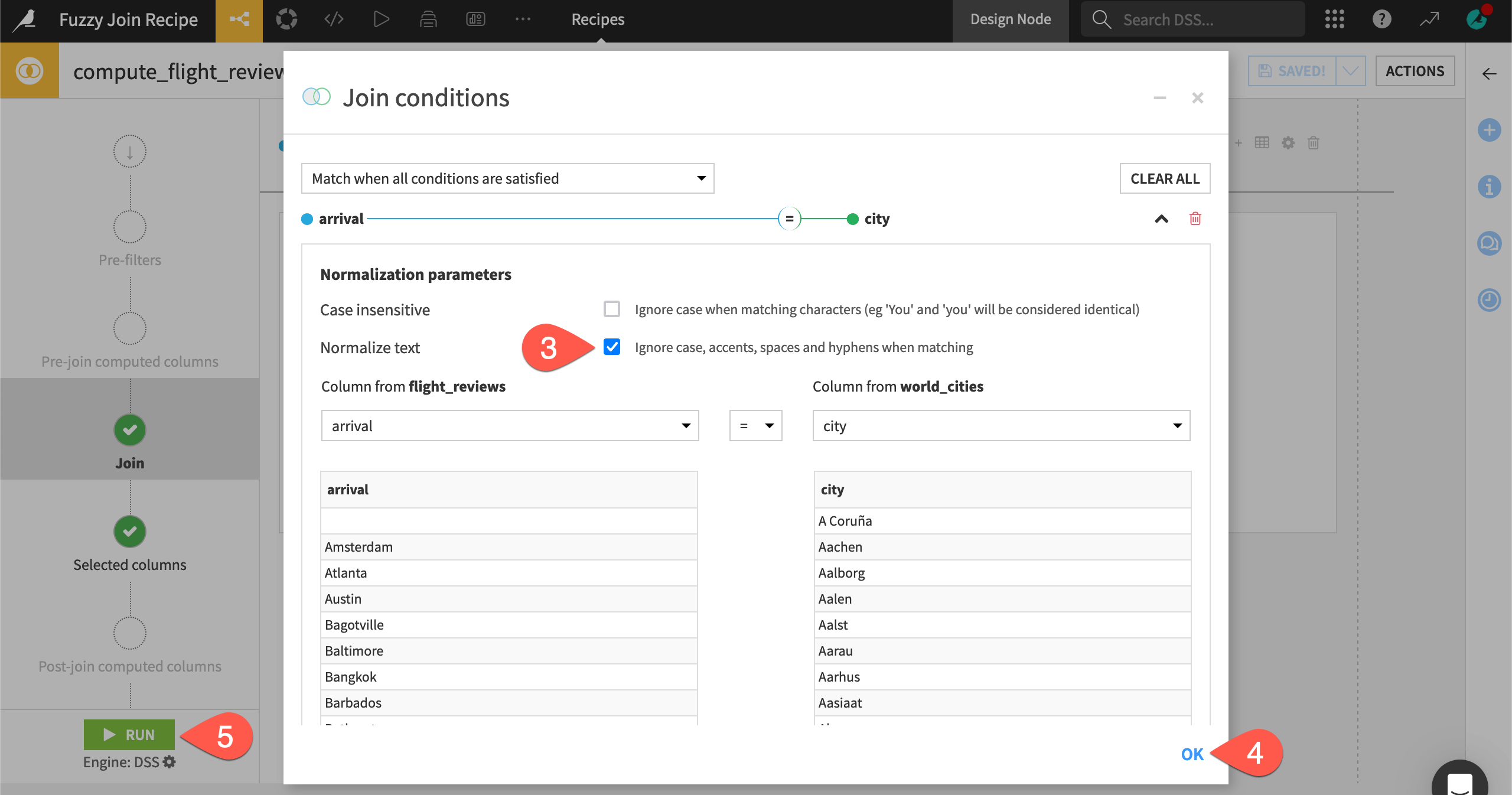
Important
After normalizing text, the recipe found matches for an additional ten cities. Originally at 30%, now only 23% of the city column in flight_reviews_standard_joined is empty. For example, the arrival values Cancun and Hongkong now have matching city values Cancún and Hong Kong.
Another way to do these calculations is to find the difference in row count between world_cities and unmatched_cities (since world_cities has only unique city values).
Fuzzy join datasets on similar text values#
Normalization parameters in the Join recipe introduce an element of fuzziness to the join condition. For some use cases though, this won’t be fuzzy enough!
In flight_reviews_standard_joined, you’ll notice arrival values like Las Vega (presumably meant to be Las Vegas) and Lisboa (presumably meant to be Lisbon). Normalizing text won’t create matches here.
Create a Fuzzy join recipe#
The Fuzzy join recipe can help in situations like this.
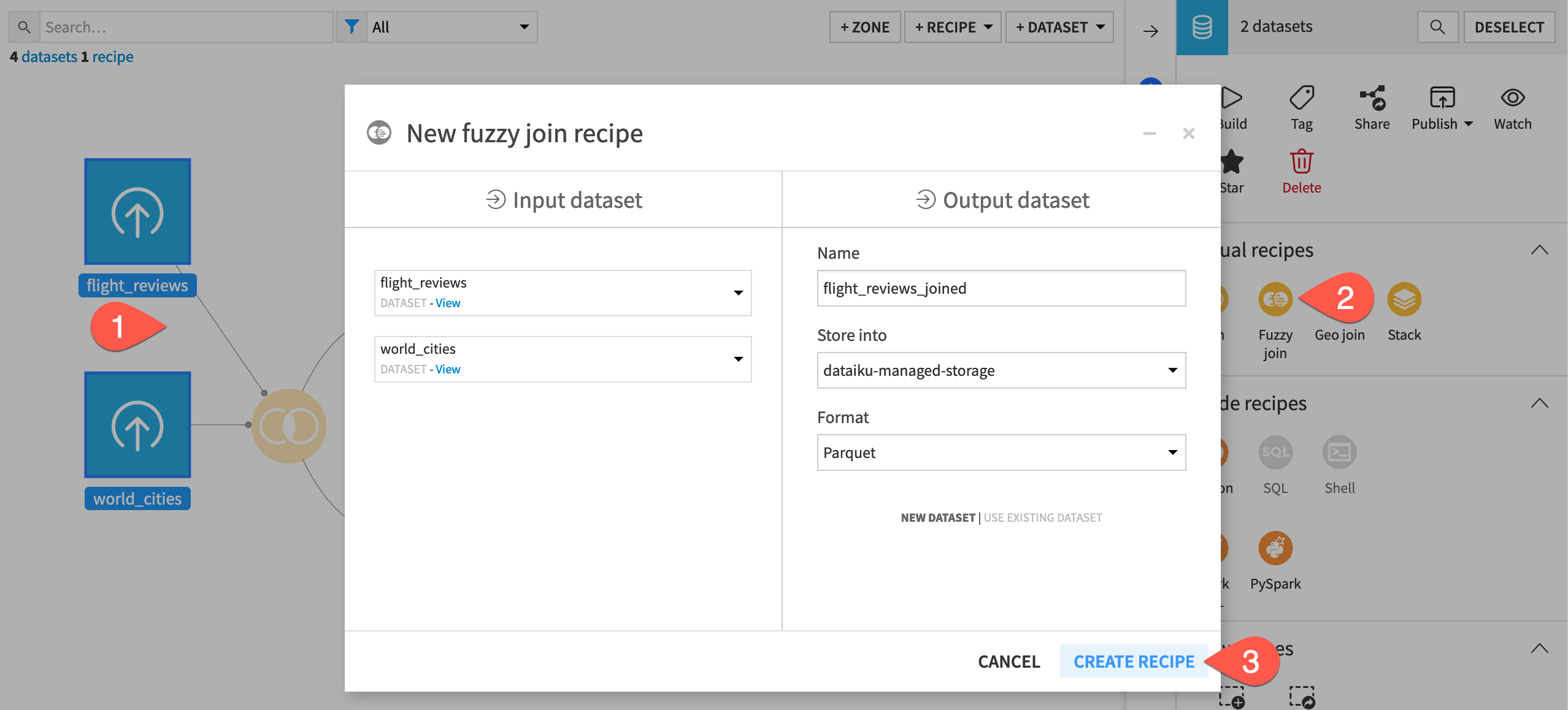
From the Flow, select the flight_reviews and world_cities datasets.
In the Actions tab of the right panel, select Fuzzy join.
Click Create Recipe.
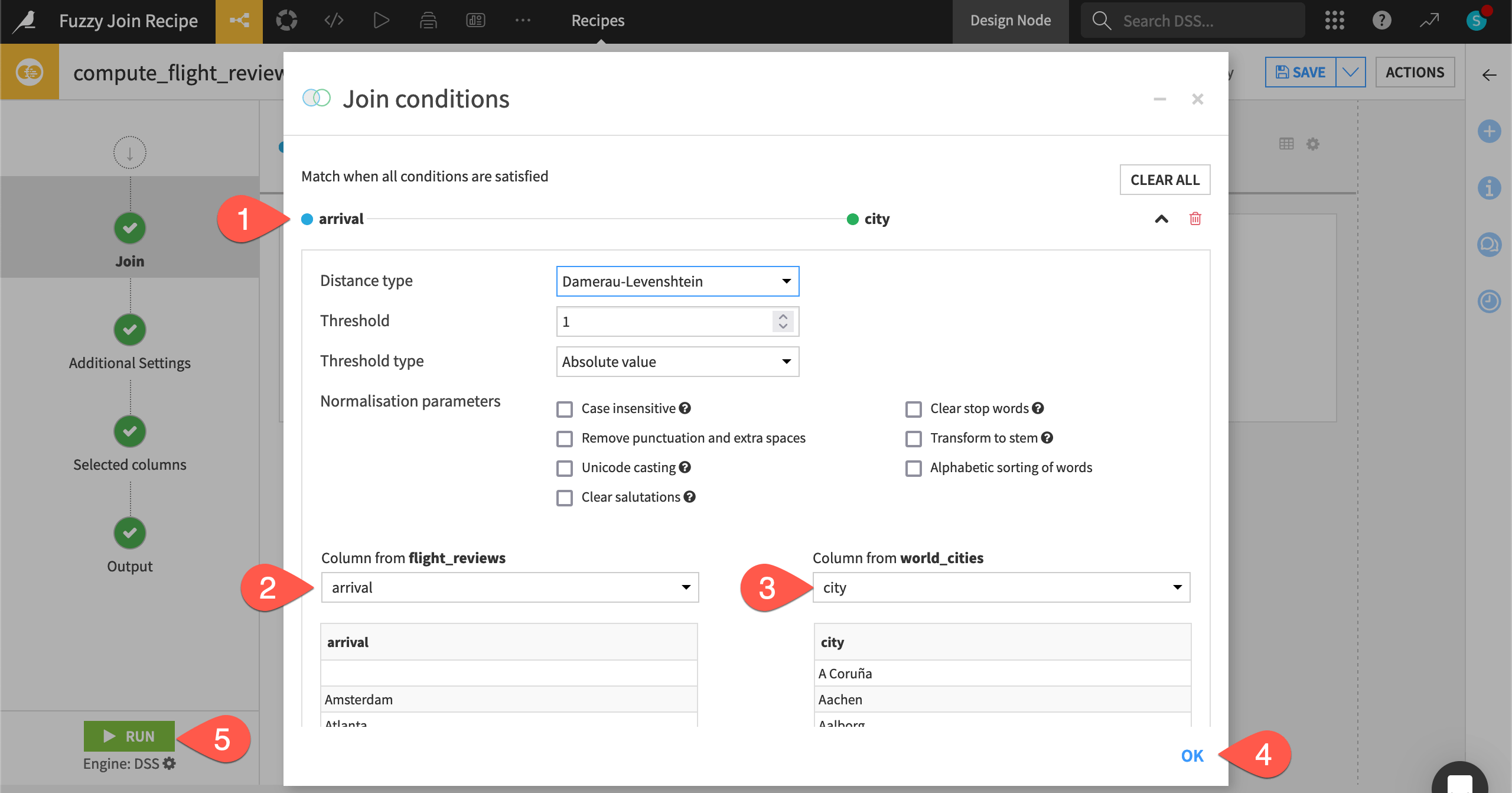
Select the join key columns#
As with a standard Join recipe, you need to select the join key column from each input dataset.
In the Join step, click on the default condition to open it, and once more to expand it.
Open the dropdown for flight_reviews, and select arrival as the join key column.
Open the dropdown for world_cities, and select city.
Click OK to close the condition without adjusting other defaults.
Click Run, and open the output dataset when the recipe finishes running.
Inspect the fuzzy output#
This first run of the Fuzzy join recipe used the default distance type: a Damerau-Levenshtein distance of 1.
Important
Damerau-Levenshtein distance measures the minimum number of operations required to change one word into the other. These would be operations like insertions, deletions, or substitutions of a single character, as well as transposition of two adjacent characters.
In this case, that means the recipe first calculates the distance between the values of the join key columns. Then, according to the maximum distance threshold, it maps and joins the columns based on similar values whose distance fits within the chosen threshold.
For example, the Damerau-Levenshtein distance between Lisbon and Lisboa is 1 because there is only one substitution of the letter n with the letter a required to transform one word into the other.
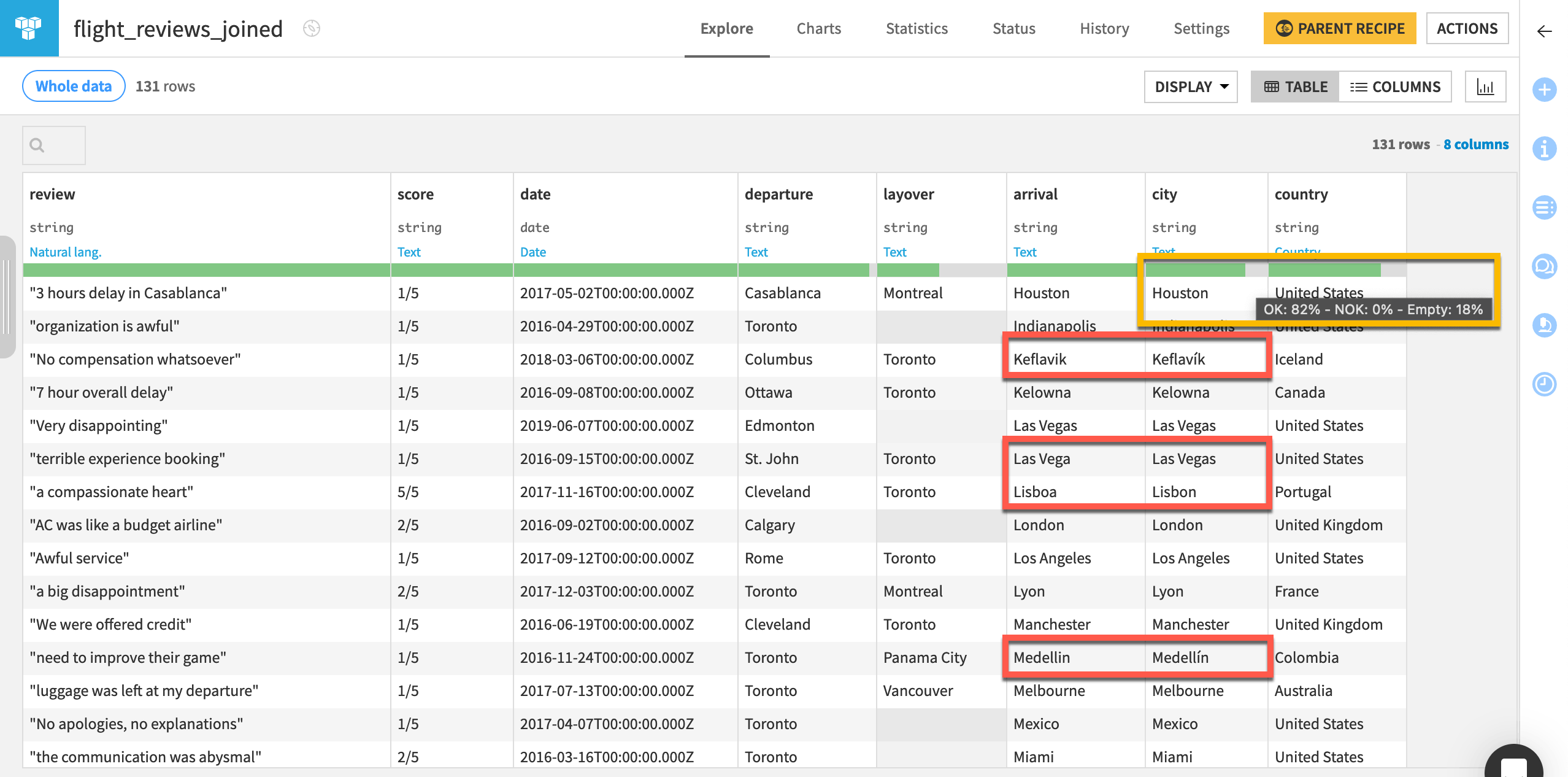
In the flight_reviews_joined dataset, compare the arrival and city columns.
In the data quality bar, recognize that only 18% of the city column in the Fuzzy join output is empty.
Note arrival values like
Las VegaandLisboafound city matches withLas VegasandLisbon.Even though text wasn’t normalized, arrival values like
Medellinstill matched city values likeMedellínbased on the Damerau-Levenshtein distance of 1.
See also
See the reference documentation for other available distances in the Fuzzy join recipe.
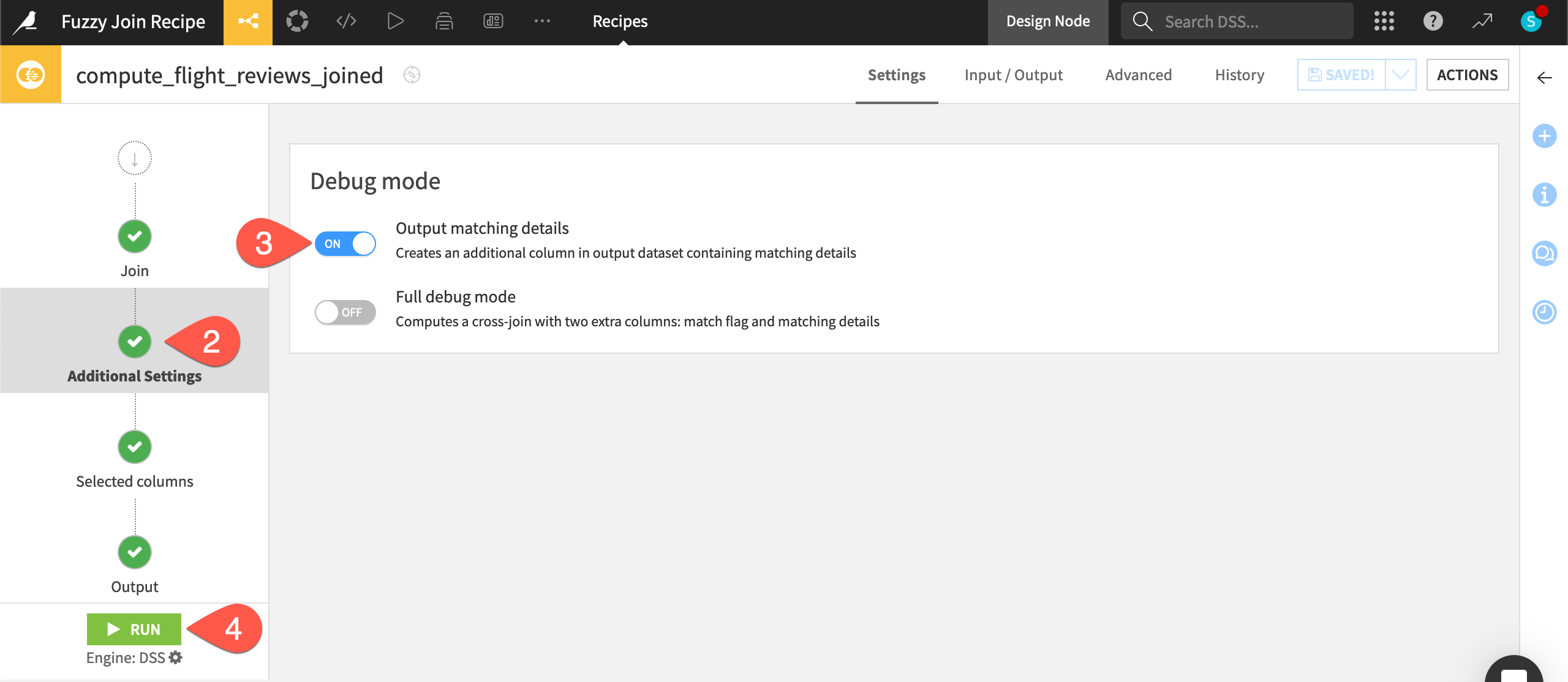
Debug the fuzzy output#
Looking at examples in the data may not always be enough to confirm how well the fuzzy join is working. For this reason, the Fuzzy join recipe also has some debugging options.
From the flight_reviews_joined dataset, click Parent Recipe.
Navigate to the Additional Settings step.
Turn On the Output matching details option.
Click Run, and open the output dataset when the recipe finishes running.
Prepare the fuzzy output#
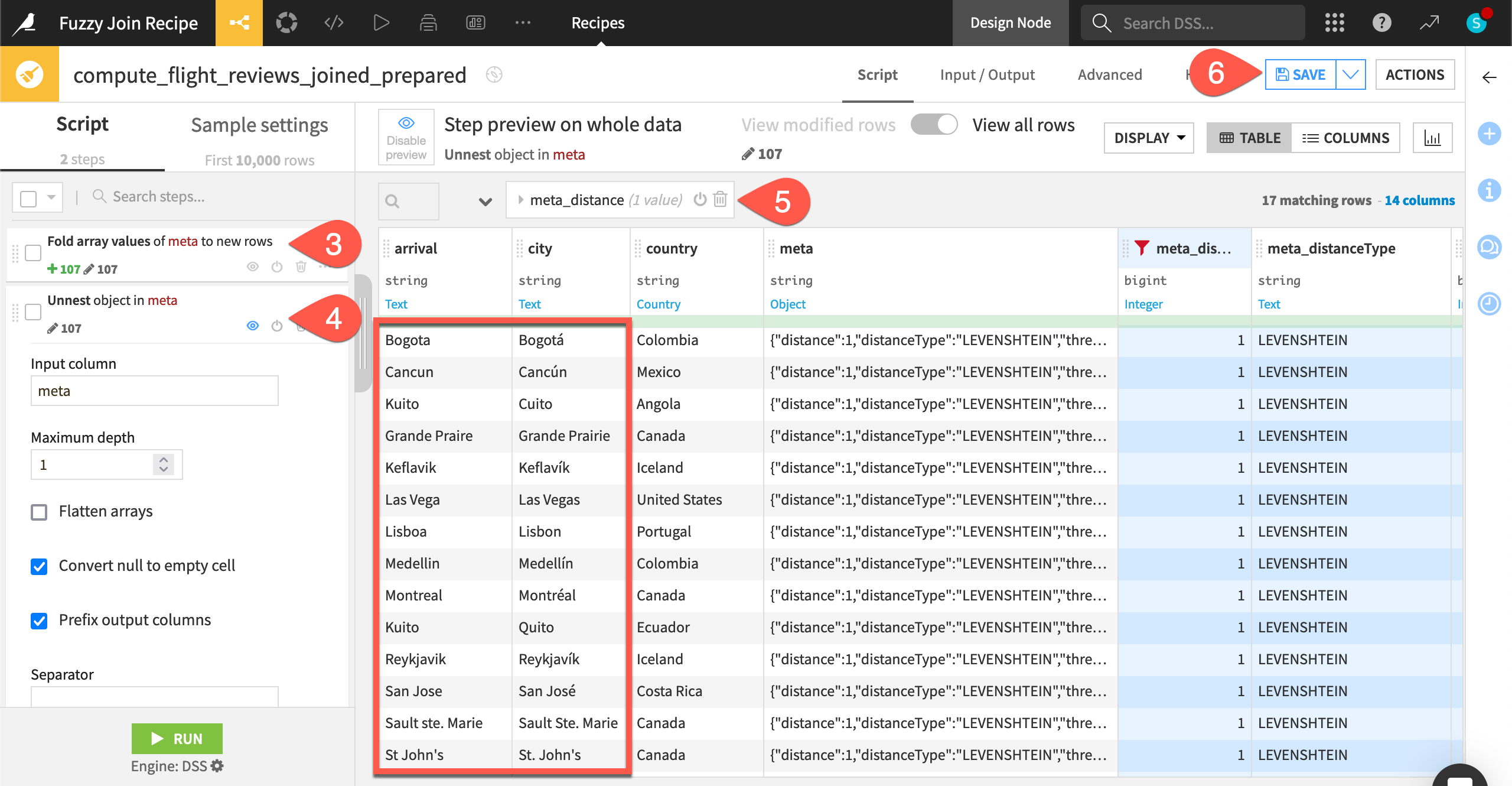
The Fuzzy join output now includes a meta column. You can parse it with a Prepare recipe to make better use of the information.
Find only the rows where the recipe performed a non-equality match — or, to be more specific, where the distance between the key values was 1.
From the flight_reviews_joined dataset, select Prepare from the Actions tab of the right panel.
Click Create Recipe.
From the meta column dropdown header, select Fold to one element per line.
Open the meta column dropdown header, and select Unnest object.
Open the meta_distance column dropdown header, and select Filter. Include rows only equal to 1.
Compare the edit distance between the arrival and city columns.
Click Save.
Increase the fuzziness of the join#
What would happen if you increased the distance threshold of the join condition?
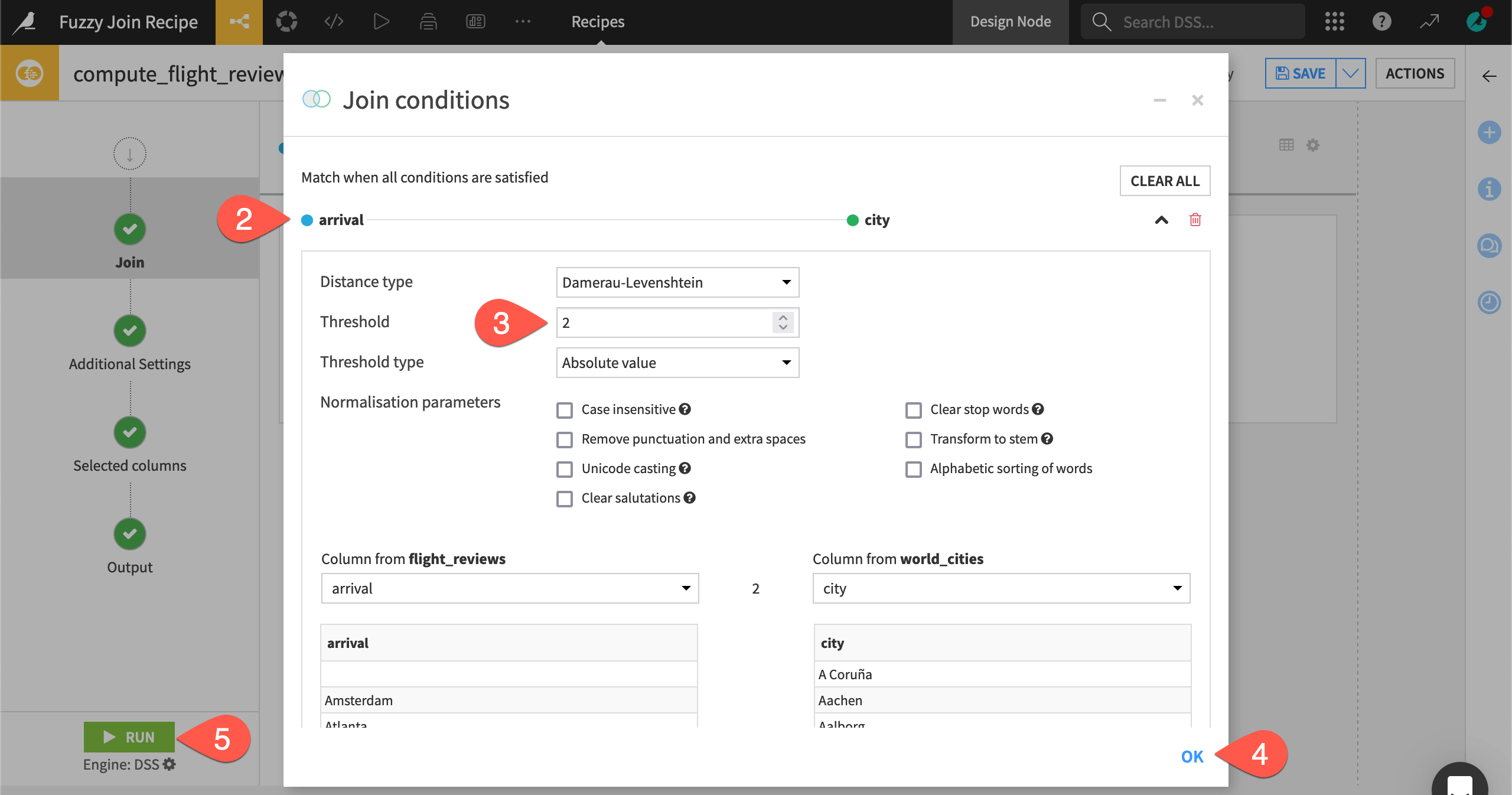
Return to the Join step of the Fuzzy join recipe.
Open and expand the join condition.
Keep the Damerau-Levenshtein distance type, but increase the threshold to
2.Click OK to close the condition.
Click Run, and Run again to build the outputs downstream.
Open flight_reviews_joined_prepared when the recipe finishes running.
Important
The recipe has now gone too far! The city column has almost no empty values, but the output includes many incorrect matches like Atlanta matching with Alanya. Fuzzy joining is rarely an exact science. This is why you often need the debugging options!
Tip
You should be mindful of the row count after a Fuzzy join. If the join key values are unique, the output of a left join has the same number of rows as the left input. This can’t be the expectation for a Fuzzy join.
Notice that the Fuzzy join output (flight_reviews_joined_prepared) has 670 rows compared to 130 rows for flight_reviews_standard_joined. This is because an arrival value like Atlanta matches with multiple city values (Alanya, Altata, Atlantic, etc.) leading to a new row for each match. You could use data quality rules to build in a check for this.
Next steps#
Congratulations on taking your first steps with the Fuzzy join recipe! This is one more option to join datasets in Dataiku without using code.
See also
For more information on this recipe, see Fuzzy join: joining two datasets in the reference documentation.
Tip
You can find this content (and more) by registering for the Dataiku Academy course, Visual Recipes. When ready, challenge yourself to earn a certification!