
Concept | Dataset characteristics#
Watch the video or read the summary below.

Let’s look at some dataset characteristics in Dataiku, including:
Column storage type
Column meaning
Dataset schema
To start, columns are an important element in Dataiku datasets. Columns usually represent the features of a dataset and categorize information. Dataiku generates additional information about a column that gives you better insight into its data values.
This information is the storage type and meaning of the column. What’s the difference between these two labels?
Storage type#
The storage type of a column is specified under column names in Dataiku. It indicates how the dataset backend should store the column data, and how many bytes will be allocated to store these values. Common storage types include:
String
Integer
Float
Boolean
Date

The storage type drives the way you can apply data transformations. For instance, when joining two datasets, their key columns must have the same storage type. Another example is when using the Dataiku formula language, not all operators work on date storage types. Keep this in mind when learning about Dataiku recipes.
Important
When you import a dataset from a connection (like an SQL table), the dataset already has defined storage types that you shouldn’t change.
Meaning#
Column meaning#
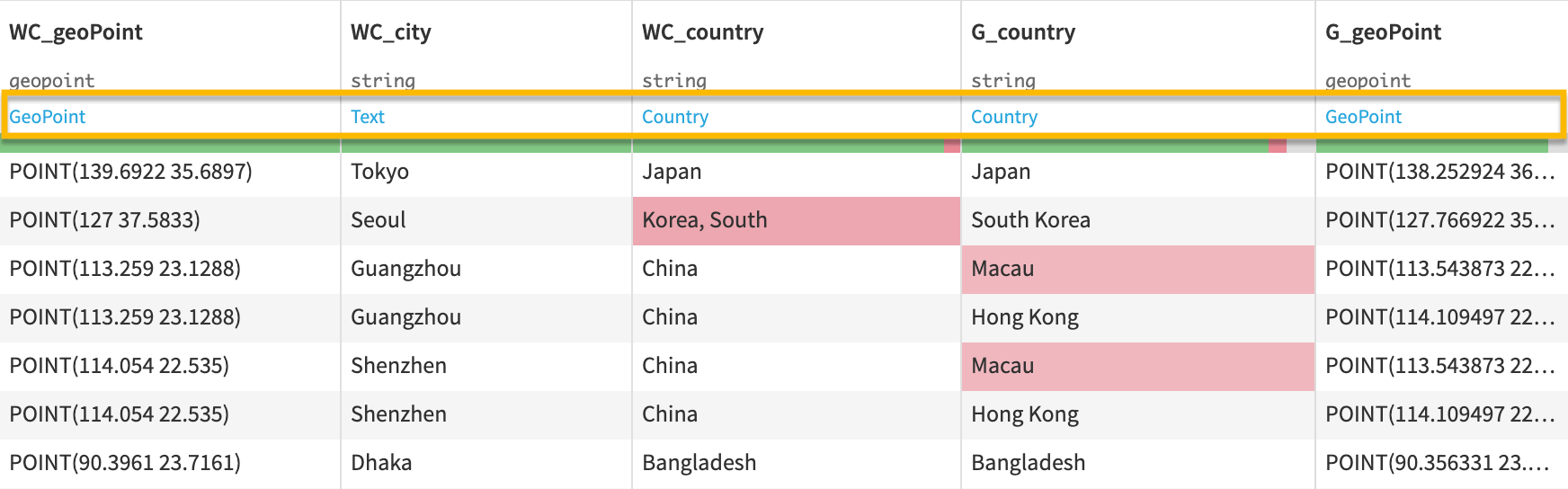
Dataiku indicates an inferred meaning in blue at the top of each column. The meaning of a column provides a rich semantic label for the data type, such as country, email address, text, array, temperature, and more. Dataiku automatically detects meanings from the values in the columns. You are welcome to change them if needed.
While you can’t use meanings in the same way that you use storage types, you can use meanings in powerful and creative ways. For example, you can use a column meaning in ways such as:
Autodetecting possible column transformations.
Measuring the data quality of a column. Dataiku can detect if a cell is valid or invalid for a given meaning.
Making specific values easier to find.
Note
When the Dataiku-detected meaning doesn’t reflect the values in the column, you might want to select a less restrictive meaning. For example, you can change the meaning of a column from integer to text if some values in the column contain text. You can even create your own meanings!
Impact on the context menu#
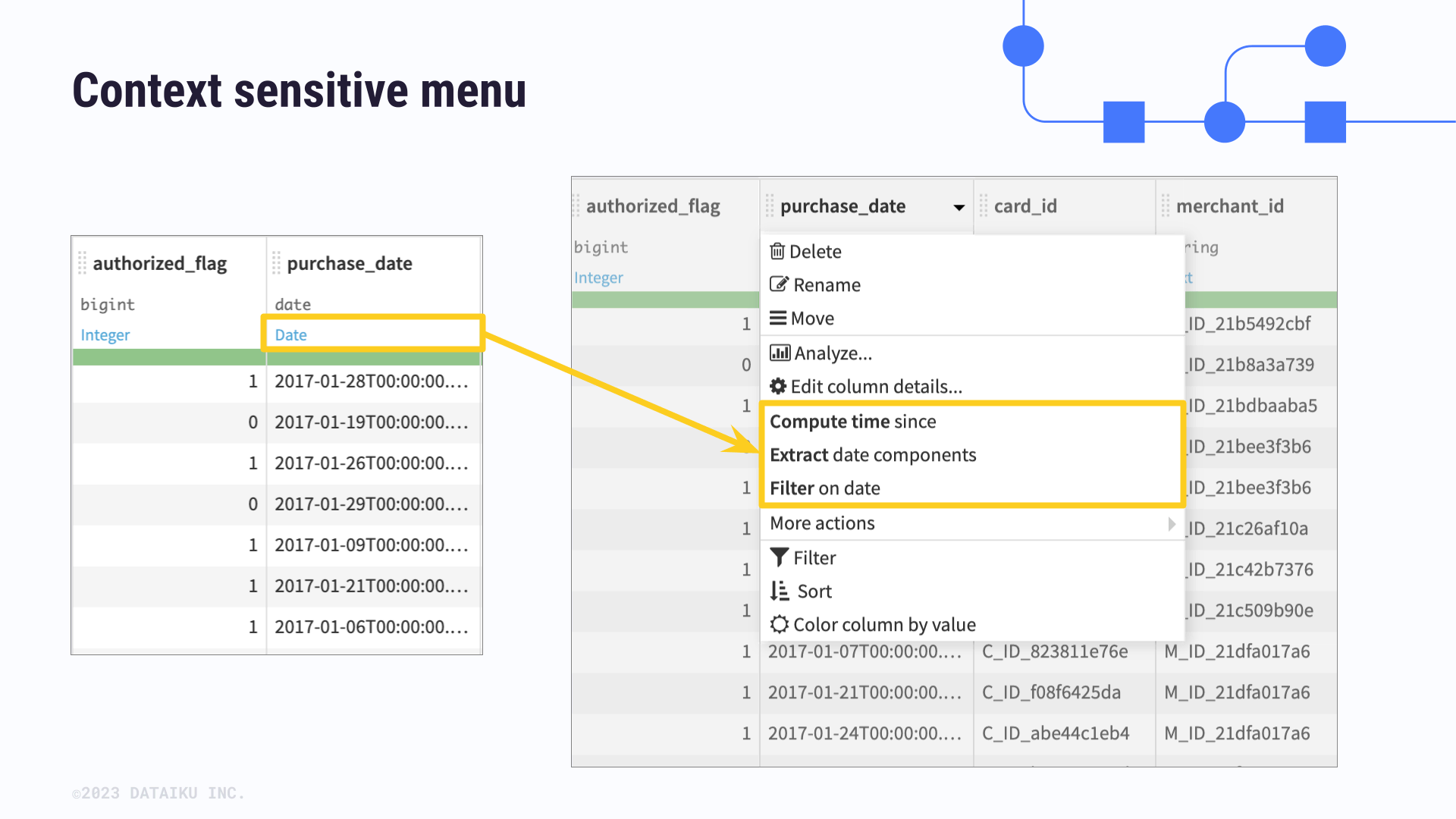
Column meanings are especially important for the context sensitive menu. When using the Prepare recipe, for instance, Dataiku will use the meaning to provide data transformations in this menu that you might want to employ.
For example, a column with the Date meaning will have its own relevant transformation options such as Compute time since or Filter on date, to name a few.
Dataset schema#
A schema in Dataiku is a list of a dataset’s column names and respective storage type. You can view the schema of a dataset in the Schema tab of the right panel.
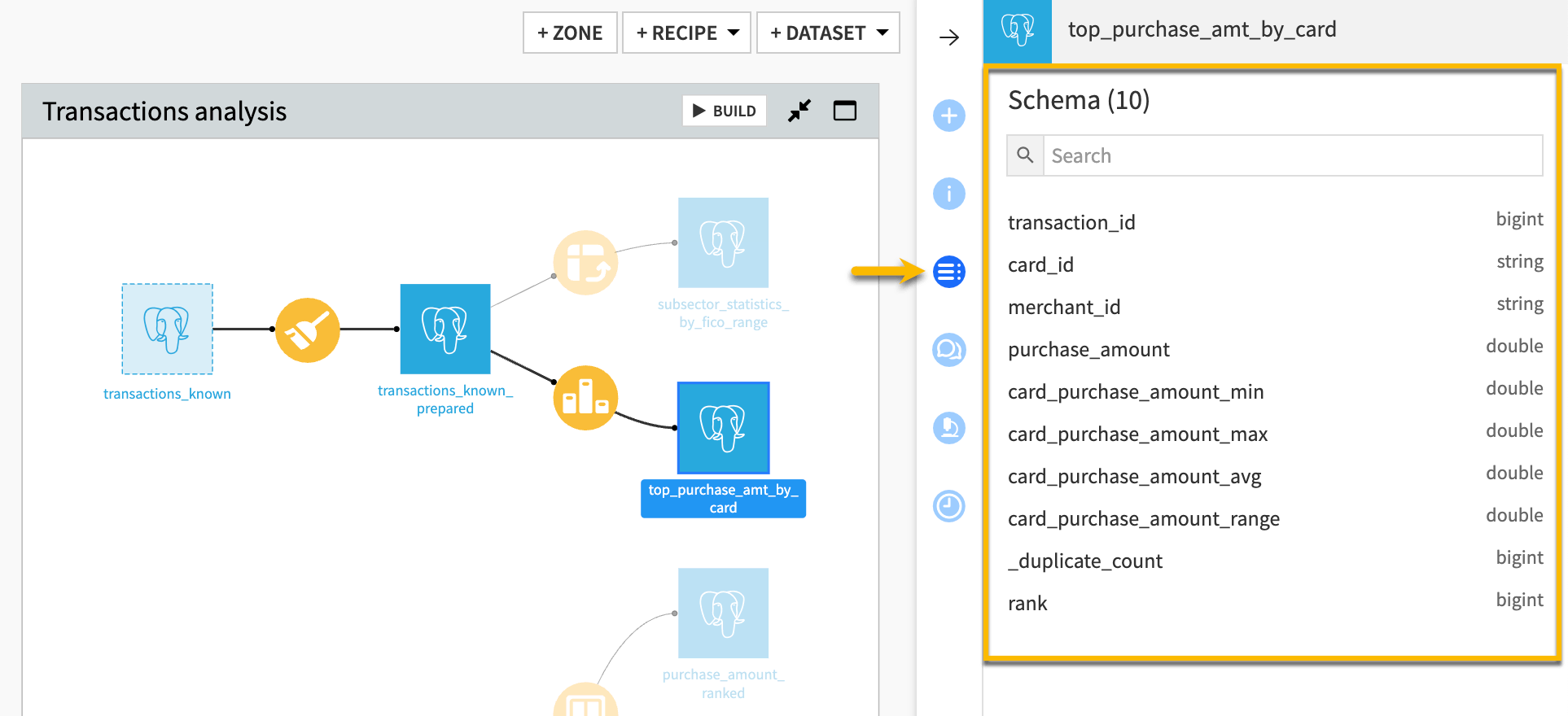
When you upload a dataset or connect to a dataset, Dataiku detects the columns with their names and storage types. You can change these values during this process or later on in your workflow. For example, you can click on a dataset in the Flow, navigate to Settings > Schema, and edit the schema here.
Note
Any schema changes in your Flow won’t apply to downstream datasets until you run recipes downstream. You can find more information on schema changes in the Advanced Designer learning path.
Next steps#
If you’re just starting out with Dataiku, keep learning and try out our Core Designer learning path!