
Concept | Join recipe#
Watch the video or read the summary below.

The primary purpose of the Join recipe is to enrich one dataset with columns from another.
Dataiku matches values using a key column that is common to both datasets. You can also configure several steps to customize the join.
Join step#
The Join step is where you set up the main instructions for the join.
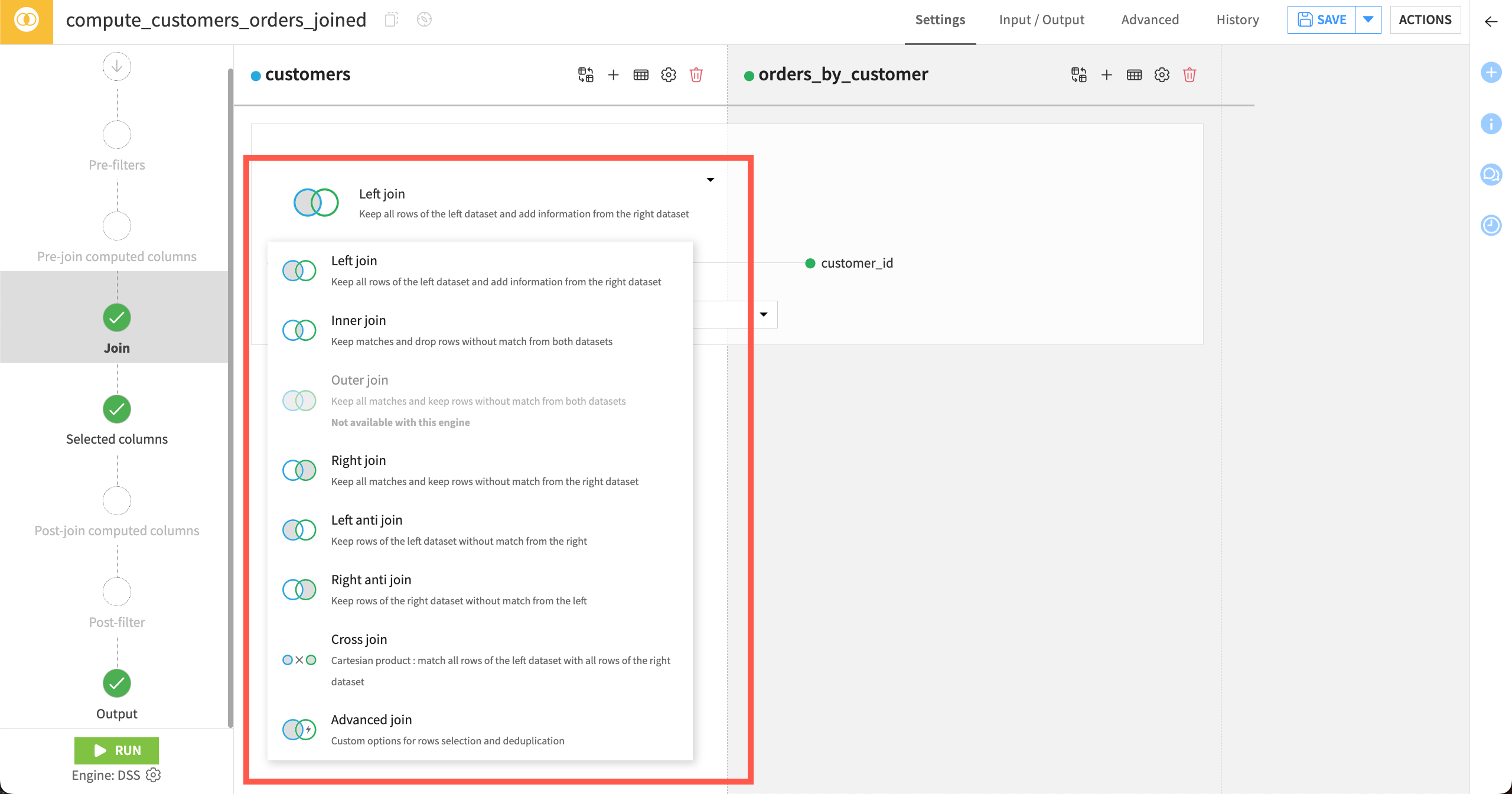
Choose join type#
The output of the matching depends on the join type.
You can choose from many types of joins, such as Left join (default), Right join, and Outer join.
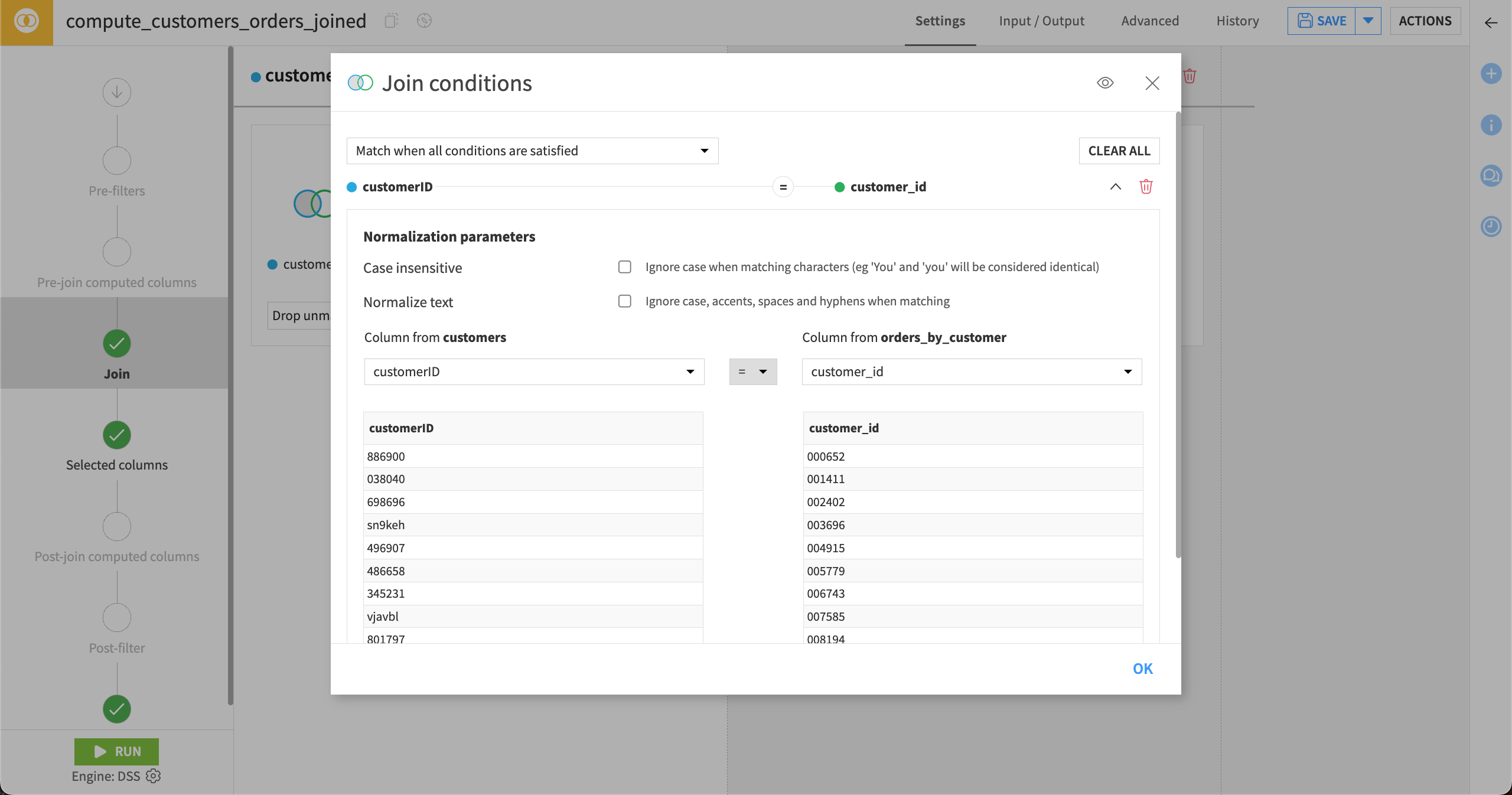
Select key column and conditions#
Dataiku can automatically detect the key column. You can also select your own columns to match on.
You can also set conditions for the values matching, such as equals to, greater than, lesser than, or not equal to.
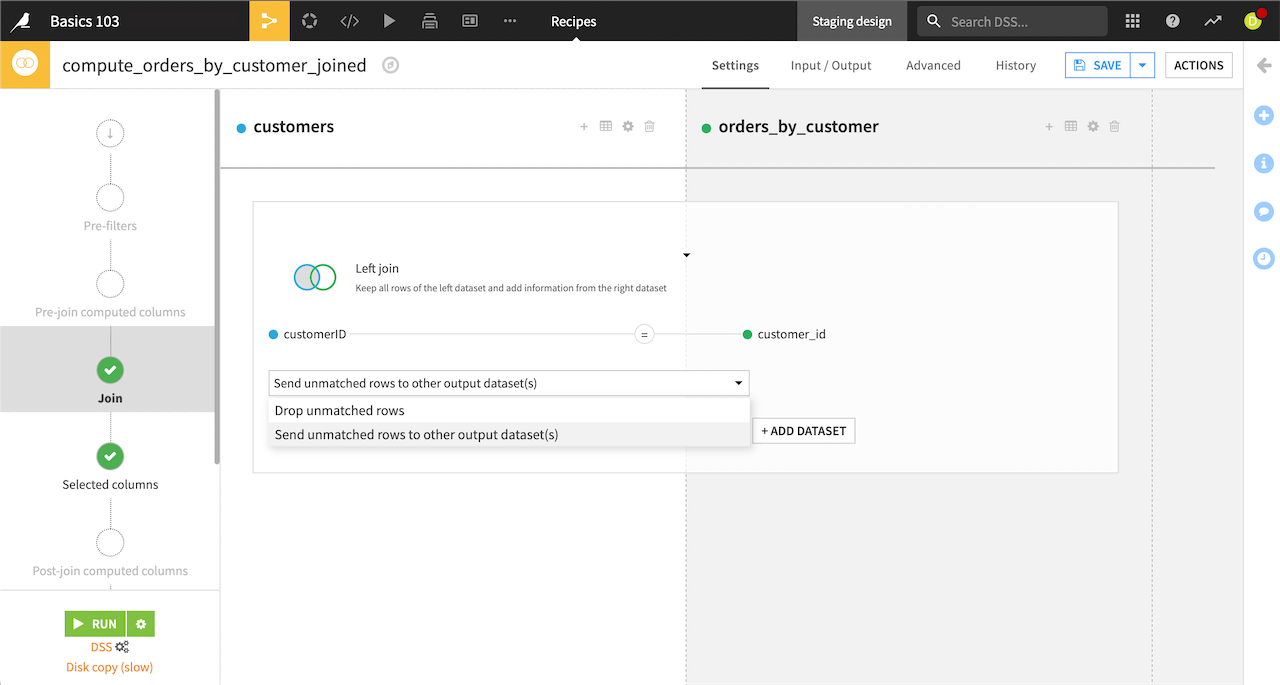
Save unmatched rows#
When performing a left, right, or inner join, you can add a dataset to capture any unmatched rows.
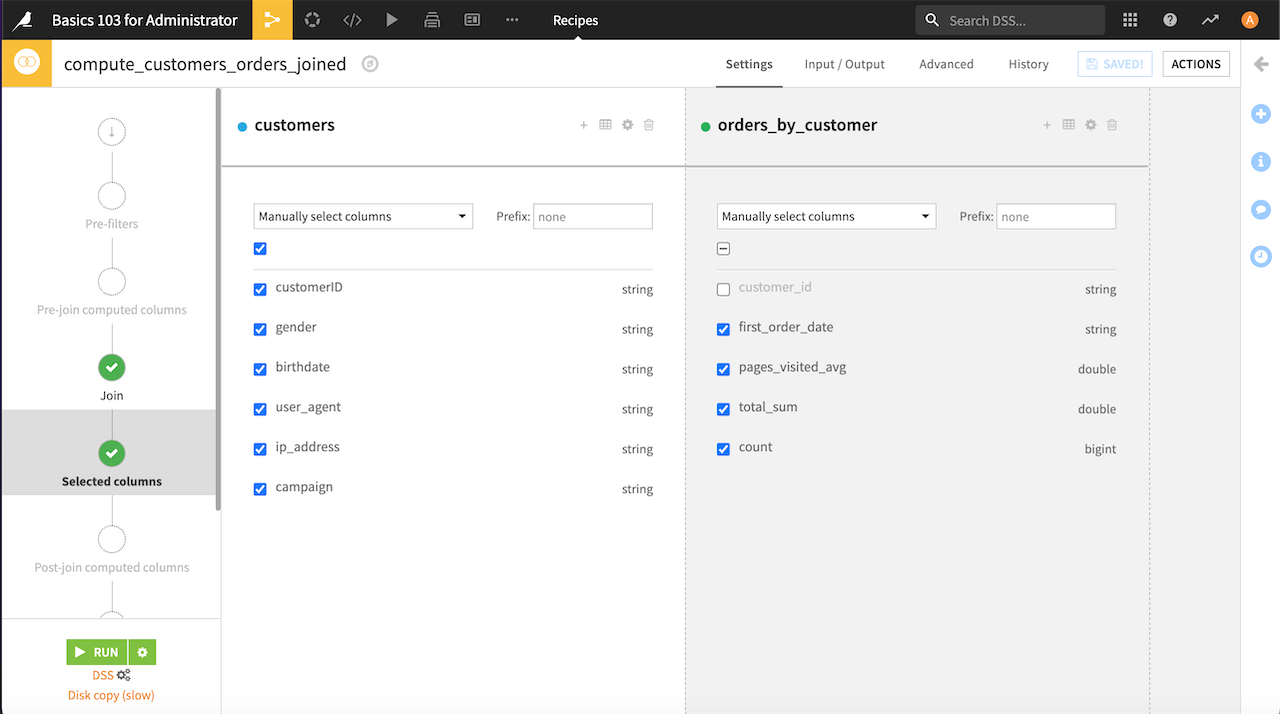
Selected columns step#
In the Selected columns step, you can tell Dataiku which columns you want to see in the output dataset.
Other steps#
There are a few other options, including filters and computed columns.
Set filters#
The Pre-filters step allows you to keep or drop rows based on your criteria. This can be useful before joining unwanted rows in large datasets.
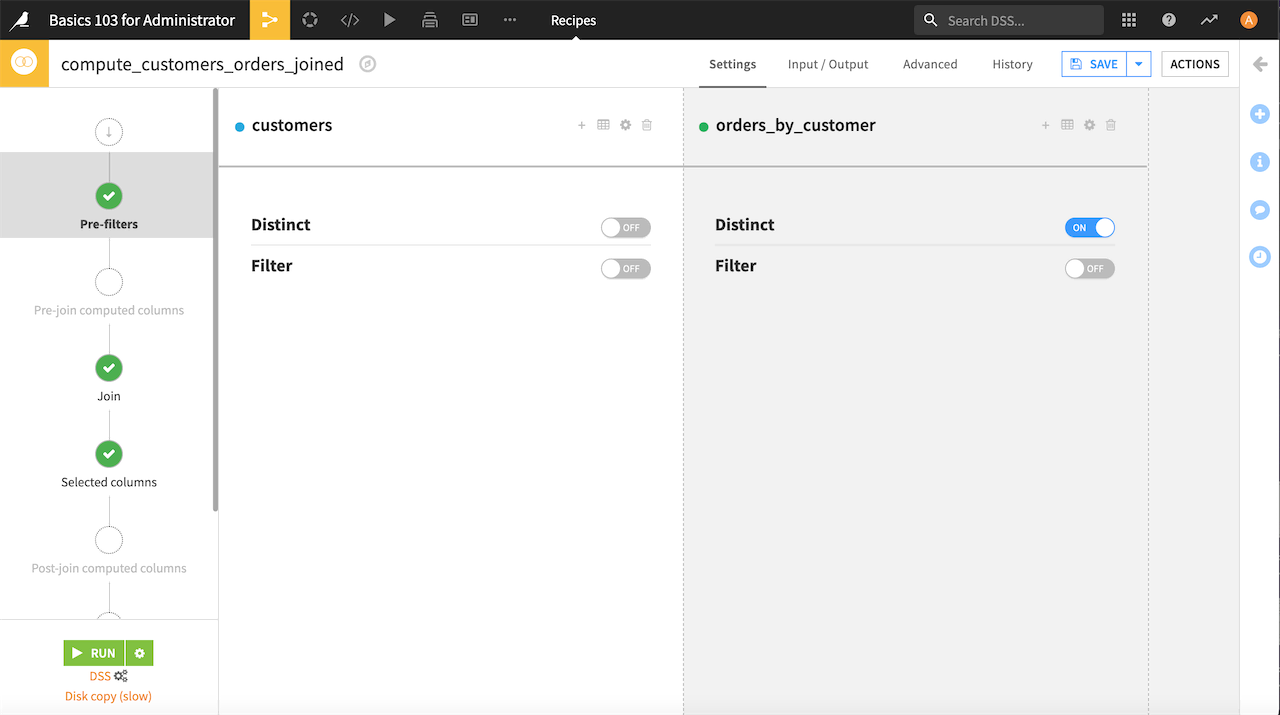
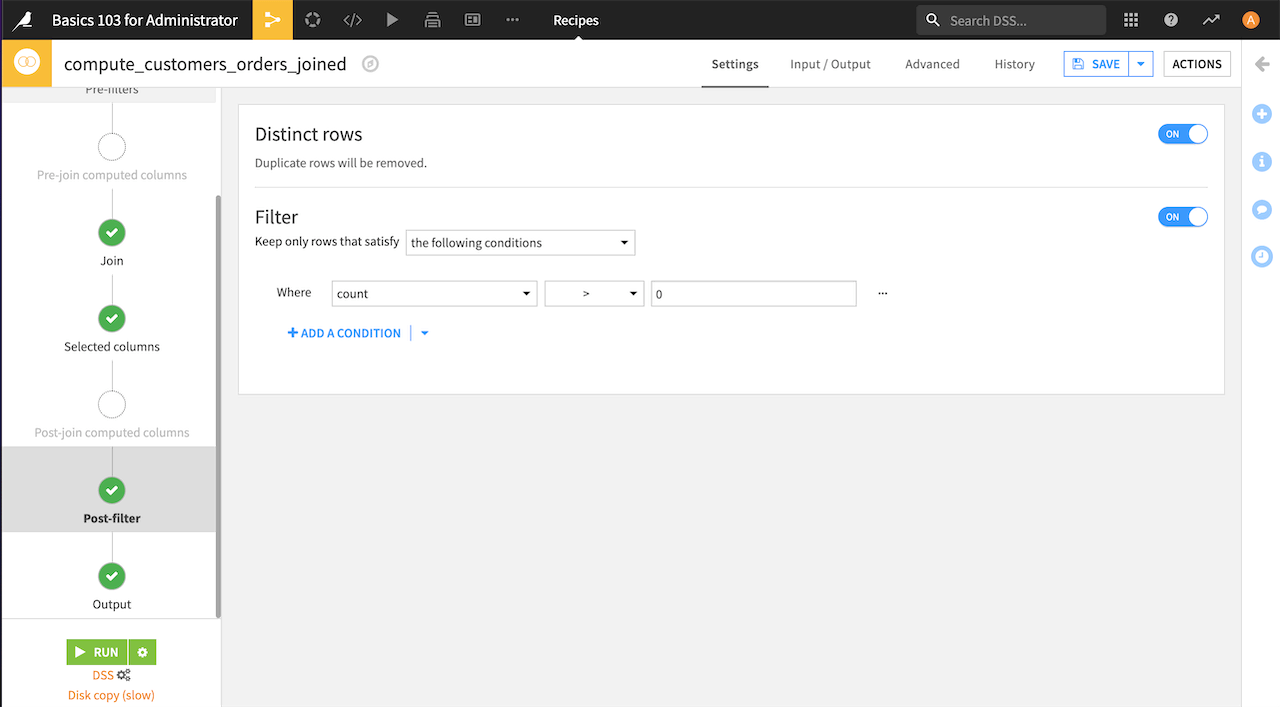
You can use the Post-filter step to filter the results of the join operation before writing the output dataset. For example, you can tell Dataiku if duplicate rows are allowed and if you want to return only rows that match a condition.
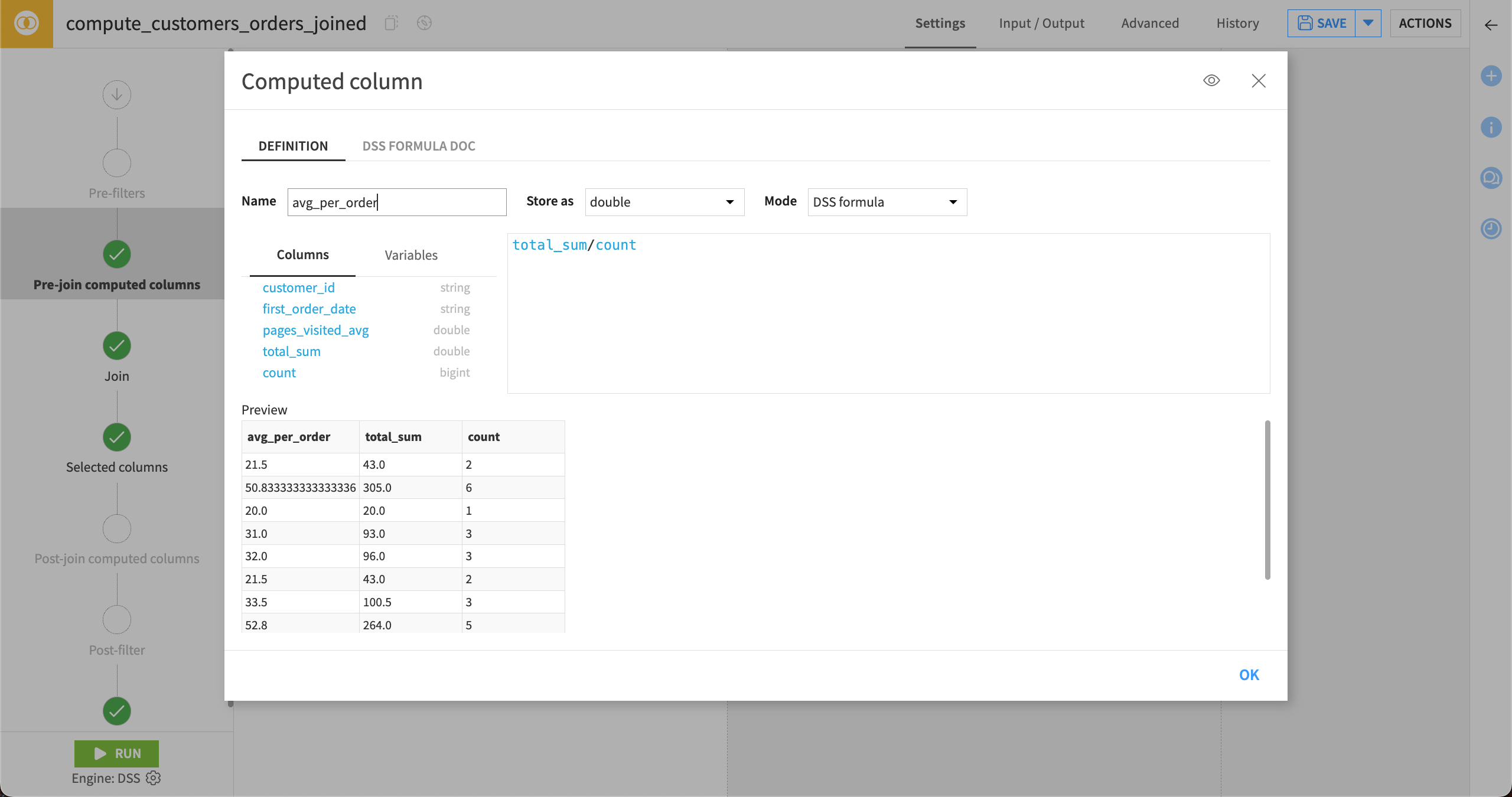
Compute columns#
You can create new columns using SQL or Dataiku formulas either before or after the Join step occurs.
Output step#
Finally, you can use the Output step to review the execution specs and output columns.
Next steps#
There are a lot of reasons to use joins when building a Flow.
Continue learning about this recipe by working through the Tutorial | Join recipe article.
Tip
You can find this content (and more) by registering for the Dataiku Academy course, Visual Recipes. When ready, challenge yourself to earn a certification!