
Concept | Data pipeline optimization#
Programmers are familiar with code refactoring. The goals of refactoring include improving readability, reducing complexity, and increasing efficiency while maintaining the same functionality as the original code.
When working in Dataiku, apply the same engineering mindset to your data pipelines. Before deploying a project to production, take the opportunity to optimize your workflows.
This article establishes a foundational framework for optimizing Dataiku projects, focusing on project hygiene, Flow readability, project maintainability, and computational efficiency.
Project cleanup#
An efficient project is one that contains only the assets needed for production. During the design and prototyping phase, projects naturally accumulate temporary datasets, draft notebooks, visualizations, and other assets.
If these elements remain in production, they can reduce Flow readability, complicate maintenance, and introduce uncertainty about which components are actively used.
Typical examples of unnecessary production artifacts include:
Redundant objects, such as abandoned Flow branches, outdated notebooks, unused recipes, or temporary test datasets.
Obsolete automation components, including experimental scenarios, temporary triggers, or unused metrics definitions that no longer contribute to operational processes.
Maintaining a clear separation between exploratory artifacts and production assets improves project maintainability and helps keep operational pipelines understandable over time.
Tip
If you want to retain artifacts not required for production, Dataiku allows you to copy Flow items into other projects. You can then delete them from the original.
Readability#
Data pipelines are living assets frequently handed off to production engineers or inherited by new team members. High structural readability ensures rapid troubleshooting when production issues arise.
For complex, wide, or deep Flows, implement Flow zones. They allow you to logically group related datasets and recipes into distinct visual clusters. This abstracts the granular complexity of the pipeline into a high-level conceptual map.
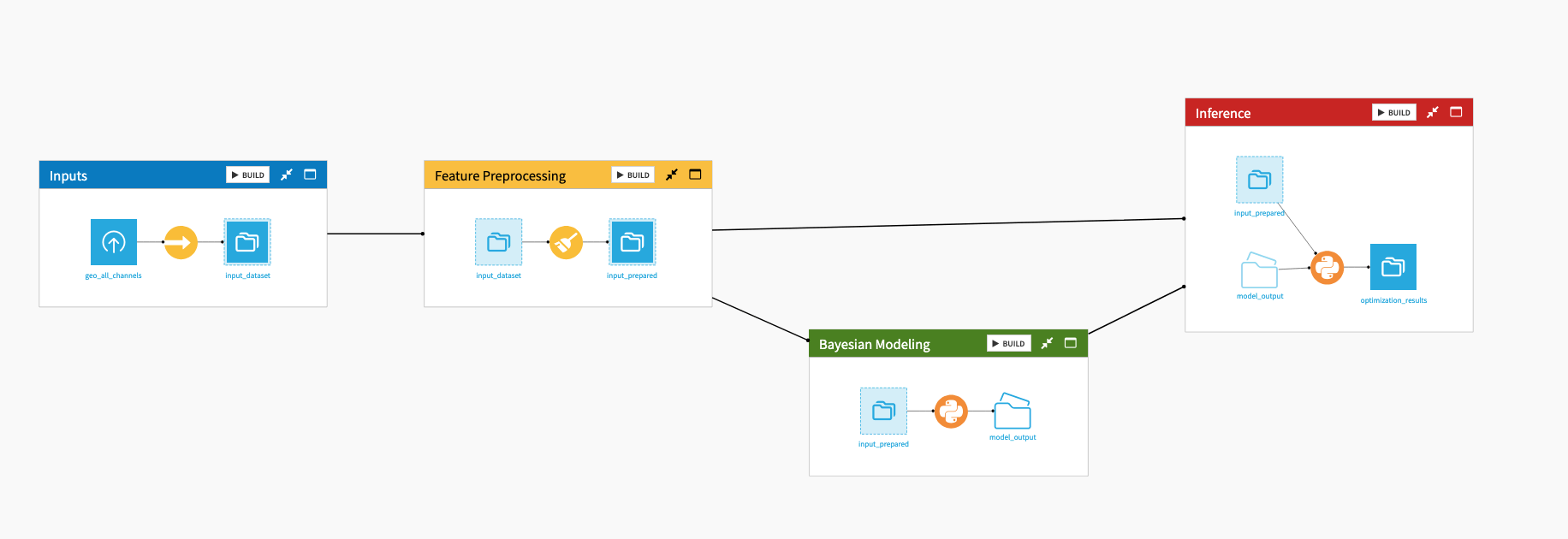
Tip
Use a standardized naming and color-coding convention for your Flow zones across all company projects.
To further optimize workspace visibility, you can also learn how to:
Tag the Flow items to categorize your assets.
Filter the Flow to show or hide specific parts of your pipeline.
Variables#
Hard-coded parameters, such as absolute dates, specific region names, file paths, or model thresholds, are a common source of maintenance issues in production pipelines. If a hard-coded value must change, you risk missing a recipe, forcing manual edits and introducing human error.
To solve this, Dataiku allows you to abstract parameters using variables.
Computational efficiency#
A key optimization consideration is the project’s computational efficiency. Is the Flow running in the most optimized way possible?
Recall that Dataiku is an orchestrator of workflows. With this in mind, verify that the project satisfies two general requirements:
It leverages any external computing power at its disposal.
It minimizes resource consumption on the Dataiku host.
Compute optimization#
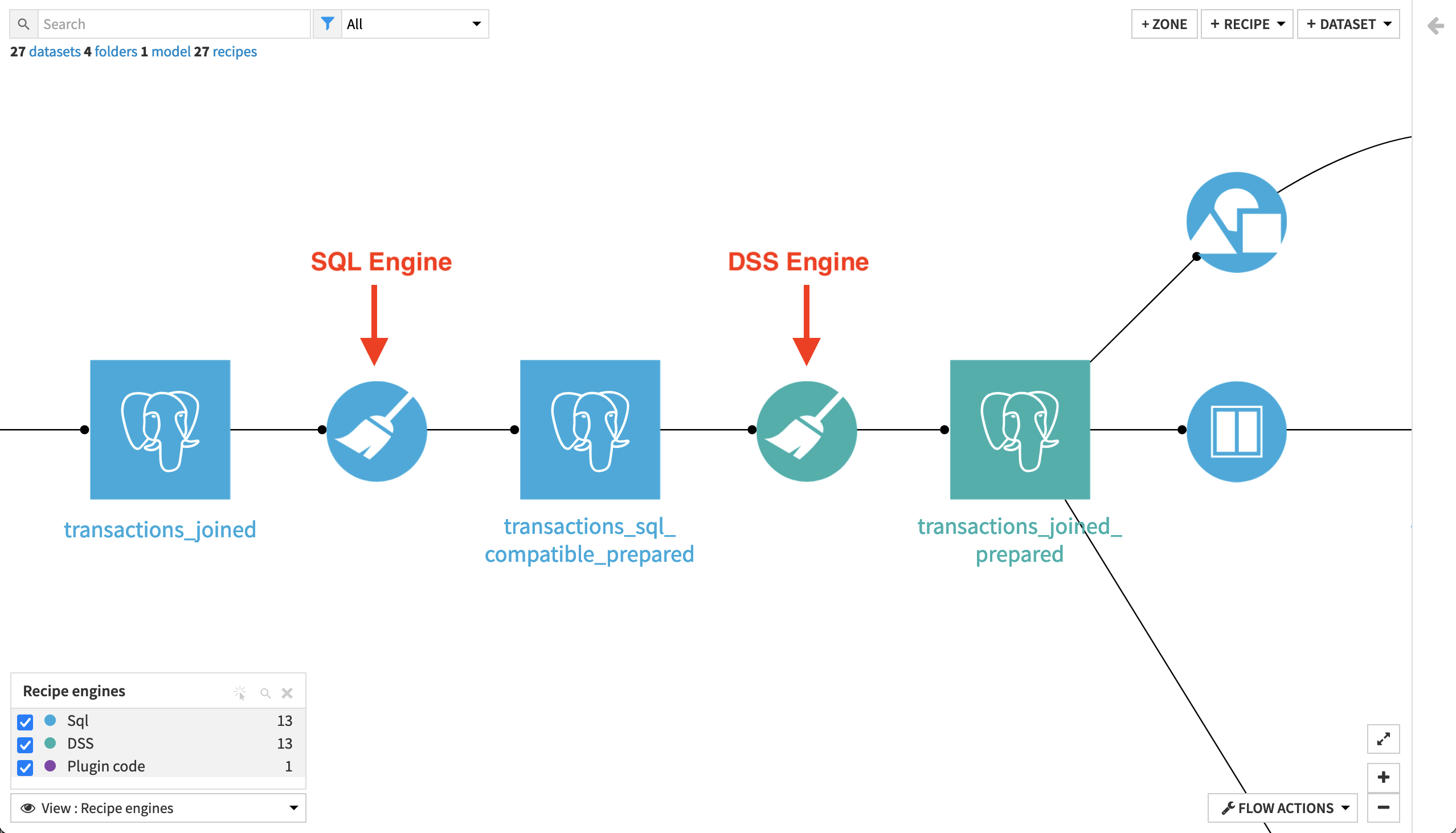
Understanding where computation occurs is central to optimizing a DSS project. The recipe engine Flow view provides visibility into which execution engines are used throughout the pipeline. As shown below, it color-codes your recipes by execution engine, allowing you to spot when the DSS engine is handling the workload rather than an external database.
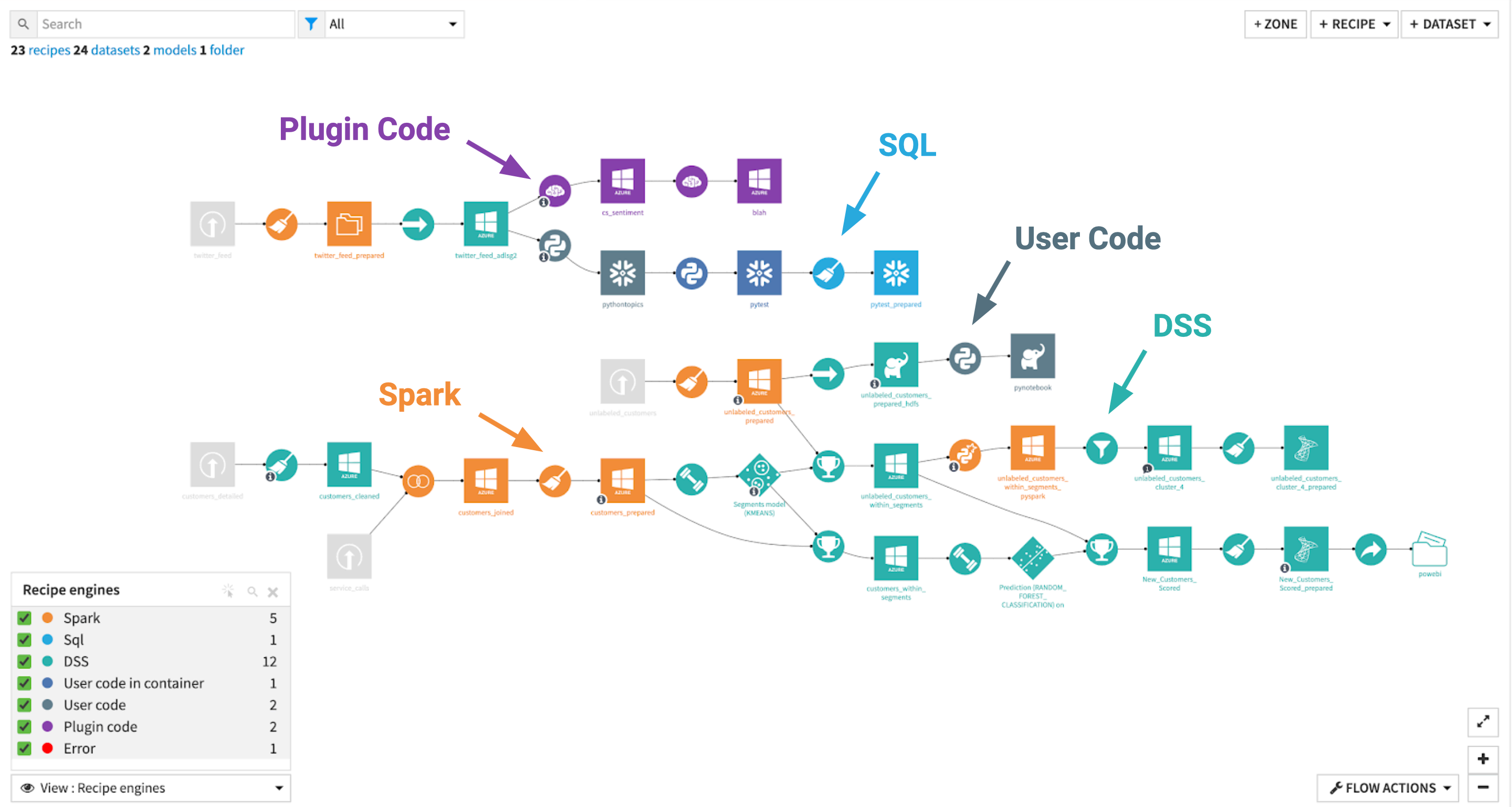
Dataiku automatically attempts to select the most suitable engine based on the storage location of the input and output datasets. However, you should review these selections to ensure maximum efficiency:
SQL databases: If your datasets reside within an SQL database, ensure the visual recipes are configured to run in-database. This forces the database to do the heavy lifting via native SQL generation, avoiding costly data transfers.
Cloud object storage and clusters: For vast datasets stored in cloud systems, leverage distributed computing setups like Spark.
Code and machine learning: For heavy code recipes or visual machine learning training, ensure that containerized execution is activated to offload memory consumption from the Dataiku base server.
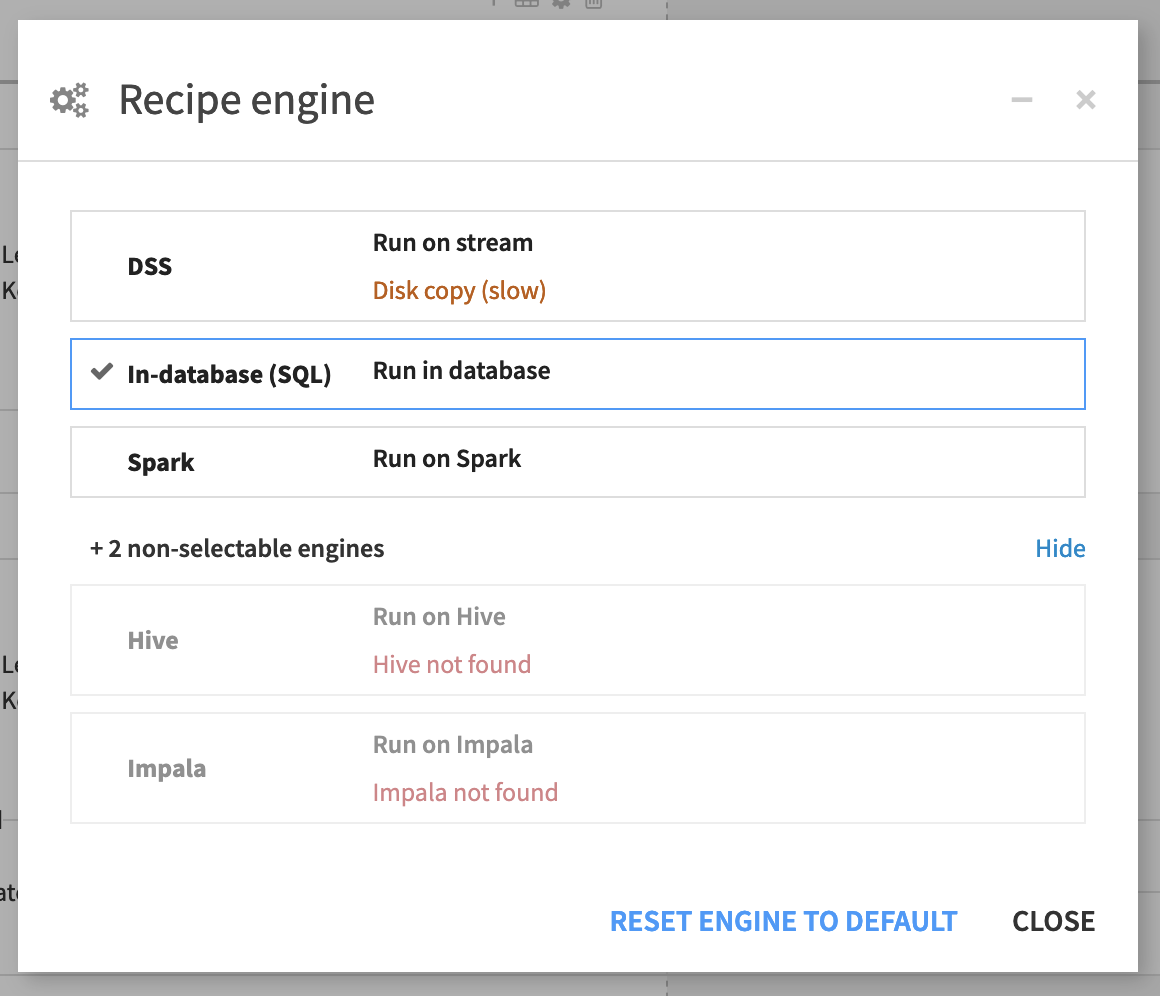
Tip
Don’t assume an engine selection is permanent. If you change a dataset’s storage location, open the downstream recipes and verify that Dataiku has updated the engine selection to match the new infrastructure.
Is Spark always required?#
While Spark is powerful for massive data scales, it carries a non-negligible setup overhead. Every time a Spark job is triggered, Dataiku must negotiate with the cluster, spin up executors, and allocate memory.
For smaller datasets that fit into the memory of a single machine, this initialization overhead can take longer than the actual data processing. If your dataset size is modest and the transformation is straightforward, sticking with the native DSS engine or standard SQL processing will often yield faster execution times than Spark.
Tip
Use the available Flow views, such as the file size Flow view, to estimate whether Spark is appropriate for your workload. However, the best way to validate your choice is to test your pipeline first with sample data, then with production-scale data.
See also
Review the reference documentation for more information on Dataiku and Spark.
Spark and SQL pipelines#
One corollary to the principles above is that you should try to avoid the reading and writing of intermediate datasets.
In certain situations, you can minimize the repeated cycle of reading and writing intermediate datasets within a Flow by setting up either Spark or SQL pipelines.
For example, when several consecutive recipes in a Flow use the Spark engine (or alternatively the SQL engine), Dataiku can automatically merge these recipes. Then, you can run them as a single Spark (or SQL) job. These kinds of pipelines can strongly boost performance by avoiding needless reads and writes of intermediate datasets.
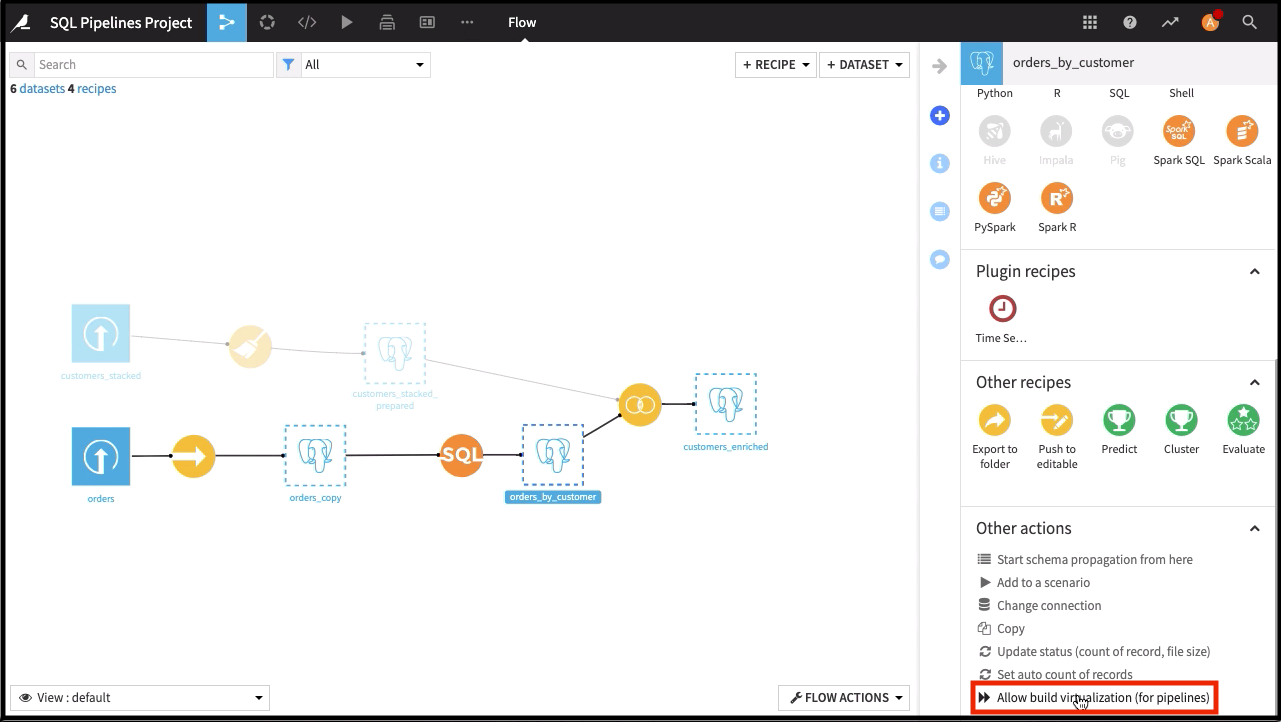
See also
See How-to | Enable SQL pipelines in the Flow for an introduction.
Back-to-back Prepare recipes#
As a general rule, you should avoid having back-to-back Prepare recipes unless explicitly justified. Combining multiple step sequences into a single Prepare recipe is cleaner and limits unnecessary read and write operations.
However, an exception occurs when managing SQL compilation. If your first Prepare recipe contains exclusively SQL-compatible processors, it can run entirely in-database. If the subsequent steps require complex Python functions or non-SQL processors, putting them in a separate, second Prepare recipe allows you to maximize the database power for the first half of the operation before falling back to the DSS engine for the remainder.
Tip
Check the engine indicator light next to individual steps inside a Prepare recipe. Dataiku will explicitly warn you if a specific step breaks SQL compatibility and forces the execution off the database.
Partitioning#
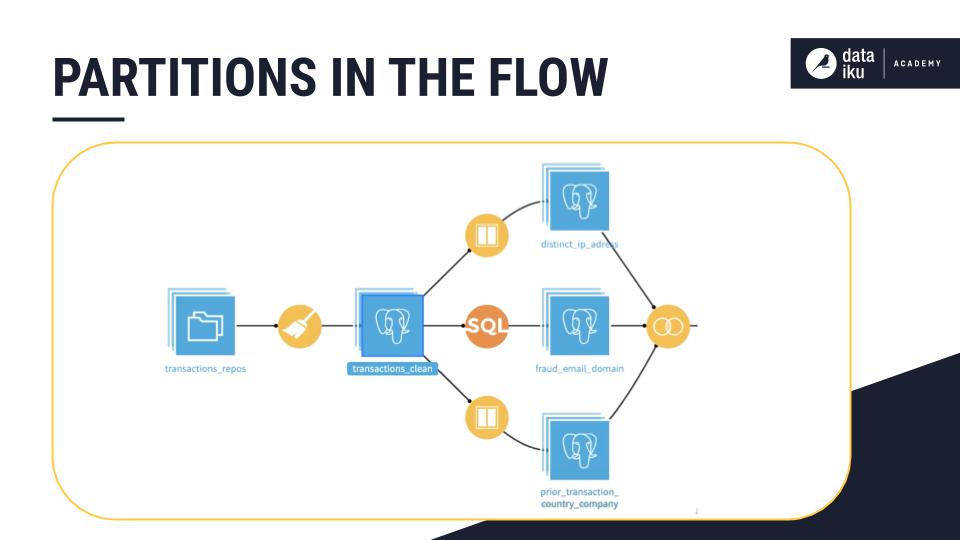
Finally, for specific use cases, partitioning can be a valuable optimization tool. For example, consider the common scenario where you need reports and dashboards updated on a periodic basis, such as daily. Without partitioning, the datasets in the Flow would continue to grow larger, consuming greater computational resources.
Instead of redundantly recomputing this historical data, partition the Flow so that only the latest segment of interest is rebuilt, while preserving historical partitions. If you do have a clear key on which to partition your Flow, partitioning is definitely an option worth considering before moving to production.
See also
To learn more, see the Partitioning course in the Advanced Designer learning path.
Runtime analysis#
Offloading computation using the strategies described in this article has the potential to add complexity. With this in mind, you’ll have to weigh the pros and cons with respect to the infrastructure, the type and the volume of data you’ll be using in production.
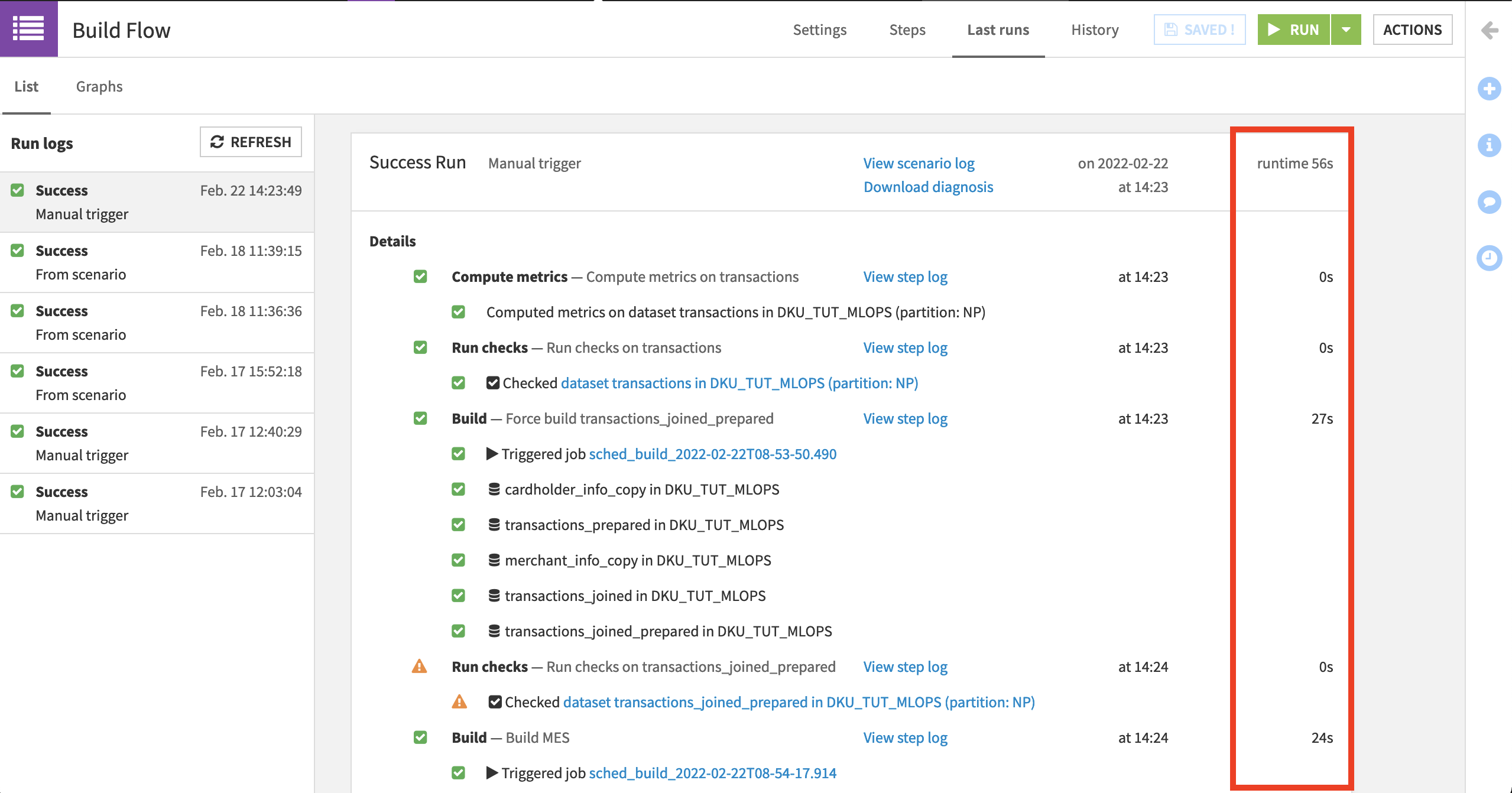
Testing the runtime of your Flow with scenarios can provide the basic information needed to think through these tradeoffs as you identify potential bottlenecks. You can find a quick visual comparison in the Last Runs tab of a scenario, which reports the runtime of each step. Many Flow views, such as last build duration, count of records, or file size, can also help identify bottlenecks.
Next steps#
Alongside optimization concerns, you should also devote sufficient attention to documenting a project before putting it into production. Learn more about how to do so in an article on workflow documentation.