
Tutorial | Window recipe#
The Window recipe uses advanced grouping to apply aggregate calculations to each row of a dataset. Let’s practice using different windows to show how they affect these calculations.
Get started#
Objectives#
In this tutorial, you will:
Learn what kinds of analytical questions require a window function.
Learn how to define a window frame in many different ways.
Learn how to compute grouped aggregations (such as rolling sums and ranks) over window frames.
Prerequisites#
To complete this tutorial, you’ll need the following:
Dataiku 14.0 or later.
Create the project#
From the Dataiku Design homepage, click + New Project.
Select Learning projects.
Search for and select Window Recipe.
If needed, change the folder into which the project will be installed, and click Create.
From the project homepage, click Go to Flow (or type
g+f).
Note
You can also download the starter project from this website and import it as a ZIP file.
You’ll next want to build the Flow.
Click Flow Actions at the bottom right of the Flow.
Click Build all.
Keep the default settings and click Build.
Use case summary#
Let’s say we’re a financial company that uses some credit card data to detect fraudulent transactions.
The project comes with three datasets, described in the table below.
Dataset |
Description |
|---|---|
tx |
Each row is a unique credit card transaction with information such as the card that was used and the merchant where the transaction was made. It also indicates whether the transaction has either been:
|
merchants |
Each row is a unique merchant with information such as the merchant’s location and category. |
cards |
Each row is a unique credit card ID with information such as the card’s activation month or the cardholder’s FICO score (a common measure of creditworthiness in the US). |
Create the Window recipe#
The Group recipe can compute the total sum of transactions for every distinct card. However, it can’t compute the running total for every card at any point in time.
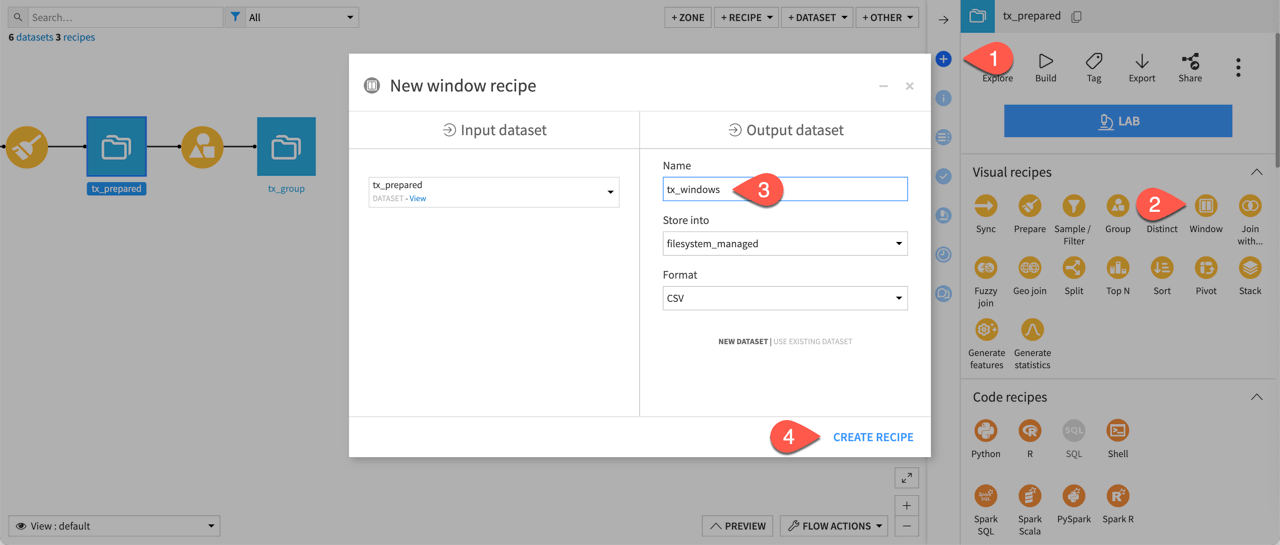
You can use a Window recipe for this kind of calculation. First, create a Window recipe from the tx_prepared dataset.
From the Flow, select the tx_prepared dataset.
In the Actions tab of the right panel, select the Window recipe from the visual recipes section.
Name the output dataset
tx_windows.Click Create Recipe.
Design your first window frame#
To calculate a running total per card, start by focusing on the first two aspects of the window frame: the partitioning column(s) and the order column(s).
It’s important that your window frame has deterministic ordering. In this case, the purchase_date column doesn’t guarantee a uniquely defined position because customers can make multiple purchases on the same day. Without deterministic ordering, it’s possible your window frame won’t include the rows you expect.
A column like purchase_timestamp would be deterministic. However, since that data isn’t available, you can combine purchase_date and the transaction id to guarantee a deterministic order for the window frame.
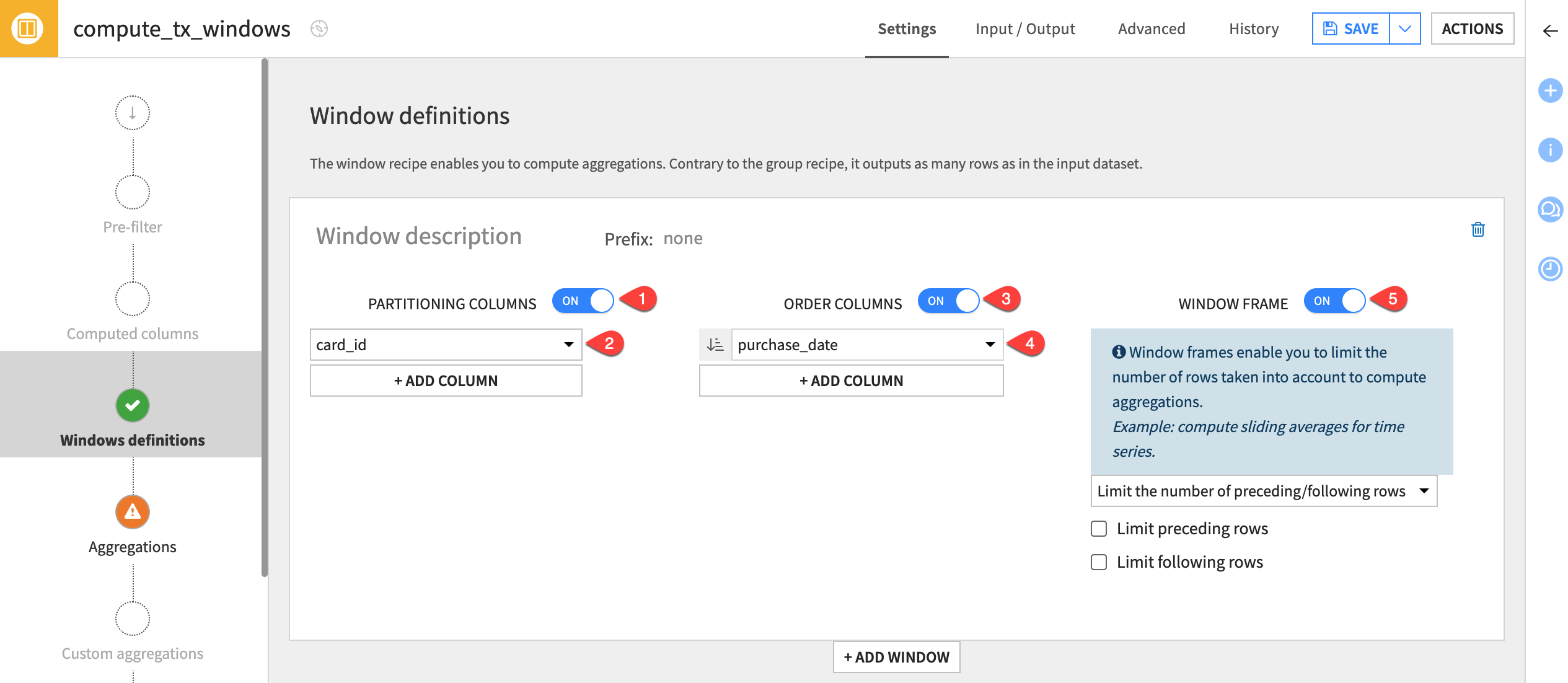
In the Windows definitions step, toggle on Partitioning Columns.
Choose card_id from the dropdown menu.
Toggle on Order Columns.
Choose purchase_date from the dropdown menu.
To ensure its deterministic, click + Add Column, and select id from the dropdown menu.
For now, toggle on Window Frame, but make no further adjustments.
Next, you’ll choose the aggregation(s) to compute for any given window. A sum total is a good choice to get started because it’s simpler to double check the results.
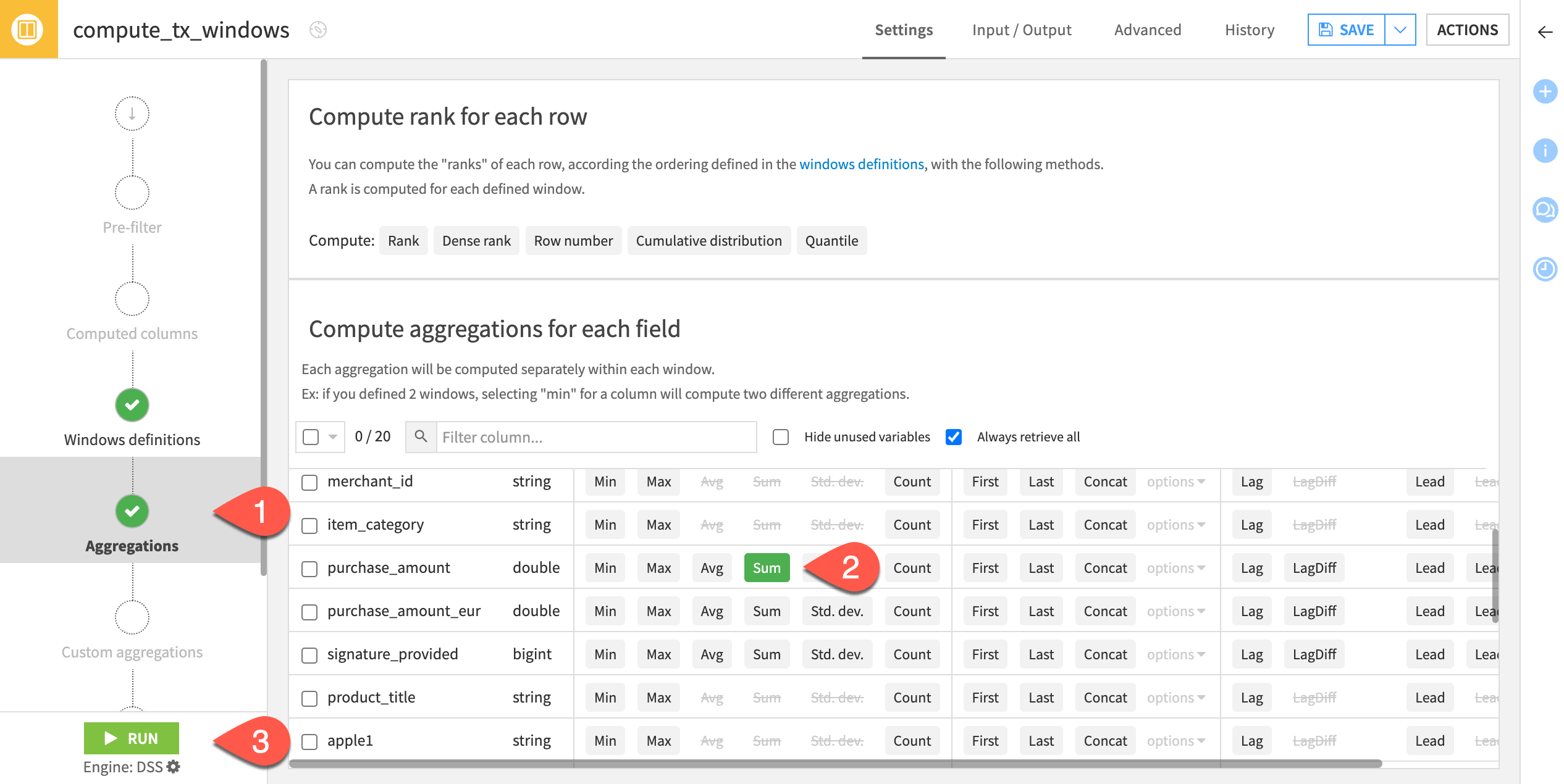
Navigate to the Aggregations step.
For the purchase_amount column, compute the Sum.
Click Run to execute the recipe.
Interpret the output#
Unlike the Group recipe, the Window recipe retains the schema of columns not included in the aggregation. The only change to the schema is the addition of the purchase_amount_sum column.
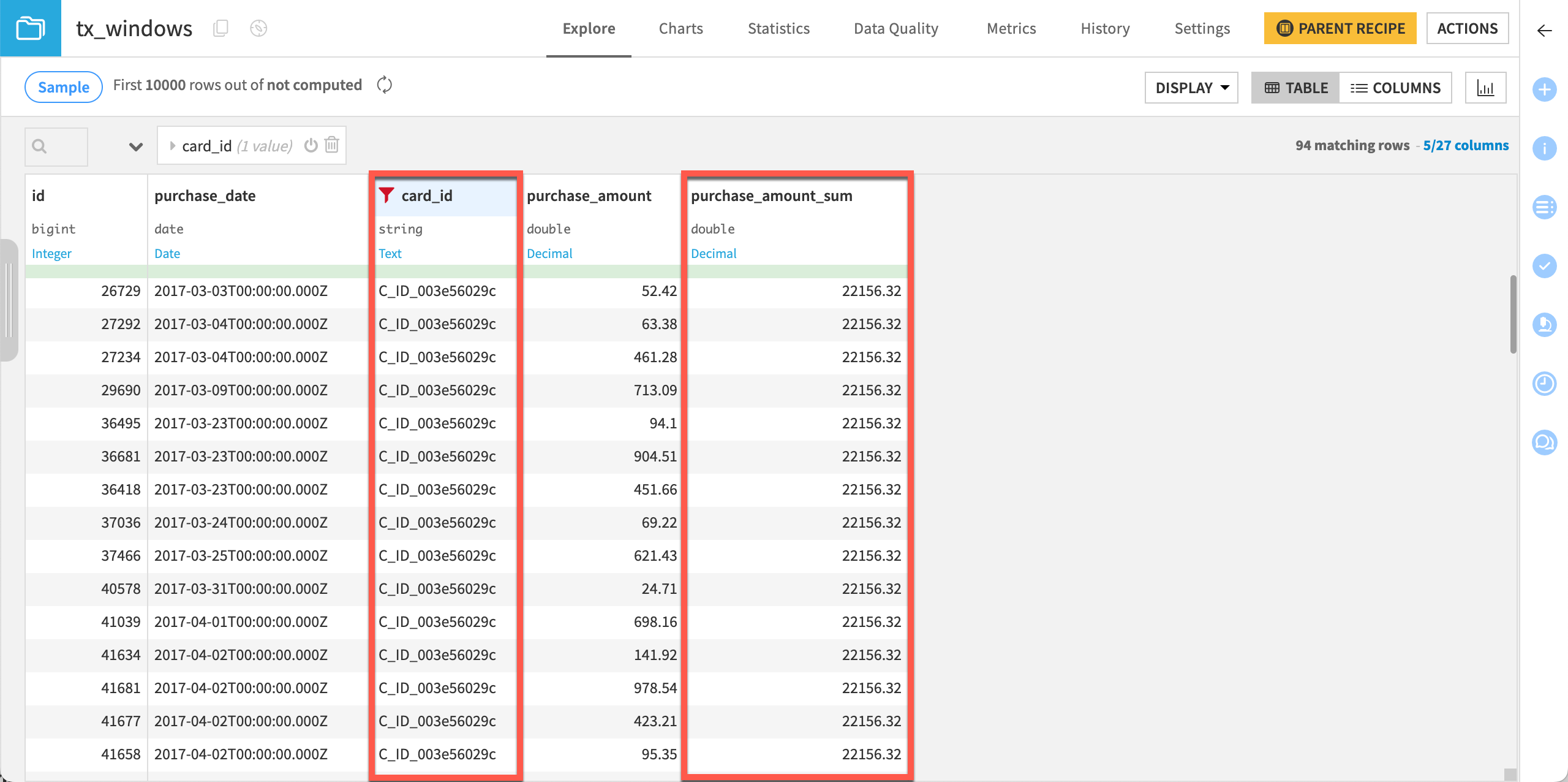
Now, interpret the recipe output. For clarity, filter the results for a specific card_id since that’s the partitioning column.
Open the output tx_windows dataset.
Click Display > Select displayed columns. Keep only the following five columns:
id
purchase_date
card_id
purchase_amount
purchase_amount_sum
Open the column dropdown header of card_id, and select Filter.
Select a frequent card_id value, such as
C_ID_003e56029c.Confirm that the purchase_amount_sum is the same for each row. This is because the unbounded window frame included all purchase amounts for that credit card in the aggregation.
Define the window frame bounds#
Before defining the bounds of the window frame, the purchase_amount_sum values are the same as what you’d find with a Group recipe (though with a different schema).
Most often though, you’ll want to define the bounds of the window frame. In other words, decide which rows — relative to the current row — to include in the aggregations.
Limit following rows#
For a cumulative sum, you need to exclude rows after the current row from the window frame.
From the windowed output, click Parent Recipe to reopen the Window recipe.
Under the Window Frame settings, select the Limit following rows checkbox and leave the number of rows as
0. This will set the window to be all rows before and including the current row (but none after the current row).Click Run to execute the recipe, and open the output dataset.
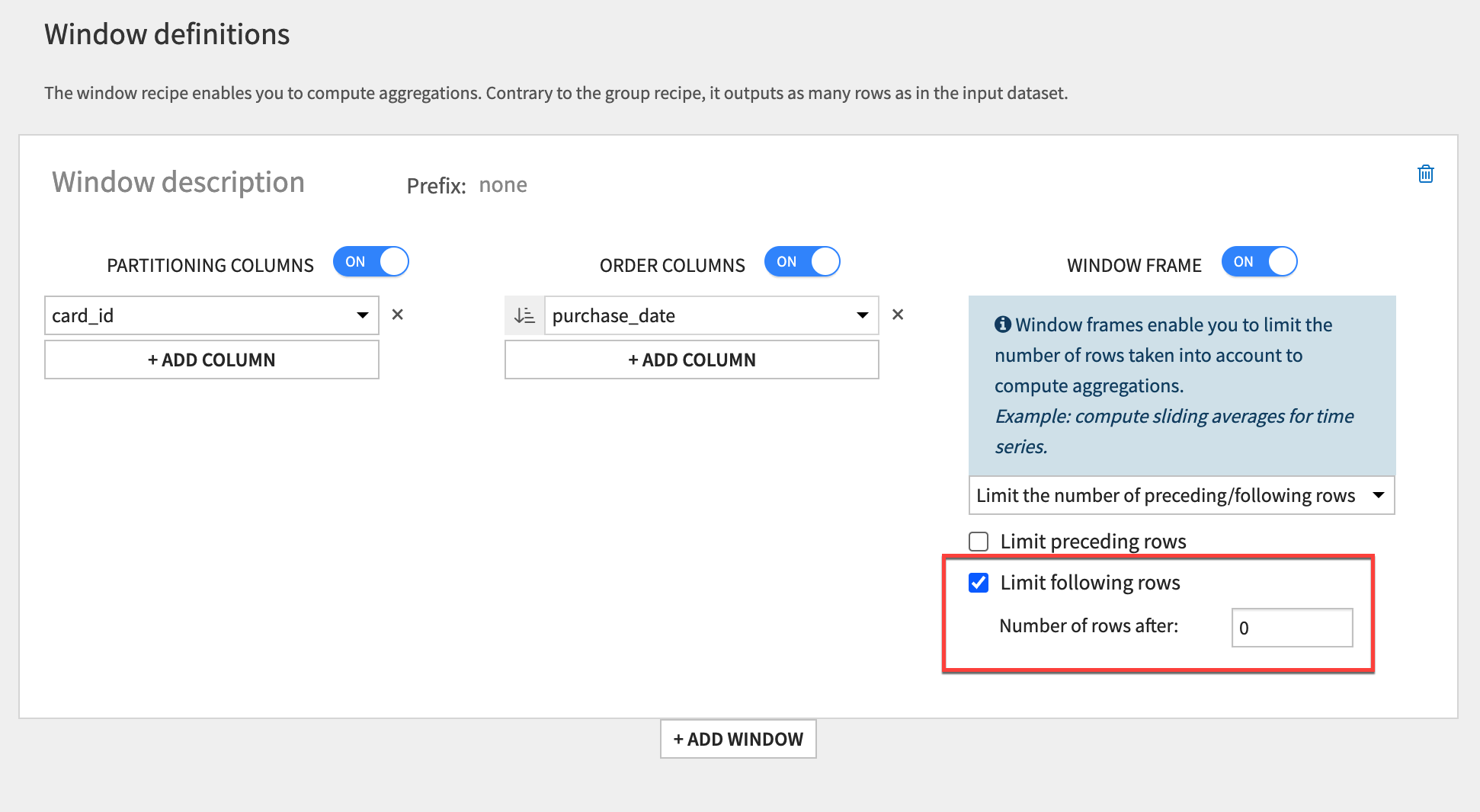
With the same filters applied in the output, observe how, for a given card_id, the purchase_amount_sum increases by exactly the purchase_amount of the current row.
Tip
Note how defining the row order is important since the calculations rely on the position of relative rows.
Limit preceding rows#
Instead of a cumulative sum, consider now a rolling sum. To achieve this, you need to define the boundaries of the window frame with respect to both before and after the current row.
From the windowed output, click Parent Recipe to reopen the Window recipe.
Select the Limit preceding rows checkbox.
Set the Number of rows before to
5so the window includes 5 rows before the current row.Set the Number of rows after to
-1so the window excludes the current row.Click Run to execute the recipe, and open the output.
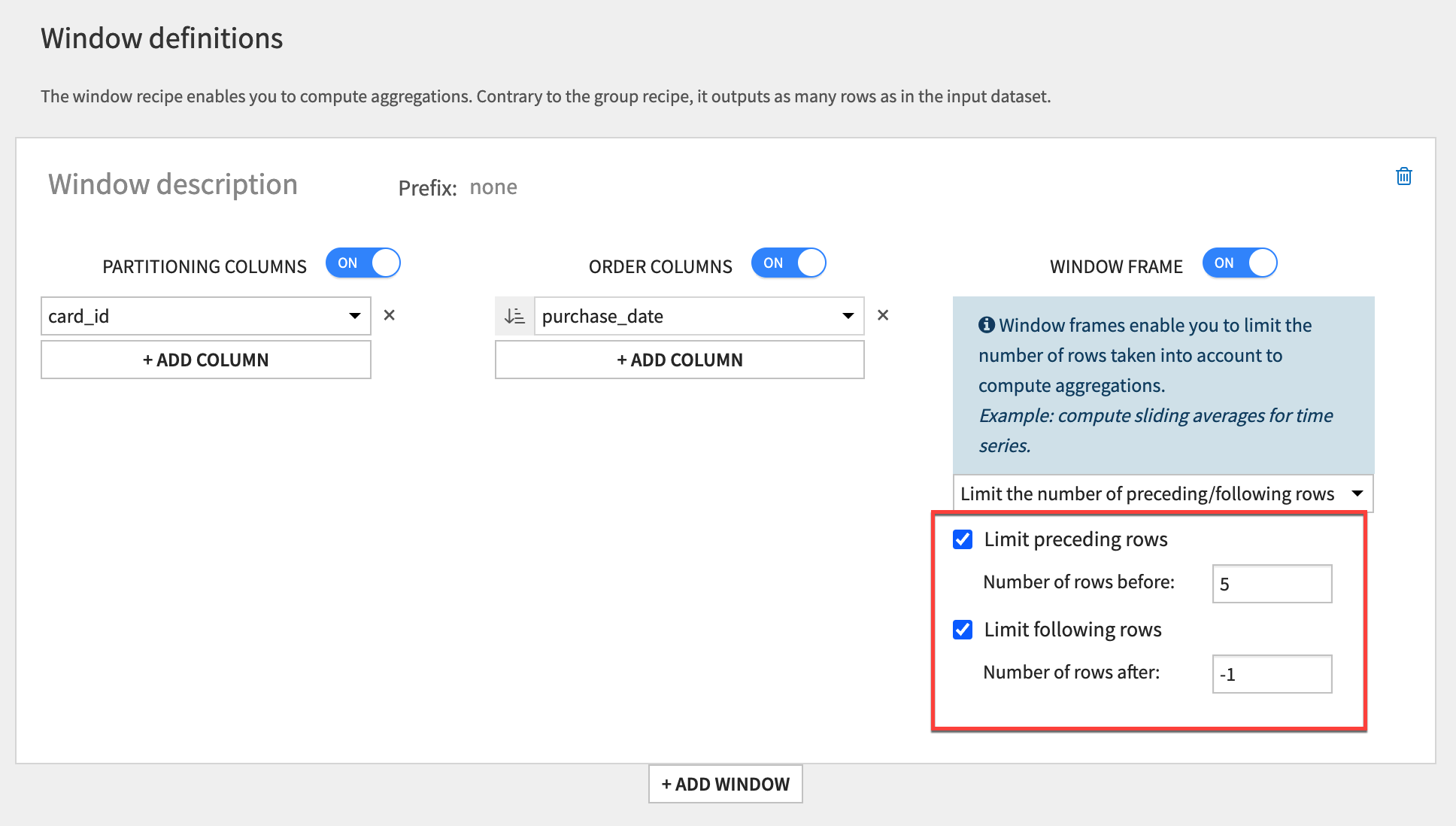
Keeping the same filters from the above example, trace the pattern in the purchase_amount_sum. Recognize that it records the total of the previous five rows (which are arranged in a deterministic order).
Use a value range#
Thus far, you’ve defined the window frame relative to the number of rows from the current row. However, you can also define the window frame relative to the values in a column. Ordering by a timestamp is a natural use case for this option.
For example, instead of computing the sum of the previous five purchases, you may want to compute the sum of all purchases from the previous five days.
One requirement is that you must specify exactly one ordering column for this option. When defining the window frame by row position, it was necessary to have deterministic ordering. With this data, that required two order columns. When defining the window frame on the values of an order column, there must be exactly one order column.
From the windowed output, click Parent Recipe to reopen the Window recipe.
Under Window Frame, select Limit window on a value range of the order column.
Set the lower bound to
5Set the upper bound to
-1.Change the window unit to Days.
Under Order Columns, delete the id column so only purchase_date remains.
Click Run to execute the recipe, and open the output.
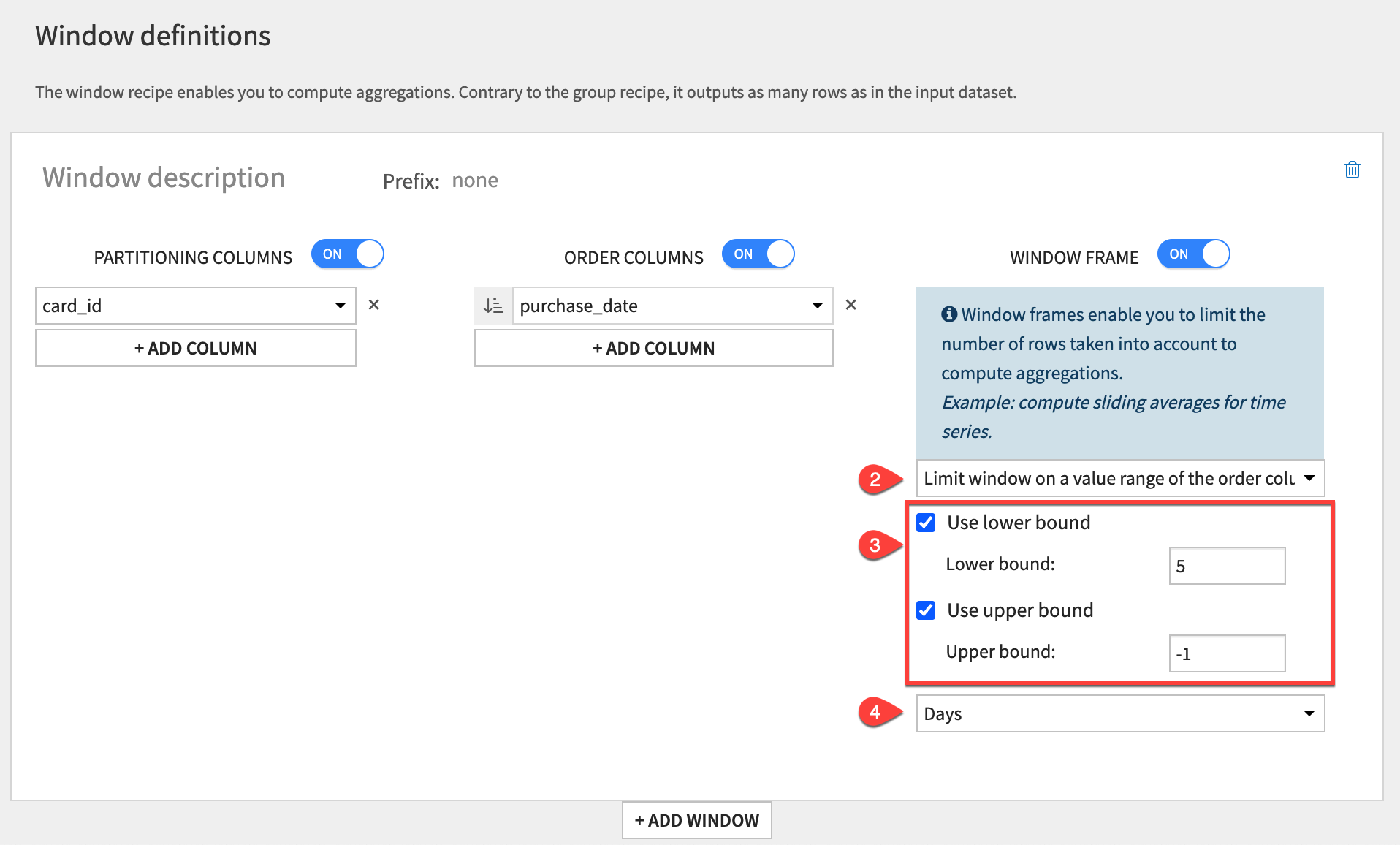
Observe how the values included in the window frame aggregation depend on the relative date instead of the relative rows.
Compute relative aggregations#
Until this point, you’ve only computed variations of rolling sums. However, the Window recipe also allows for new kinds of aggregations.
One set of aggregations focuses on the row’s relative position or standing within an ordered group. Rather than acting on a specific column, they’re used to compare rows to others in its group. These are functions for computing ranks, cumulative distributions, and quantiles. Think of leader boards or bucketing use cases.
Another set of aggregations provides access to the values in relative rows:
LeadandLagfunctions draw on the value in a relative row according to some number of offset rows.LeadDiffandLagDifffunctions compute a difference between the value in the current row and the value according to some number of offset rows.
For example, compute a customer purchase count and the difference between a customer’s current and previous purchases.
From the windowed output, click Parent Recipe to reopen the Window recipe.
On the Windows definition step, switch back to the original deterministic row order:
Order the rows by purchase_date and then id.
Limit the window frame by preceding/following rows.
Navigate to the Aggregations step.
Under Compute rank for each row, turn on Row number.
Under Compute aggregations for each field, also compute the Lag and LagDiff for purchase_amount. Keep an offset of
1.Click Run to execute the recipe, and open the output.
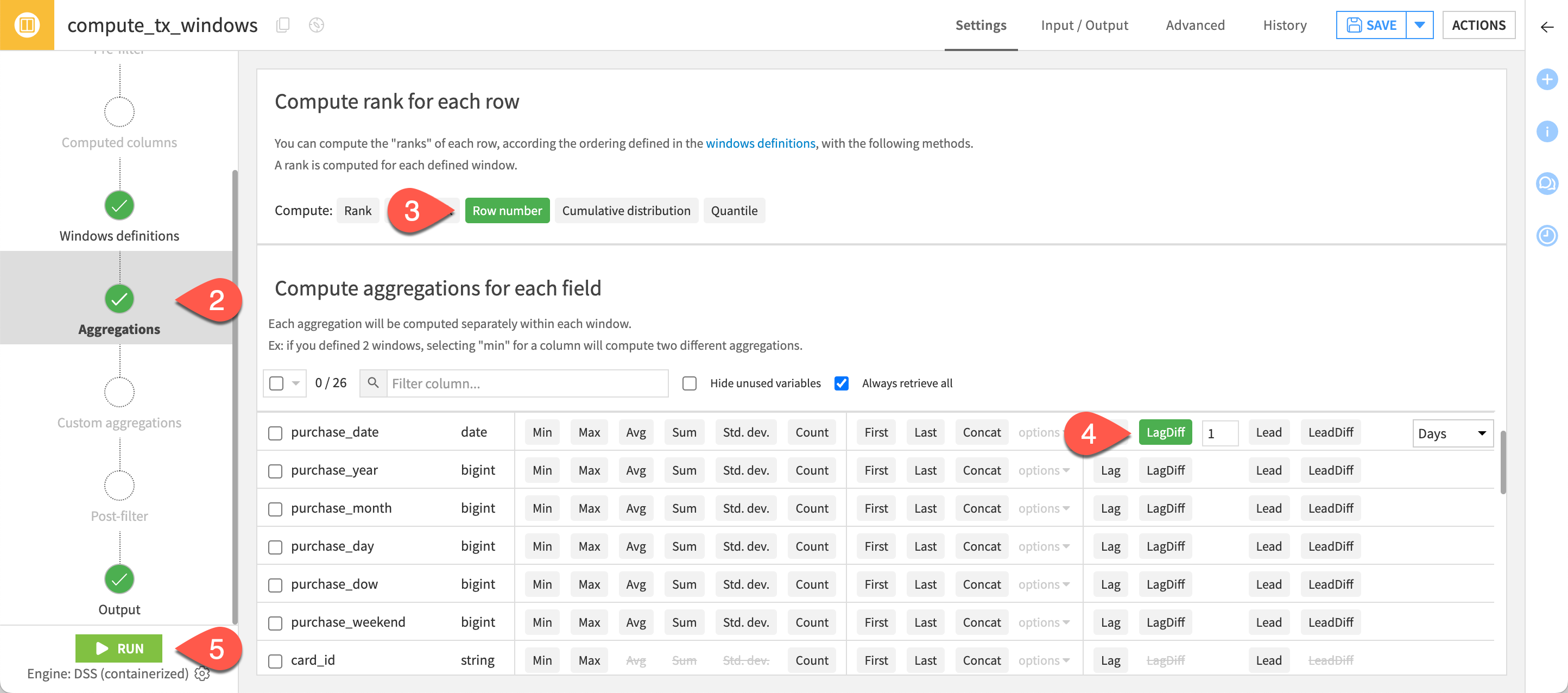
Inspect the behavior of the three new aggregations.
Rename output columns#
It’s possible to lose sight of the meaning of aggregated columns. You can fix that by editing column names in the Output step of the recipe.
From the windowed output, click Parent Recipe to reopen the Window recipe.
Navigate to the Output step.
Give the aggregated columns more meaningful names:
Current name
New name
purchase_amount_sum
previous_5_purchases_sumpurchase_amount_lag
previous_purchasepurchase_amount_lag_diff
previous_purchase_diffrownumber
purchase_countClick Run, and explore the output once more.
Next steps#
Congratulations! You used the Window recipe to enrich your dataset with new insights, while keeping the structure of the dataset intact.
See also
For more information on this recipe, see Window: analytics functions in the reference documentation.
Another useful data transformation to test out can be explored in Tutorial | Top N recipe!