Concept | Grouping variables in statistical testing#
Watch the video
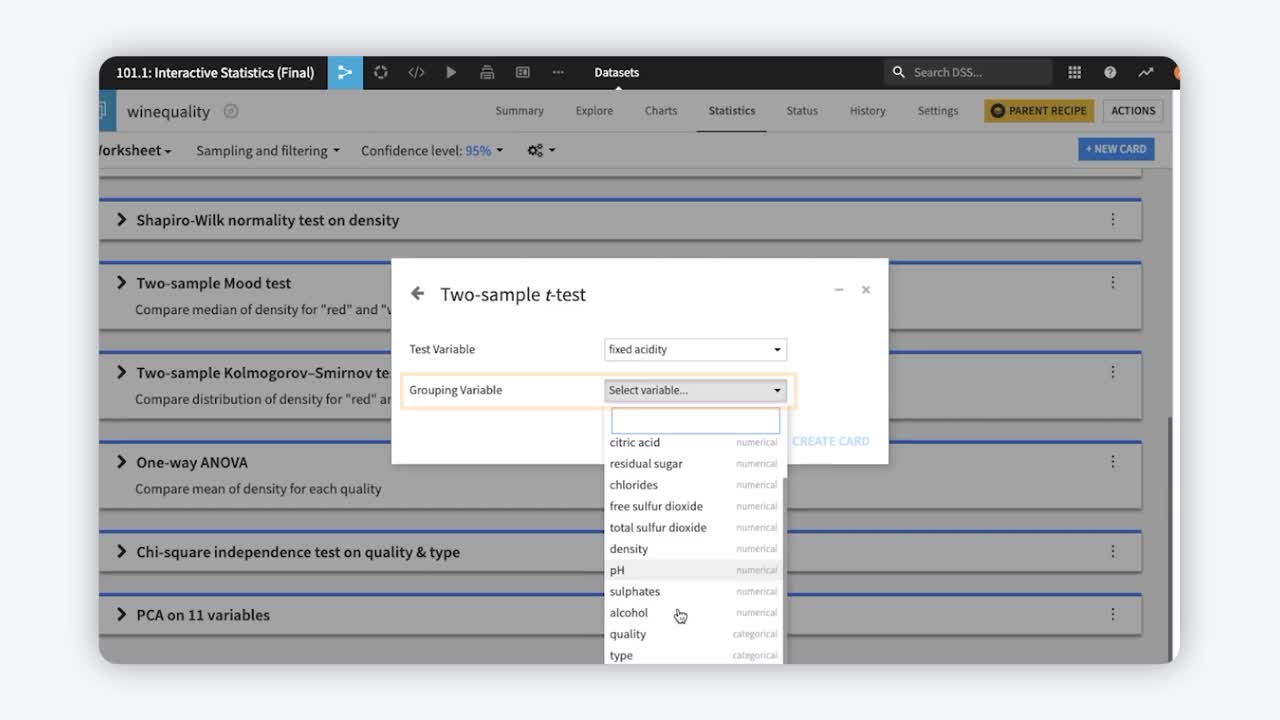
Grouping variables are used to split up a dataset into disjoint groups-—-one group for each unique value of the grouping variable. In statistical testing, grouping variables can be used to define populations.
If you’re familiar with the Group recipe, you may recall that it uses a group key to perform aggregations. This group key is based on the unique values of a particular column (or a combination of columns). It has similar functionality to the grouping variable.
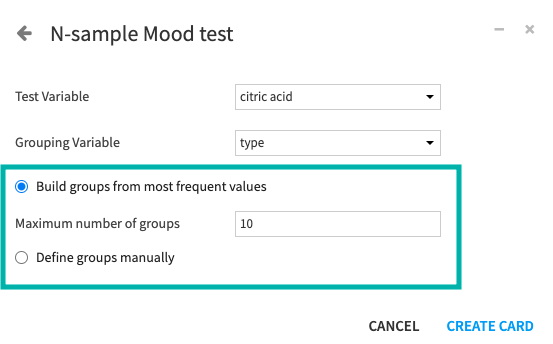
In Dataiku, when performing two-sample tests, you specify a numerical “Test Variable” and a Grouping Variable with 2 modalities (or groups). For the N-sample tests, specify a numerical “Test Variable” and a “Grouping Variable” with multiple modalities.
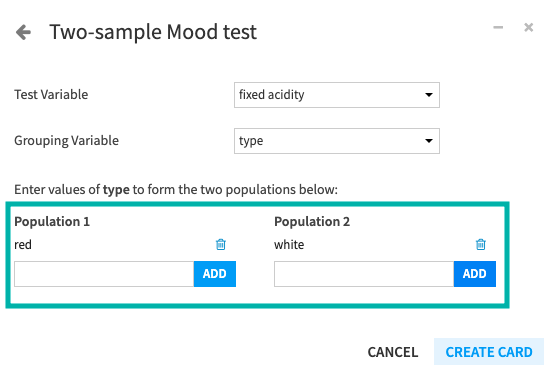
Furthermore, you can define test populations by manually specifying values from the Grouping Variable.
You can also define test populations by building groups from the most frequent values of the grouping variable, and specifying a value for the Maximum number of groups. This value limits the number of modalities, if your grouping variable is categorical, or limits the number of bins if your grouping variable is numerical.