
Concept | Group recipe#
Watch the video or read the summary below.
The Group recipe lets you aggregate the values of columns by the values of one or more keys.
Use case#
At many points throughout an analytics process, you might need to perform various types of aggregations based on the values of particular columns.
For example, consider a dataset in long format where each row is a unique credit card transaction. Instead of thinking in terms of transactions, your analytics process might require further analysis into questions such as:
Who do the cards belong to?
Where did the transactions occur?
Which merchant charged the expenses?
The answers to these kinds of questions require a dataset where each row, instead of a distinct transaction, is a distinct customer, place, or merchant.
For each of these groups, you could compute many possible aggregations:
The first purchase date per customer
The count of transactions per ZIP code
The average purchase amount per merchant
To give one concrete example:
The dataset on the left is a simplified dataset of distinct transactions.
The dataset on the right computes grouped aggregations: the maximum and sum of amounts per distinct customer.
Important
On the left, the same customer can appear multiple times since a customer can make multiple transactions. On the right though, a distinct customer can appear only once.
Grouped aggregations with other technologies#
Depending on your previous experience with data tools, you’ve likely already computed grouped aggregations.
Technology |
Tool/Function |
|---|---|
Excel |
Pivot table / Power Query –> Group By |
SQL |
|
Python (pandas) |
|
R (tidyverse) |
|
You could perform the same SQL, Python, or R operation with a code recipe. However, in Dataiku, you’ll often want to reach for the visual Group recipe for this kind of data transformation.
Group recipe configuration#
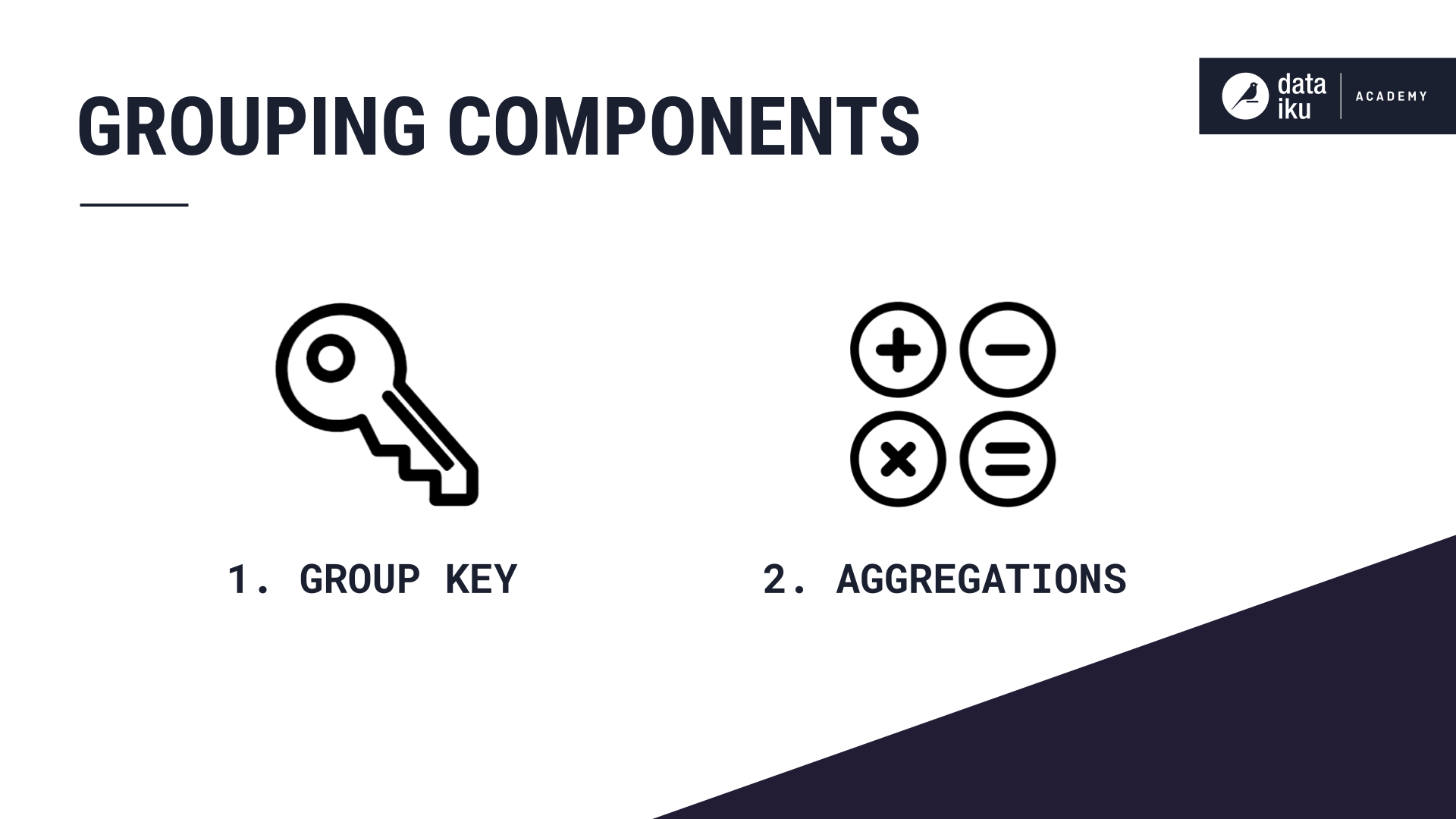
Configuring the Group step of the Group recipe has two important components:
Field |
Defines |
Example |
|---|---|---|
Group keys (1) |
How to divide records into distinct subsets |
customer |
Per-field aggregations (2) |
What to compute within each subset |
Maximum and sum of amount |
Group key notes#
In the example above, a single column serves as the group key, but it’s possible to have multiple group key columns. For example, if grouping orders by month, separate columns for year and month together could serve as the group key columns. In this case, the number of output rows would be equal to the number of distinct combinations of values in both key columns.
Tip
Unless using a pre- or post-filter step, the output dataset will always have the same number of rows as unique combinations of values in the group key columns.
Aggregation notes#
The available aggregations depend on the column storage types. (You can’t compute the average of a string column).
If you haven’t selected an aggregation for a particular column, that column won’t appear in the output. See the Window recipe if this isn’t what you want.
If the column you need for an aggregation doesn’t exist in the dataset, you can create it with SQL or Dataiku formulas on the Computed columns step before the group operation.
If none of the native aggregations meet your needs, you can also define custom aggregations in SQL on the Custom aggregations step.
Tip
For eligible in-database computations, you can view the SQL query underneath the visual layer by clicking View Query in the recipe’s Output step.
Next steps#
Now, you know how to perform group-wise aggregations using the Group recipe!
Continue learning about this recipe by working through the Tutorial | Group recipe article.
Tip
You can find this content (and more) by registering for the Dataiku Academy course, Visual Recipes. When ready, challenge yourself to earn a certification!