
Concept | Custom preprocessing within the visual ML tool#
Watch the video

Feature preprocessing in the visual machine learning (ML) tool (or interface) of Dataiku is performed right before model training and can be modified from one training session to another.
In this article, we’ll show the different ways to access custom Python preprocessing libraries and apply them in the visual ML tool of Dataiku.
Custom preprocessing in the visual ML tool#
The visual ML tool lets you apply built-in feature preprocessing or custom preprocessing methods to your data. For example, you can apply preprocessing to features that are numerical, categorical, text, images, etc.
To access custom preprocessors, go to the Design tab of the visual ML interface and click the Features handling panel.
For example, when we select a numerical feature, Dataiku displays its summary statistics and some built-in feature handling methods. From the numerical handling dropdown menu, you can choose the Custom preprocessing option, and a code editor will appear.
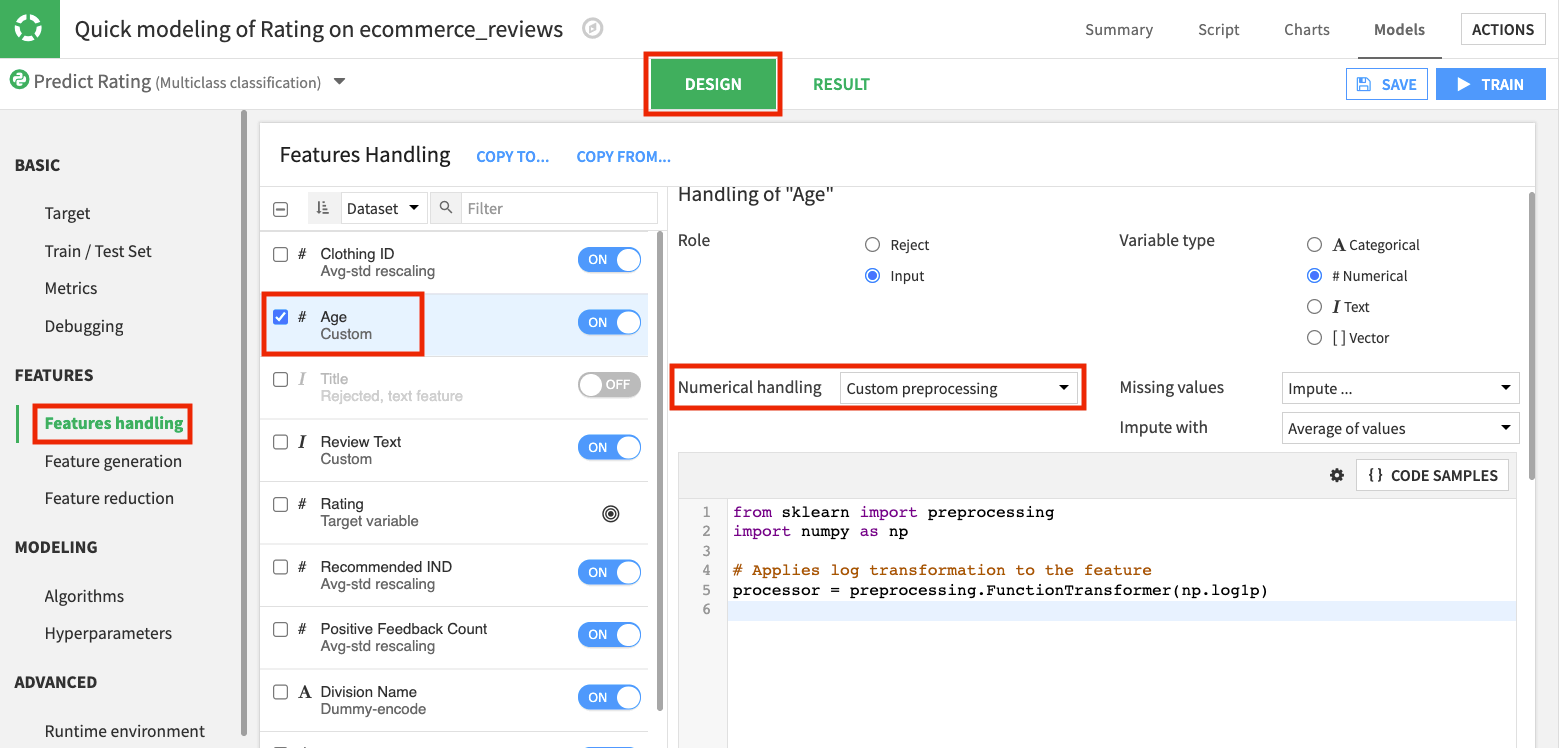
Within this code editor, you can write your own preprocessor using Python code. You can also select from available code samples by clicking on the Code Samples button.
Guidelines for using a custom preprocessor#
Consider the following guidelines when using a preprocessor in the visual ML tool:
The preprocessor must be scikit-learn compatible, having a
fit()and atransform()method.While you can define a preprocessor in the code window, it’s best practice to define any classes and functions in the project’s Python library and instantiate them in the code window.
Additionally, you can import preprocessors from libraries that are included in the code environment used by the visual ML tool.
Note
You can specify the code environment used by the visual ML tool from the Runtime environment panel.
Libraries in the visual ML tool#
All libraries that you import into the visual ML tool must exist in:
The code environment used by the visual ML tool.
The project’s Python library.
Or the global Python library of the Dataiku instance.
For example, scikit-learn is included in the default, built-in code environment of Dataiku. However, to access NLTK stop words, the visual ML tool must use a code environment with the NLTK package installed.
Next steps#
Continue learning about custom preprocessing in the visual ML tool by working through Tutorial | Custom preprocessing & modeling within visual ML.
You can also see Concept | Custom modeling within the visual ML tool to learn how to implement custom models.