
Concept | Recipe engines#
Watch the video or read the summary below.

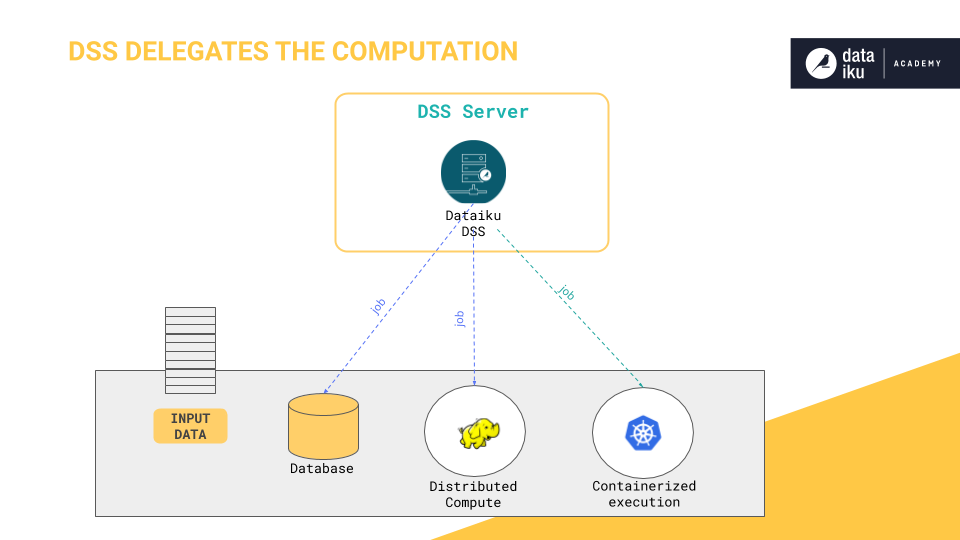
Computation has a cost. In Dataiku, there are computation strategies that help with reducing this cost. Dataiku can perform the computation using the DSS engine or push down the computation to external engines. Dataiku acts as an orchestrator of your connections’ engines, delegating the computation to these connections when possible.
See also
For more information, see Execution engines in the reference documentation.
Sampling#
When transforming your dataset, you are actually working with a sample of it. Working with a sample allows Dataiku to provide fast and responsive visual feedback on your preparation steps, no matter the size of the whole dataset.
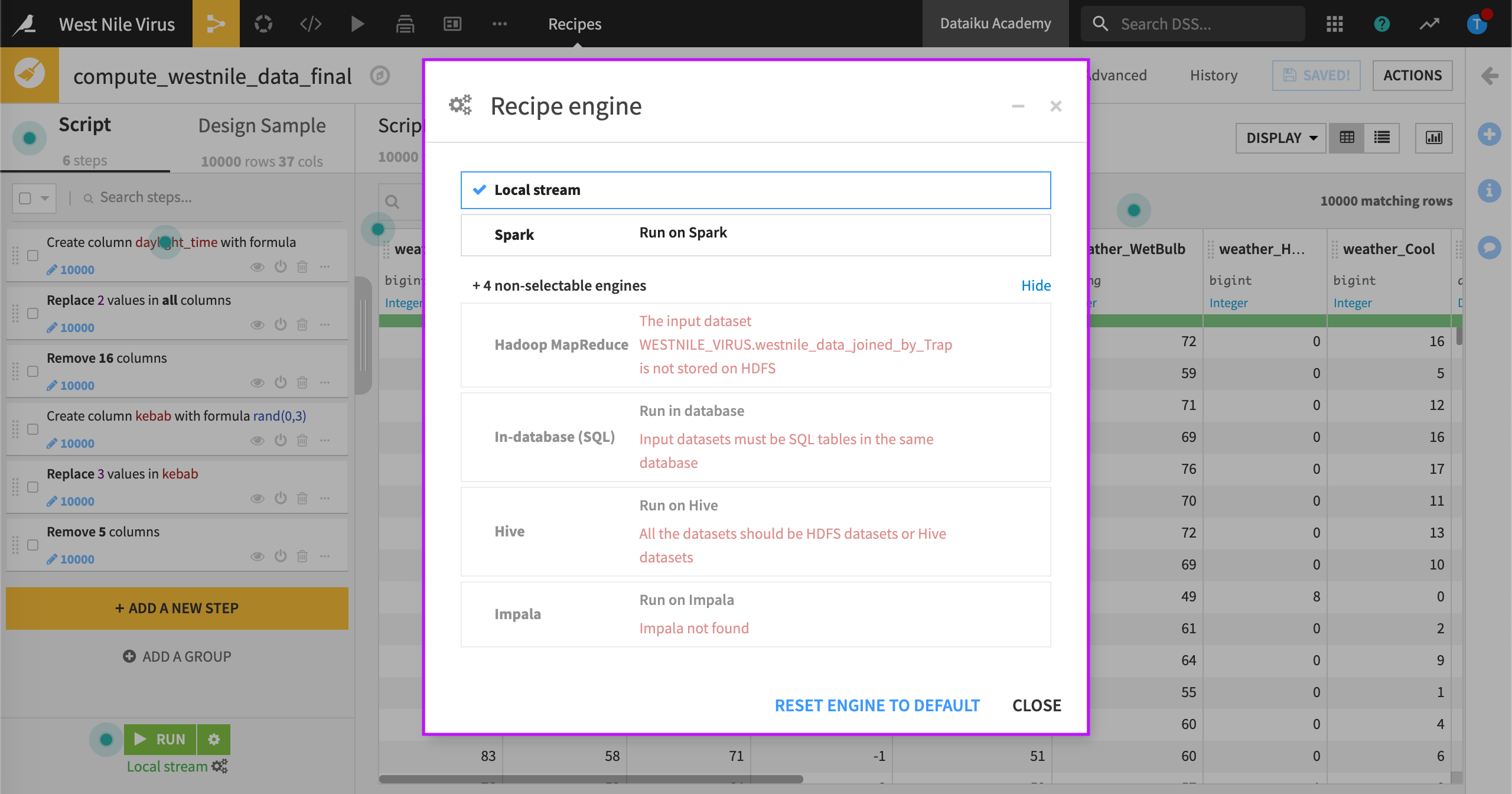
When you are ready to apply transformation steps to the whole dataset, click Run. Dataiku selects a recipe engine that best fits the underlying data storage and the operation you are applying to the dataset.
Recipe engines#
Computation in Dataiku can take four main forms, described in the table below.
Recipe engine |
Description |
|---|---|
In DSS engine |
For in-memory execution, the data are stored in RAM. This strategy is used, for example, to execute Python or R recipes. For streamed execution, Dataiku reads the input dataset as a stream of rows, applies computation to the rows as they arrive, and writes the output datasets row per row. |
In database |
This strategy is used, for example, to execute SQL queries. The visual recipe is translated into an SQL query, which is then injected, or pushed down, to the SQL server. |
On Hadoop / Spark cluster |
Depending on the chosen engine, the visual recipe is translated into a Hive, Impala, or Spark SQL query, which is then injected, or pushed down, to the Hadoop or Spark cluster. When operating on small datasets, Dataiku might also choose the DSS engine to speed up computing. |
In Kubernetes / Docker |
This strategy is also in-memory or streamed but uses container execution through Docker and Kubernetes clusters rather than the Dataiku host server. |
To avoid running out of memory when manipulating large datasets, Dataiku recommends offloading the computation to where the data lives. This way you avoid bringing all the data into memory or streaming it through the Dataiku server.
Next steps#
In this article, you learned about ways to optimize computation when working in Dataiku. Get hands-on experience with this concept in Tutorial | Recipe engines.