
Concept | Data connections#
Watch the video or read the summary below.

Dataiku lets you change, shape, and analyze your data through a variety of actions. It also enables you to perform these manipulations on externally stored datasets through connections.
See also
As a developer, for more information on connections, see the following articles in the Developer Guide:
Connections (Concept and examples)
Connections (Python API reference)
Let’s see how Dataiku manages connections to make this possible.
Managing connections#
Instance administrators can configure connections in the waffle (![]() ) > Administration > Connections menu.
) > Administration > Connections menu.
From here, they can control settings such as credentials, security settings, naming rules, and usage parameters. Admins can also establish new connections to SQL and NoSQL databases, cloud storage, and other sources. Many additional connection types are available in the plugin store for any non-native connections.
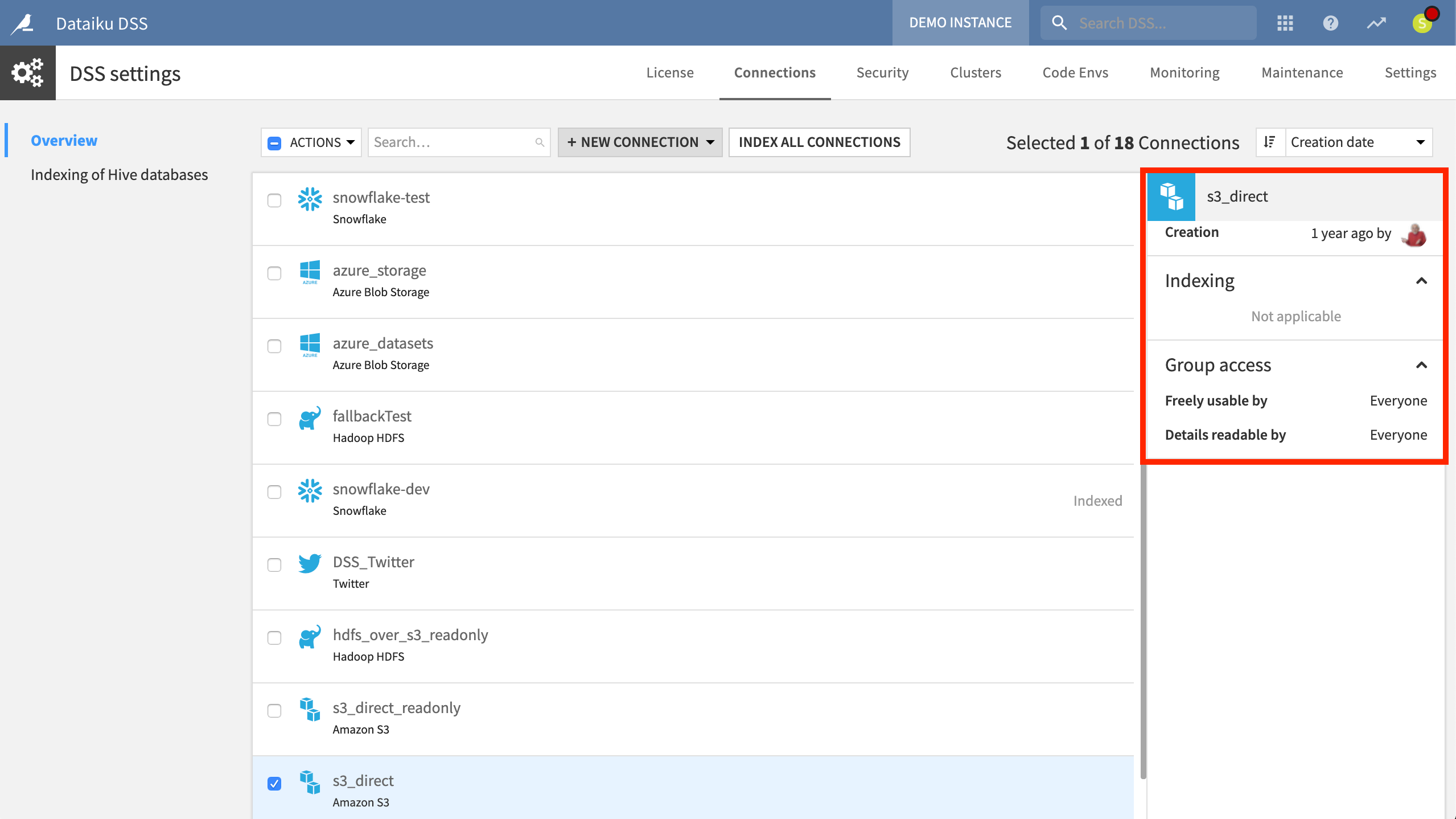
One benefit of this system is a clearer division of labor between those who manage data connections and those who work with data.
While understanding a dataset’s storage is often beneficial (particularly with large datasets), those working with data don’t always necessarily need expertise in how their organization warehouses its data.
Importing a new dataset#
You can import a new dataset in the Flow by uploading your own files. You can also access data through any previously established connections, such as SQL databases, cloud storage, or NoSQL sources. You might also have plugins allowing you to import data from other non-native sources.
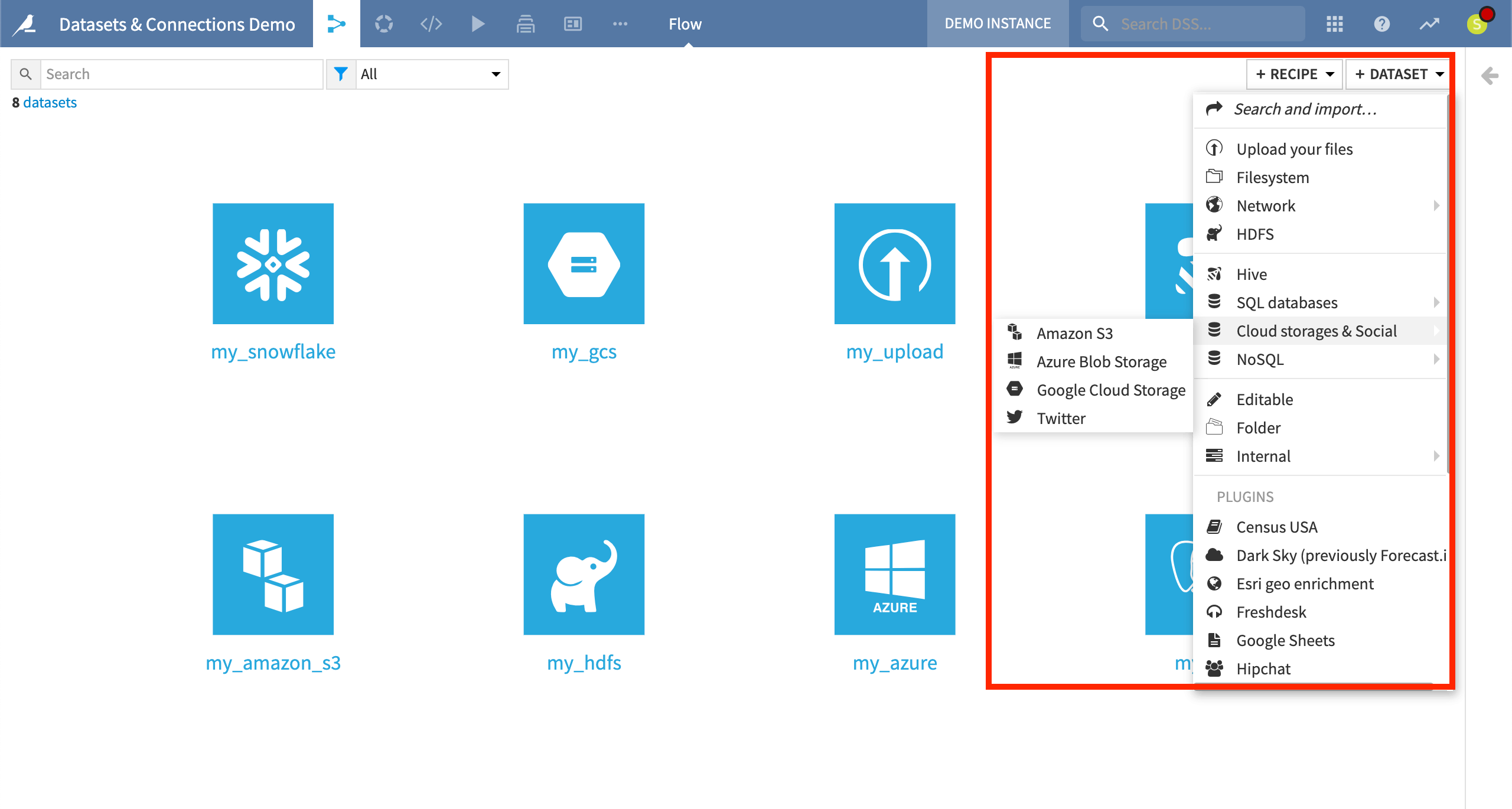
While importing a dataset, you can browse connections and available file paths, and preview the dataset and its schema.
Once you have done that, the user interface for exploring, visualizing, and preparing the data is the same for all kinds of datasets. This is because Dataiku decouples the processing logic that acts upon a dataset from its underlying storage infrastructure.
Next steps#
In this article, you learned to work with datasets in Dataiku that have different underlying connections or storage infrastructure. Continue getting to know the basics of Dataiku by learning about dataset characteristics.
Also, connections are closely related to how Dataiku selects a recipe engine s to execute computation. Learn more about these with Concept | Recipe engines.