Concept | Multimodal ML using LLMs#
Data scientists often incorporate multiple types of data, such as images, text, and tabular data, into one machine learning model to get the most complete picture of the problem at hand. Using multiple representations of the same subject can increase model performance.
This concept of bringing together multiple modalities of data into one model is known as multimodal machine learning. Multimodal models are common in many domains, such as healthcare, manufacturing, and even sentiment analysis.
In Dataiku, you can incorporate images and text into models using visual ML tools and a connection to a large language model (LLM).
Important
To use the multimodal features of Dataiku’s visual ML tools, you need:
Dataiku version 13.0+
A supported LLM connection (in which you have enabled embedding models)
To embed images, a local model from HuggingFace (required) and GPU (highly recommended)
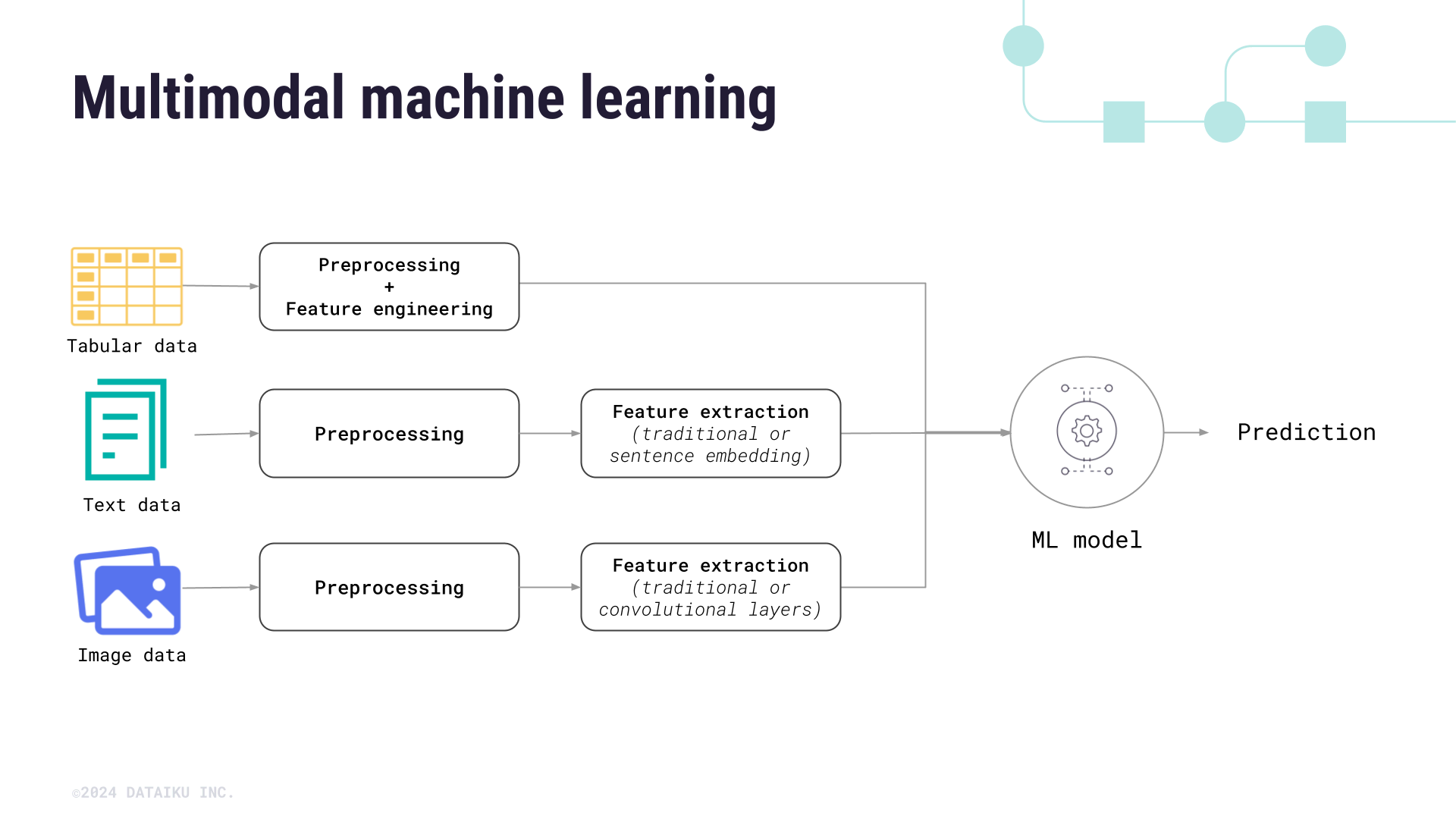
Preparing data for multimodal models#
To use multiple modalities of data, you must extract features from the images or textual data. In Dataiku, this is done through an LLM connection. An administrator must create the LLM connection via the LLM Mesh.
You can add the text or image features and select the LLM used to embed them when designing a model. But first, the features must be included in a training dataset.
For text, simply make sure the text is a column within the training data.
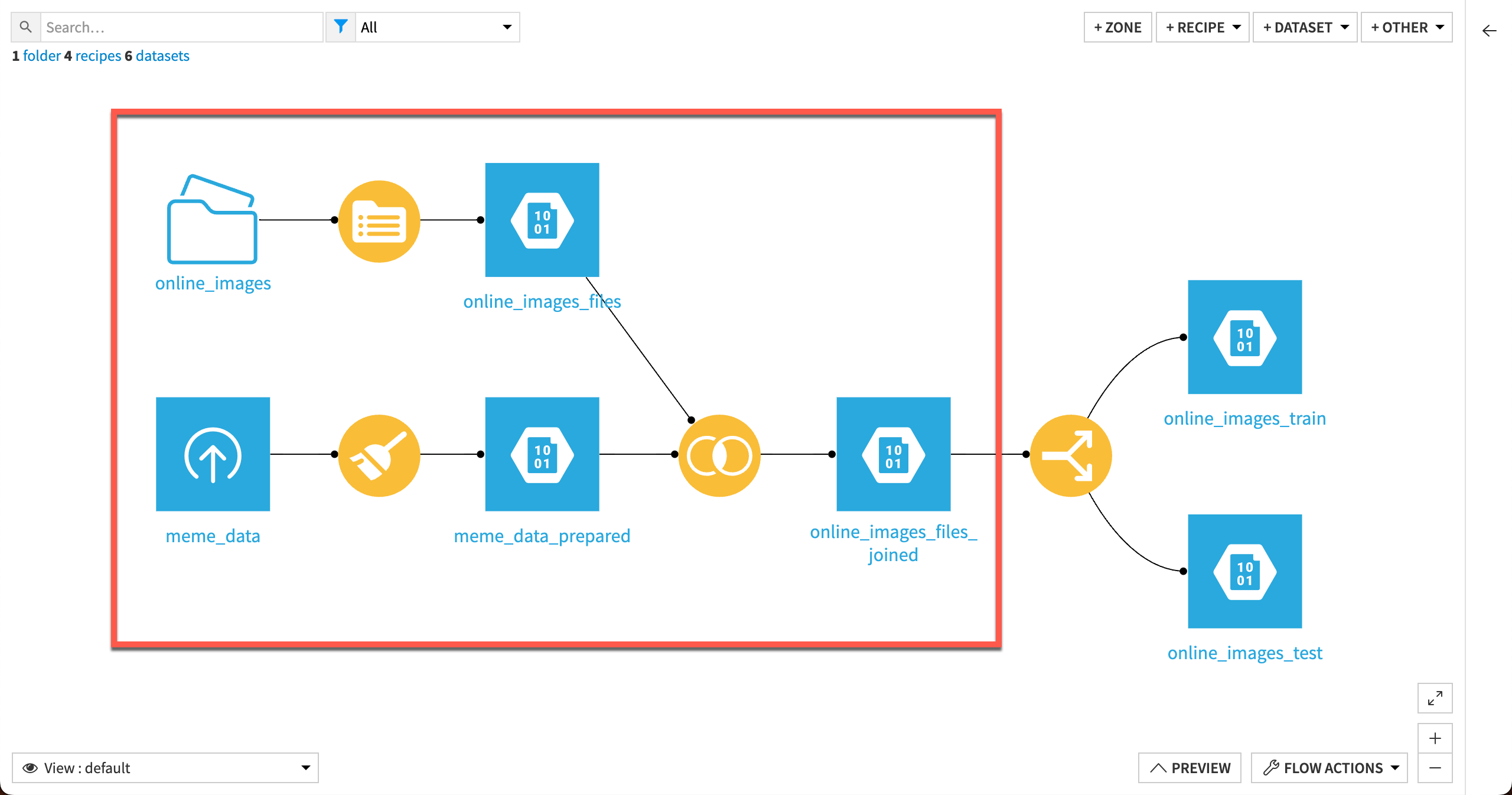
Images require a few extra steps to be included in training data:
Store images in a managed folder.
Run a List Contents recipe on the folder to create a dataset that includes the image file paths. The model will use these paths to identify images.
Join the image path dataset with the main training dataset containing the model target.
Build a model as usual from the joined dataset.
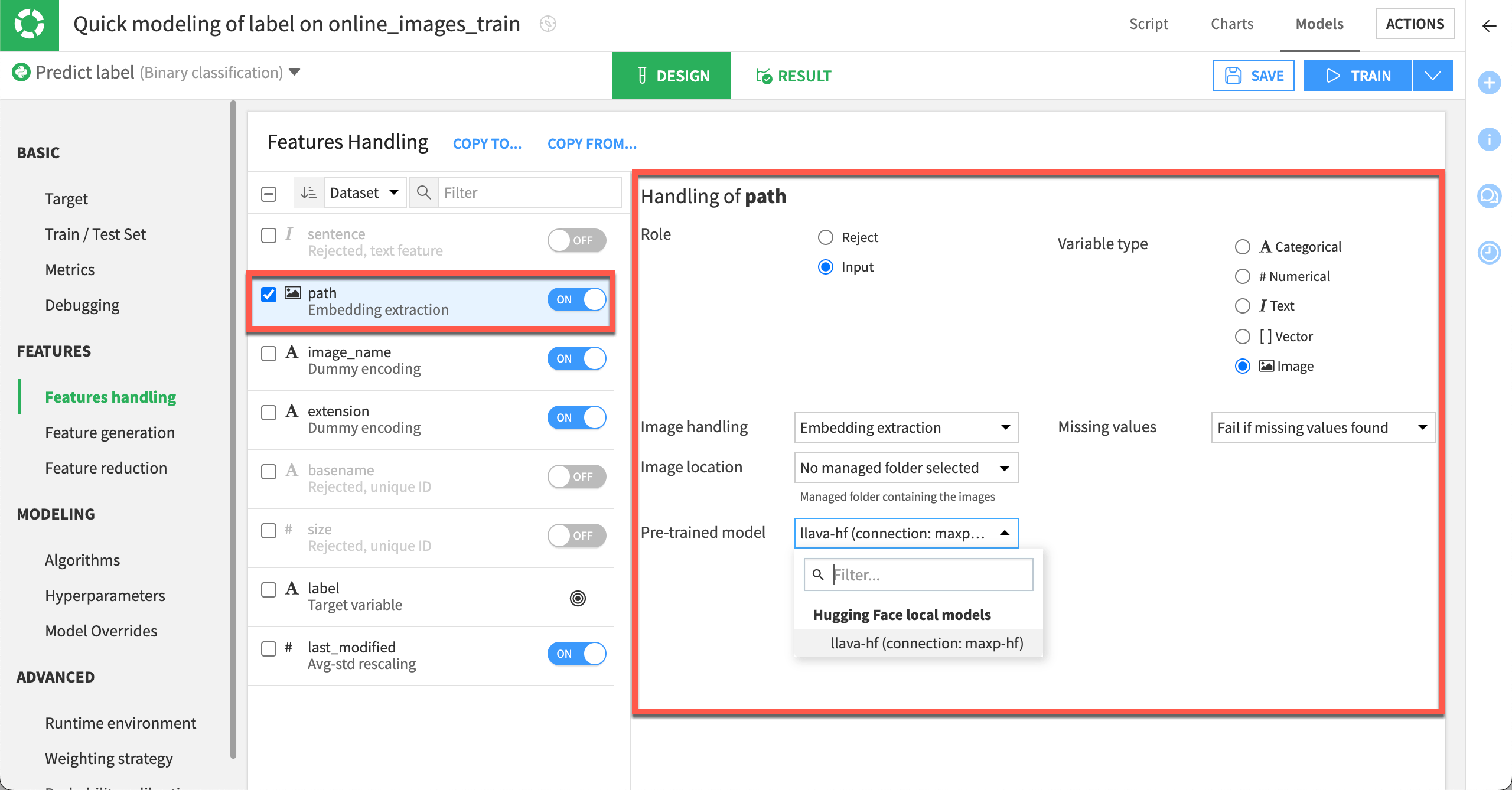
Feature handling#
Multimodal features will be available along with other features in the Features handling section of the model Design tab. The model will reject text and image features by default.
Toggle the feature On in the Features handling page. (For images, the feature will be identified by the file path column pointing to the image in the managed folder.)
Select the correct variable type (text or image).
- Specify the handling technique:
For text, choose Sentence embedding.
For images, choose Embedding extraction and select the image location (managed folder).
Select the pretrained LLM to process the feature.
You can then train the model with the multimodal inputs.
Note
Dataiku provides other methods to handle text features in AutoML models. See Text variables for details.