
Concept | Quick models in Dataiku#
Watch the video or read the summary below.
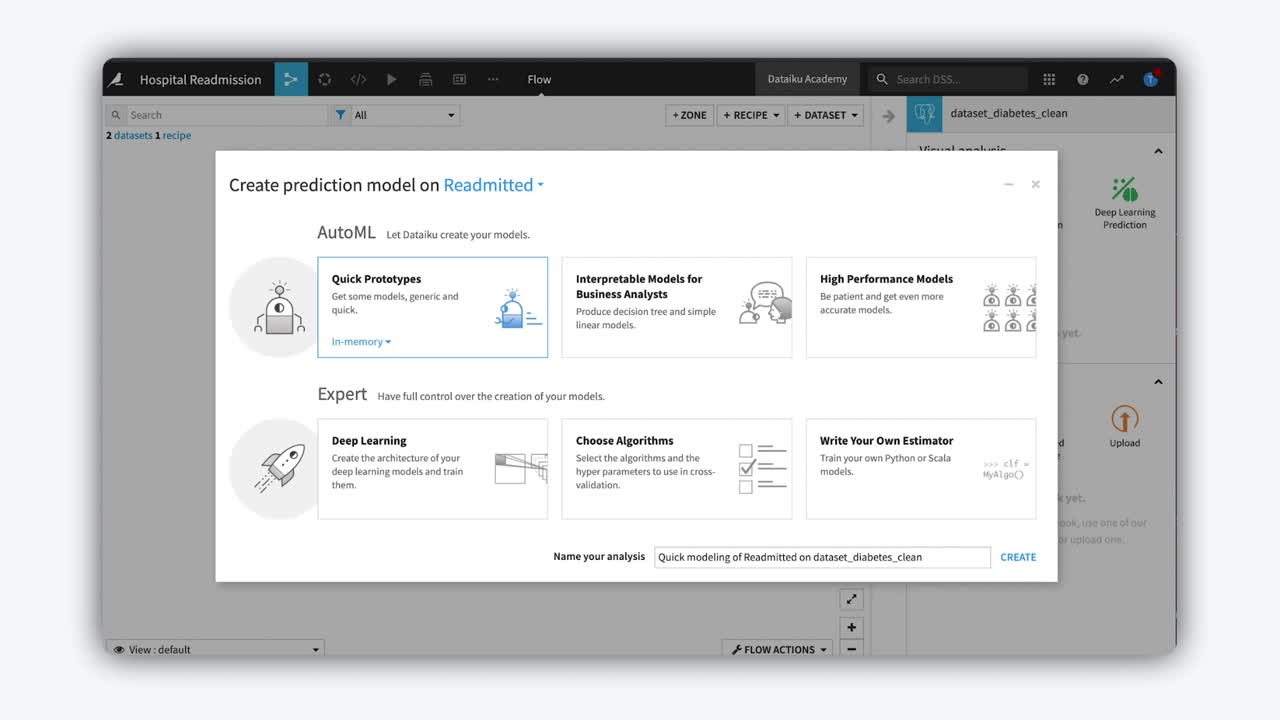
You can use visual machine learning in Dataiku to train several machine learning models in just a few steps. Building your machine learning model happens in the Lab. The Lab is a place for drafting your work, whether it’s preliminary data preparation or machine learning model creation.
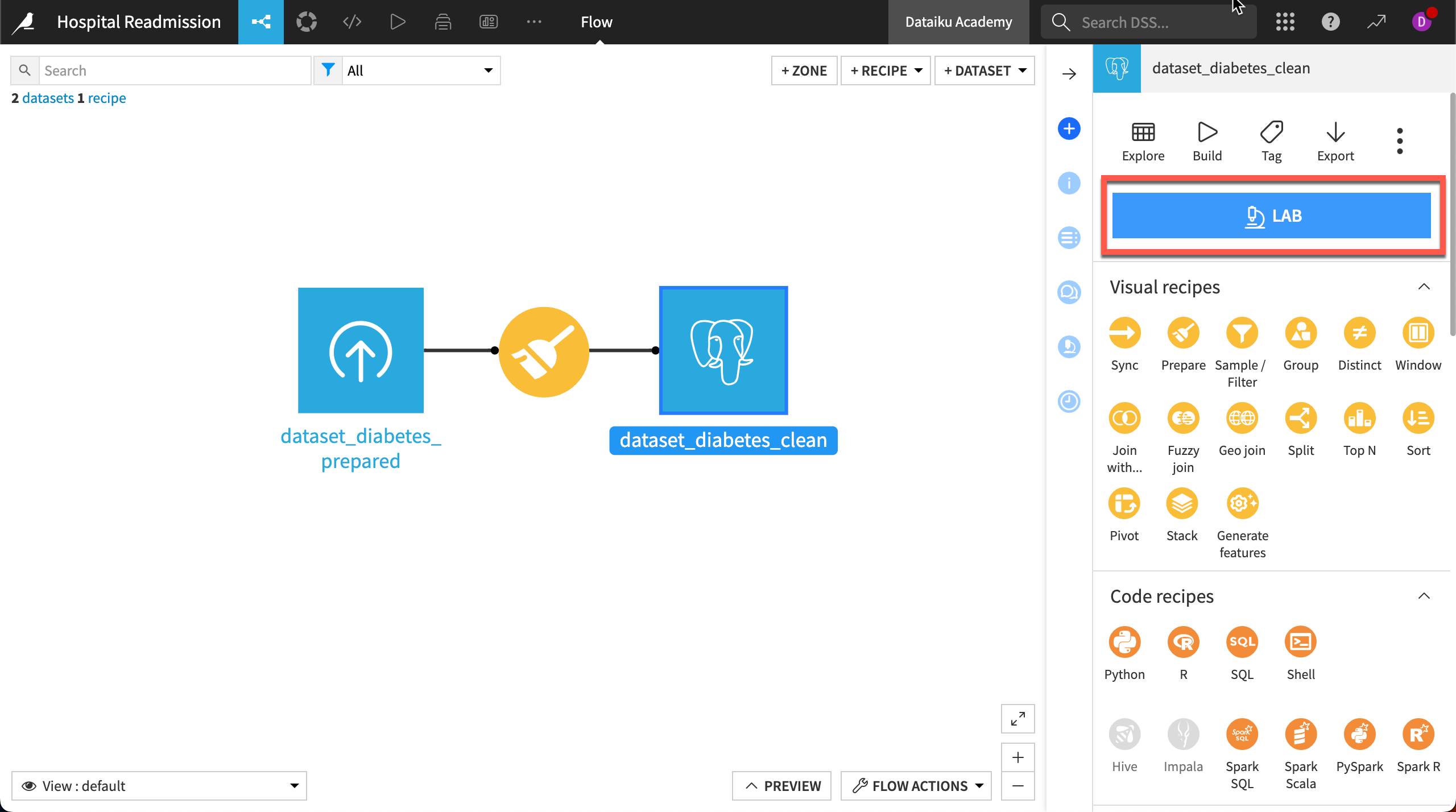
Clicking on the Lab button displays Visual ML options for the different kinds of modeling tasks.
Note
Different kinds of modeling tasks
Prediction
Prediction relates to supervised learning problems where the variable to predict is available in a labeled train dataset. Prediction models are learning algorithms that are supervised. That is, they’re trained on past examples for which the actual values (the target column) are known. The nature of the target variable will drive the kind of prediction task.
Regression is used to predict a real-valued quantity (i.e a duration, a quantity, an amount spent…).
Two-class classification is used to predict a Boolean quantity (i.e presence / absence, yes / no…).
Multiclass classification is used to predict a variable with a finite set of values (red/blue/green, small/medium/big…).
Clustering
Clustering refers to unsupervised learning problems where the target is unknown, and you’re looking to find patterns and similarities in your data points.
Clustering models are inferring a function to describe hidden structure from unlabeled data. These unsupervised learning algorithms are grouping similar rows given features.
In this example, we want to build a prediction model for a supervised learning problem where we want to predict whether a patient will be readmitted to the hospital or not.
When building a supervised learning model, you’ll also need to select a target variable. The target variable is the variable whose values are to be modeled and predicted by your model using the other variables. It’s what you want to predict.
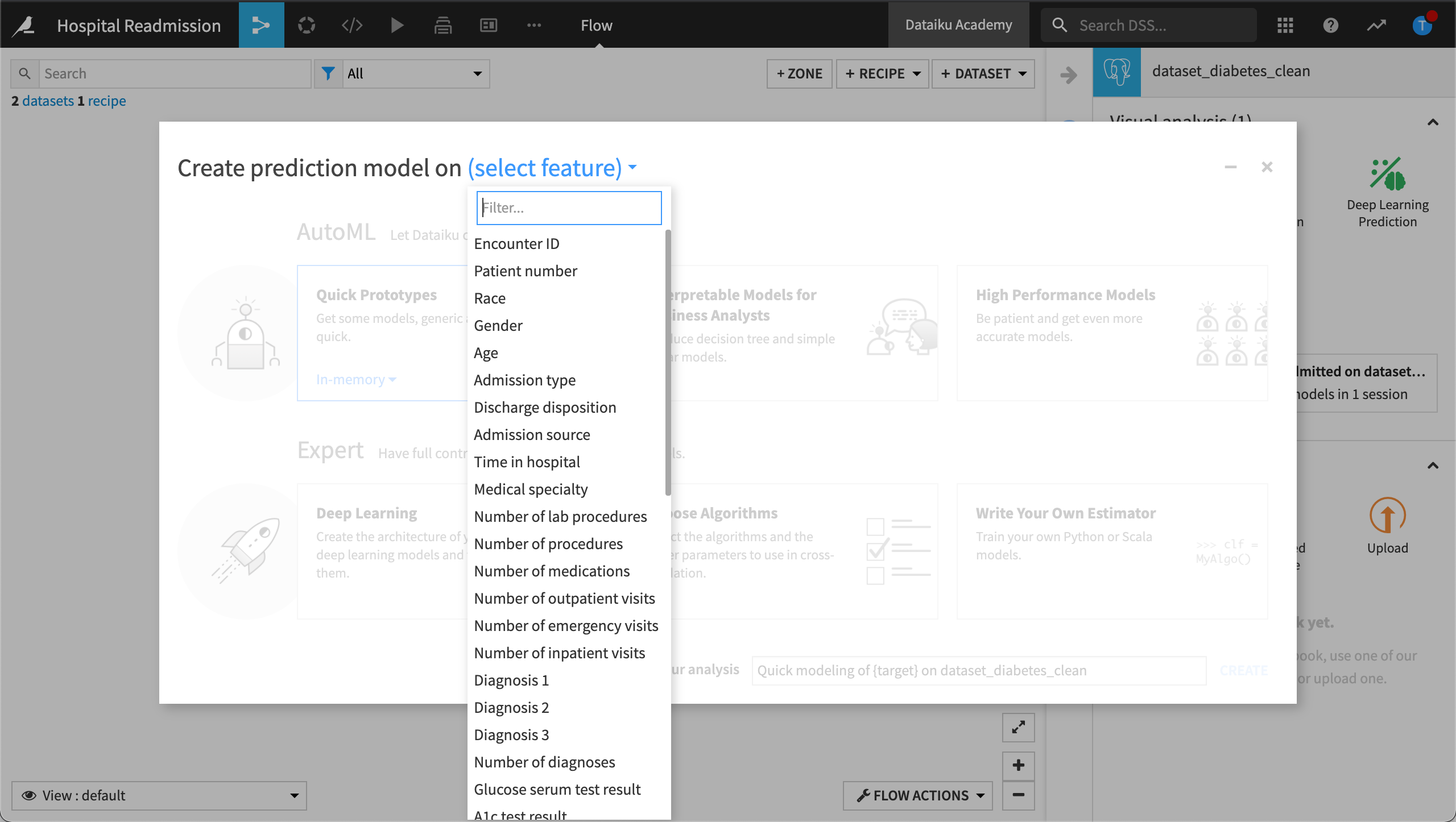
Once you’ve identified the target variable, you will be able to select between AutoML and Expert mode:
With AutoML, or Automated Machine Learning mode, Dataiku will make a lot of optimized choices for you.
With Expert mode, you can use deep learning models, have full control over the details of your model, or write your own algorithms.
For example, when building a prediction model, you can select an AutoML task, such as Quick Prototypes, to let Dataiku make smart modeling choices you like the train/test split or the preprocessing of features.
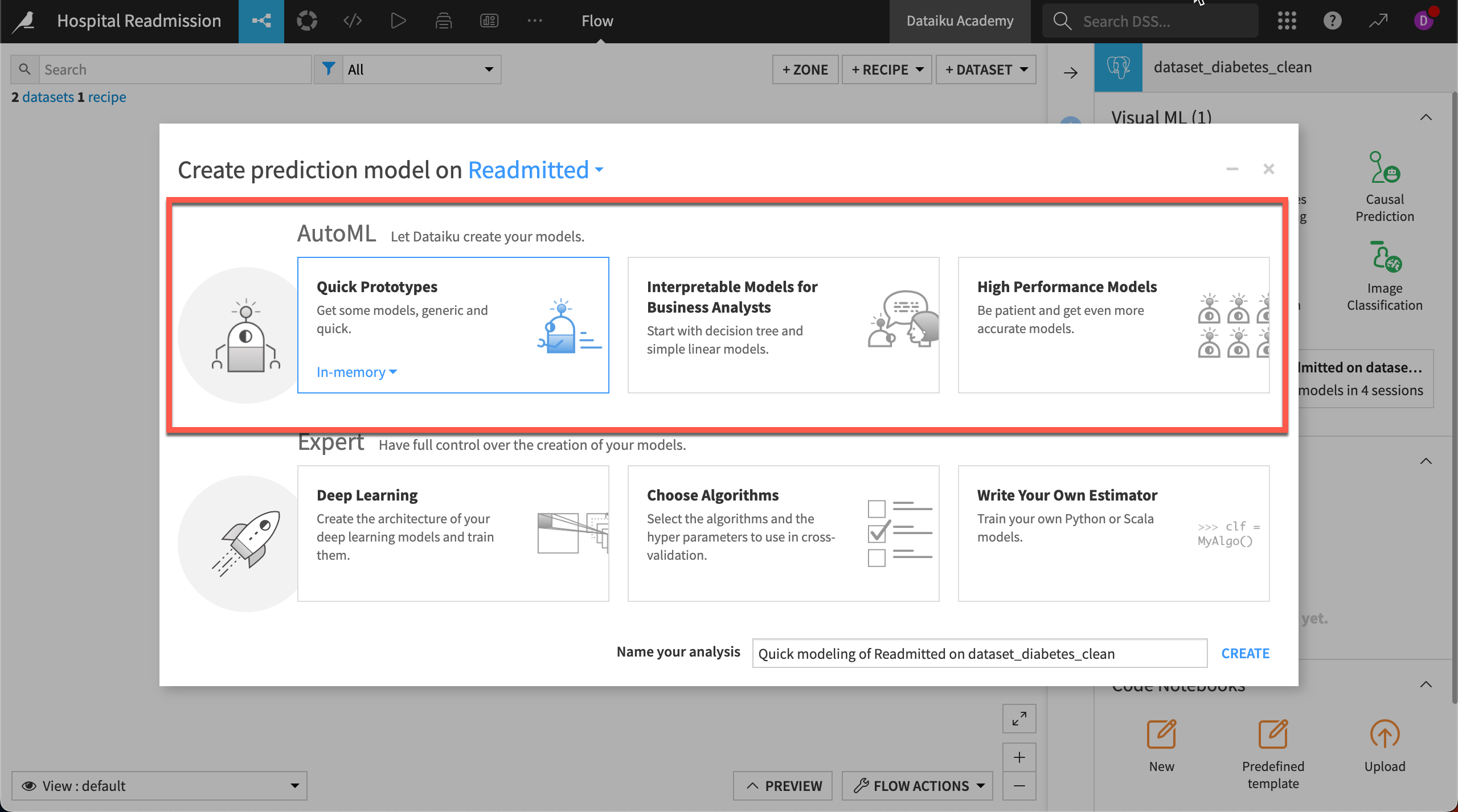
In the Automated Machine Learning mode, you’ll still be able to define the types of algorithms Dataiku will train. This will let you choose between fast prototypes, interpretable models, or high-performing models with less interpretability.
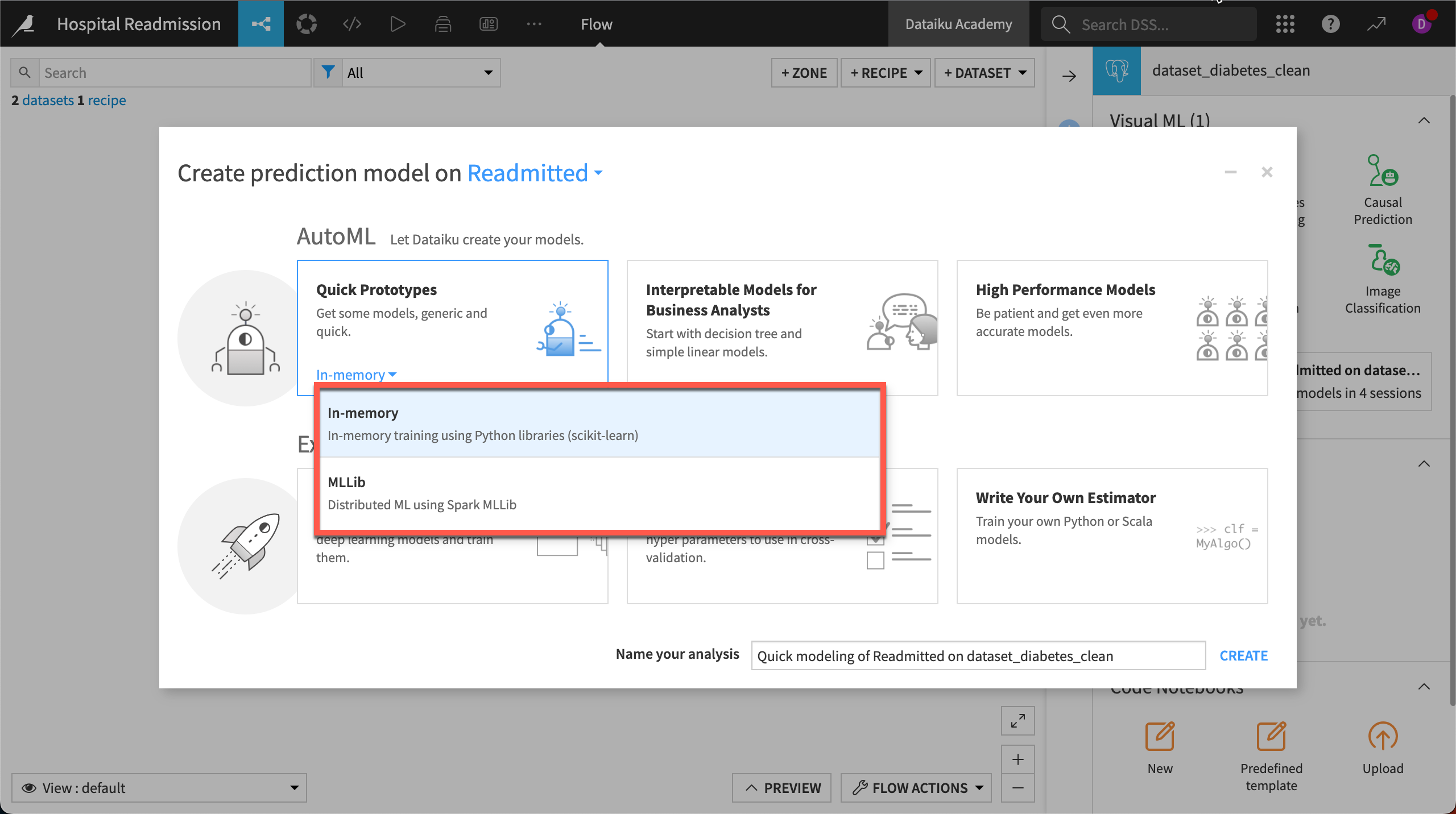
You can also define the computation engine used to train the models. You’ll be able to leverage your machine’s Python-based back-end or, depending on the integrations made at the admin level, offload training to your Spark cluster using SparkMLlib.
Once you’ve selected an option, you can launch your first training session and train a few models on your training dataset.
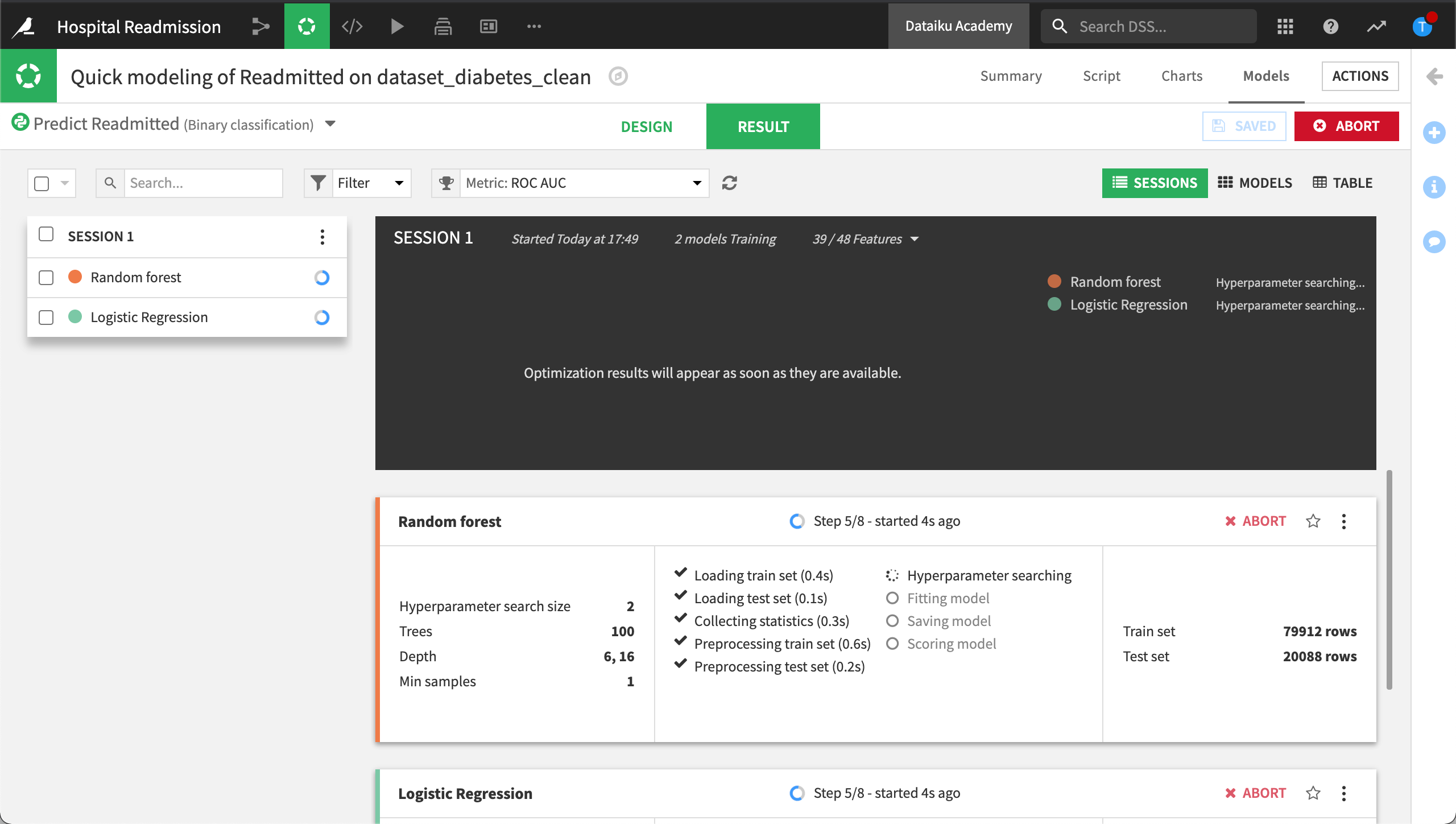
A session is one iteration of your experiment. It will include and save all the parameters, the dataset, features, and algorithms used during training, as well as relevant training information. You’ll be able to create many training sessions to experiment and try to improve your baseline model’s performance.
Note
It’s good practice to name the sessions with an explicit name to let you identify and explore them later.