
How-to | Enable SQL pipelines in the Flow#
An SQL recipe in your Flow reads an input dataset from storage, performs computations, and directs SQL to write the output. When you have a chain of visual and/or coding SQL recipes in your Flow, repeating this read-write behavior for each recipe can result in slow performance. In such a situation, using SQL pipelines can boost performance by avoiding unnecessary writes and reads of intermediate datasets.
Watch this short video below for an overview or read on for further details.
Enable SQL pipelines#
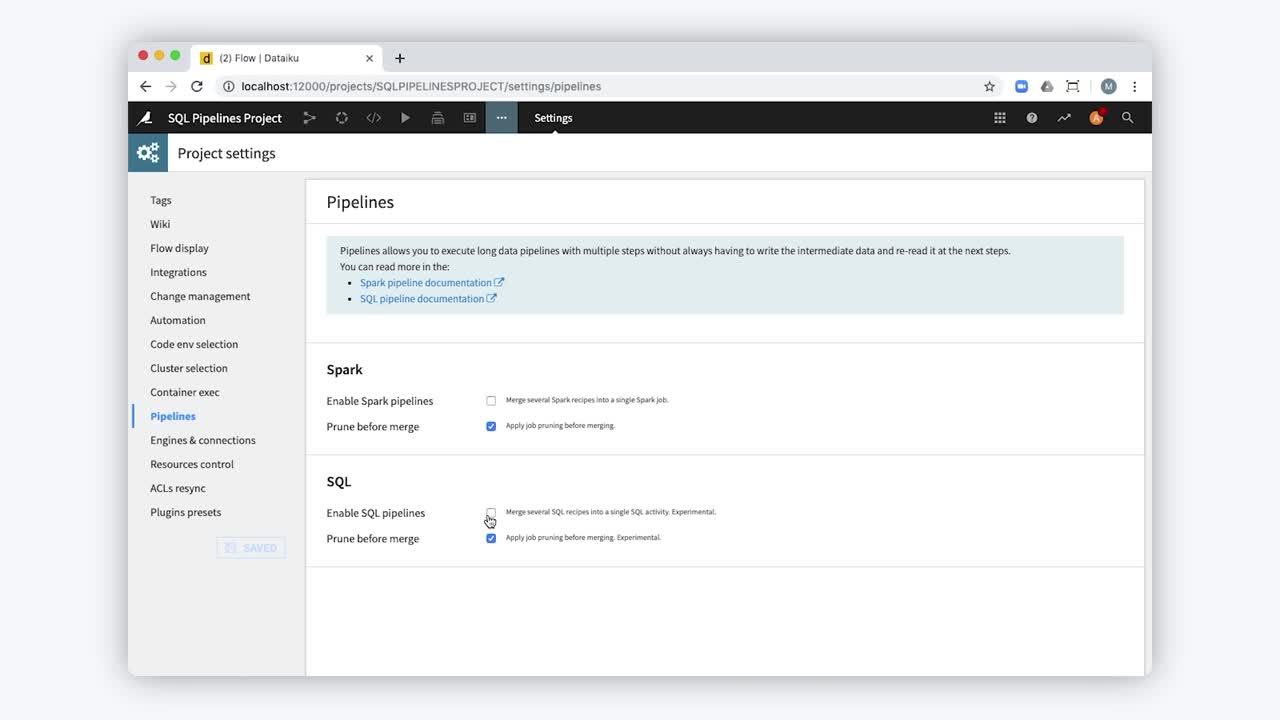
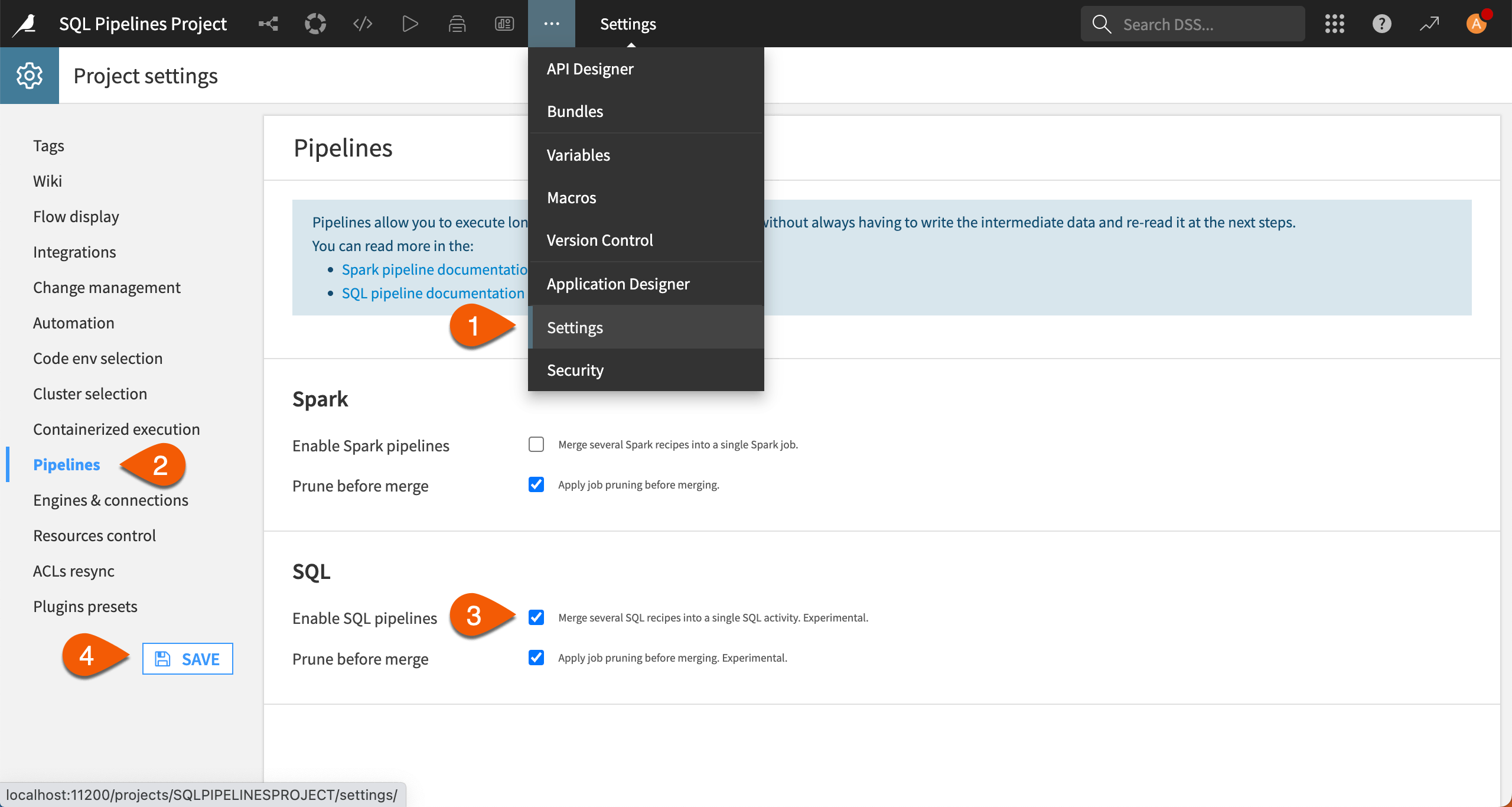
To use the SQL pipelines feature in a Dataiku Flow, the chain of recipes must share the same SQL connection. You can then enable SQL pipelines on a per-project basis.
Go to the project’s Settings.
Go to Pipelines.
Select Enable SQL pipelines.
Save settings.
Enable SQL pipelines feature for the project#
Once enabled, you can then configure the behavior of intermediate datasets and recipes in your Flow.
Configure the behavior of intermediate datasets#
For intermediate datasets in the Flow, you can choose to enable or disable virtualization. Enabling virtualization can prevent Dataiku from writing the data of an intermediate dataset when executing the SQL pipeline.
To enable virtualization for a dataset:
Open the dataset and go to the Settings tab at the top of the page.
Go to the Advanced tab.
Check Virtualizable in build.
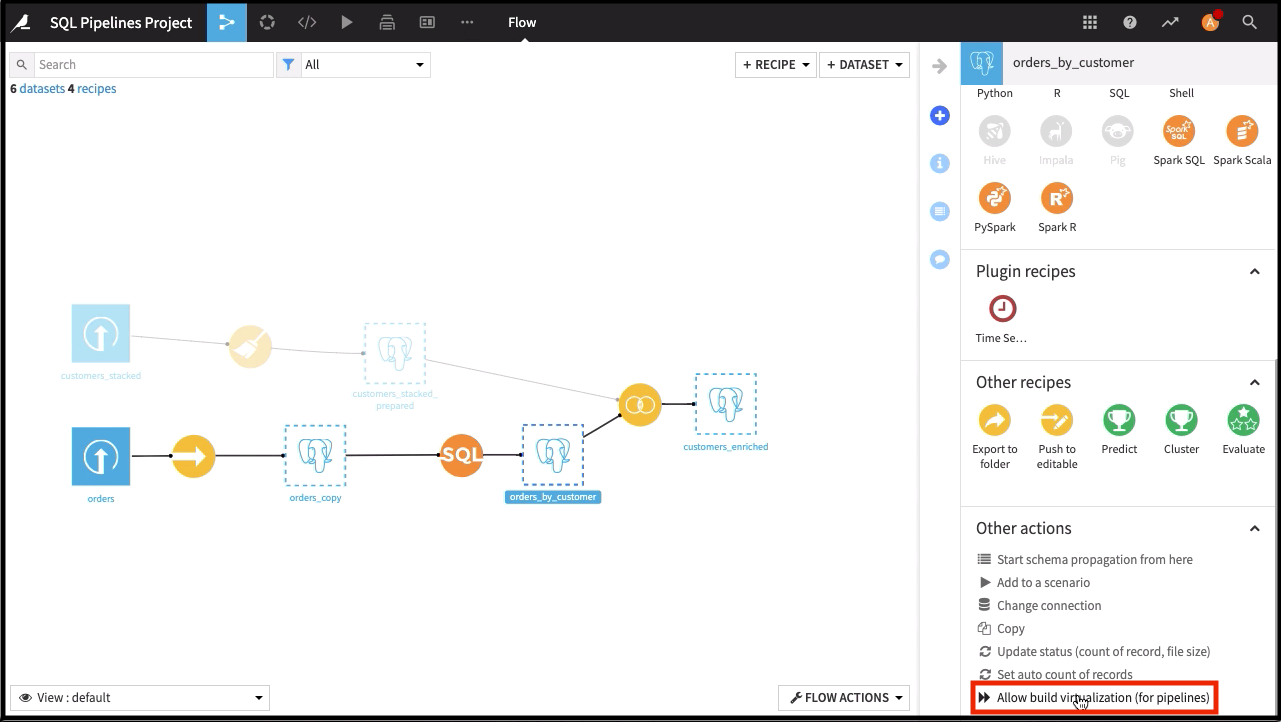
To enable virtualization for multiple datasets at once:
Select one or more datasets in the Flow.
Locate the Other actions section in the right panel and select Allow build virtualization (for pipelines).
Enable virtualization for datasets#
Configure the behavior of recipes#
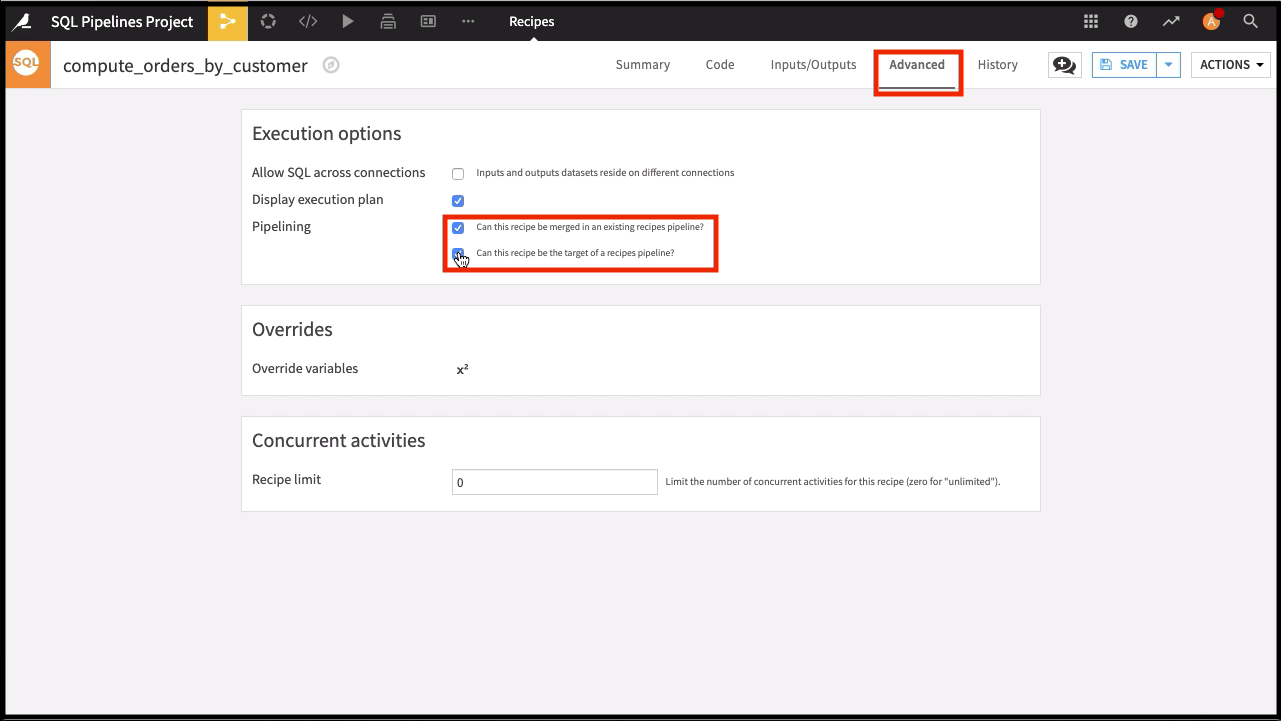
In addition to configuring the behavior of intermediate datasets, you can also specify how recipes in the Flow behave. To configure the behavior of the pipeline for each recipe:
Open the recipe, and go to the Advanced tab at the top of the page.
Check the options for Pipelining:
Can this recipe be merged in an existing recipe’s pipeline?
Can this recipe be the target of a recipe’s pipeline?
Configure recipe behavior#
The first setting determines whether a recipe can be concatenated inside an existing SQL pipeline. The second setting determines whether running the recipe can trigger a new SQL pipeline.
Next steps#
The reference documentation provides more details about SQL pipelines in Dataiku.