
Concept | Responsible AI in the data science practice#
Taking into account its potential pitfalls, how can we create and use AI responsibly? Let’s take a moment and think about the AI pipeline.
The AI lifecycle#
Below is a simplified diagram showcasing the various stages in the pipeline — from defining a problem, to designing a solution, to building, deploying, and monitoring the solution.
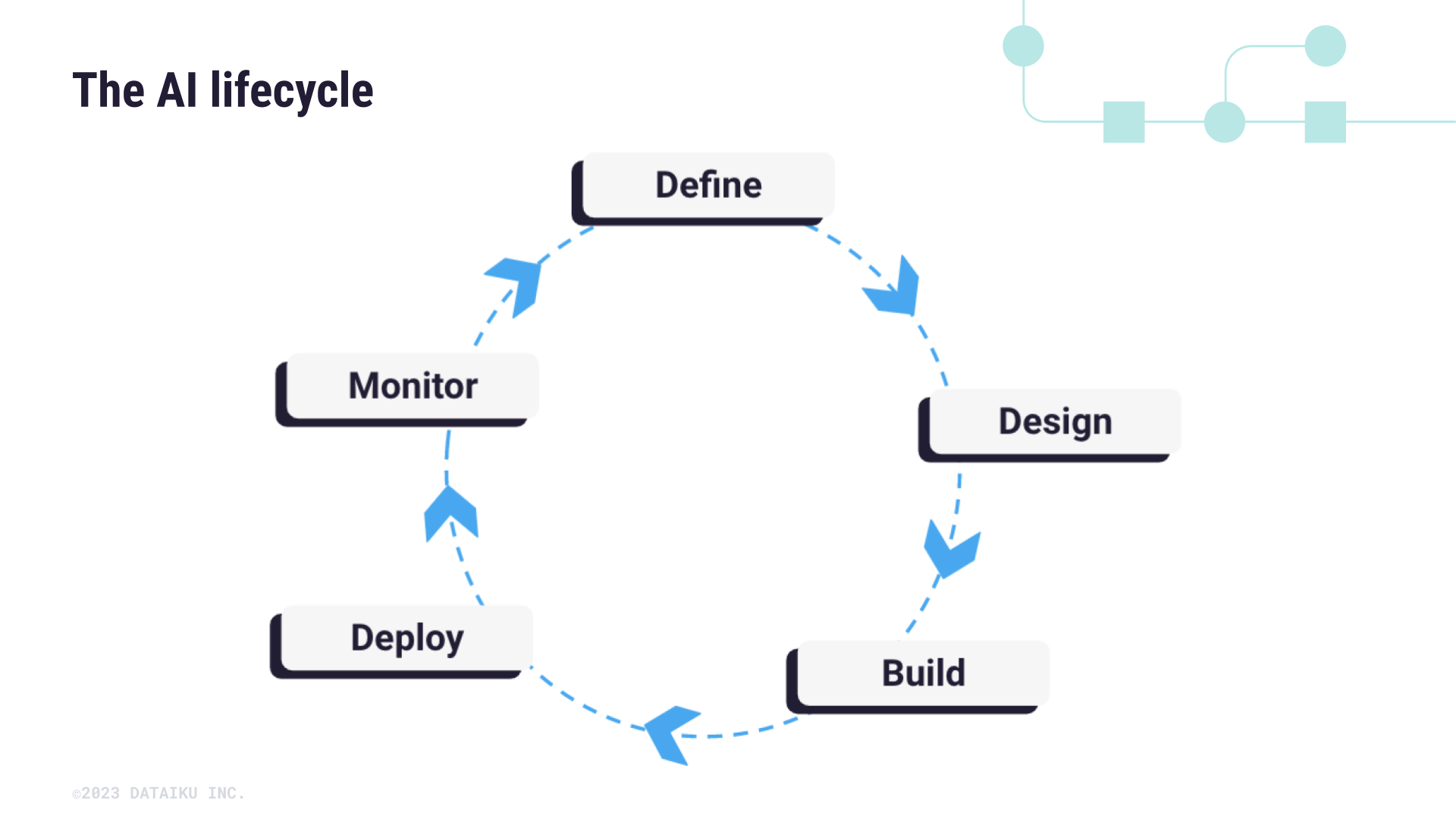
When it comes to putting Responsible AI into practice, we will focus on the build and experiment aspects of the AI lifecycle. This part of the AI lifecycle covers traditional data science practices, from data exploration to model testing and reporting. Each of these stages will have common pain points that can create unintended negative consequences.
Responsible AI in the data pipeline#
There are a number of key principles we can use to assess our AI for overall fairness, quality, and trust during the build and experimentation phase of development.
These principles are presented at a high level for now. Continue with Responsible AI concepts and tutorials in the Dataiku Knowledge Base for a practical guide on how to execute these ideas.
The tutorials will follow a project’s data pipeline and guide you through identifying data biases, assessing model fairness and interpretability, and model explainability and reporting.
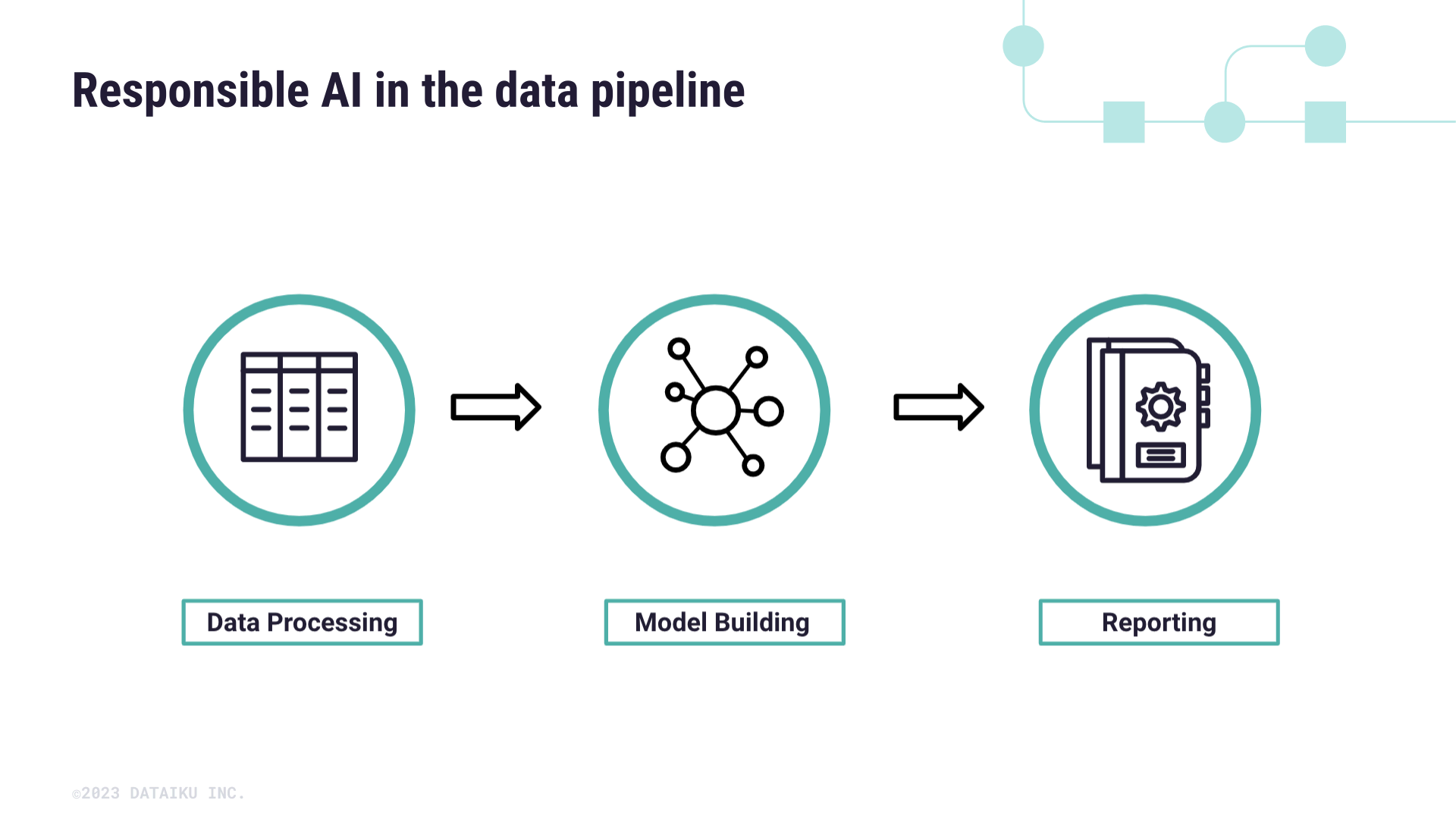
Data processing#
Let’s start with the question of data. We know all data are the product of the historical context they were built in and that they can reflect harmful biases. This can occur in a number of ways, including using imbalanced datasets that are built with bad collection practices.
Moreover, turning human perceptions and beliefs into data points can reinforce social biases. And finally, there is always the danger of proxy variables which are features that may seem unbiased, such as education level, but are actually highly correlated with a sensitive attribute like race or ethnicity.

Model building#
Now, assuming we’ve accounted for the biased data in our pipeline, we can move to the model building stage.
Here, model fairness plays a big role, but what does it mean to have a fair model? From a mathematical standpoint, fairness requires that predictions are independent from sensitive attributes. This means that if we changed an input variable like sex or race, there would be no statistically significant difference in the model prediction.
However, there are also a number of ways to think about fairness according to social context.
First is the idea of group fairness. This denotes that a model’s performance is uniform across all sub-populations of interest. An alternative would be to look at individual fairness, for which individuals with similar profiles should have equal treatment probabilities. From our health care example, this would mean Black and white patients with the same health risks would receive extra care at the same rate.
Another way to think about model fairness is through counterfactuals, meaning if we changed only the sensitive attribute for an individual, their prediction shouldn’t change. This is a form of What if analysis and can be used as a baseline check before exploring other types of fairness.

Reporting#
We come now to the final part of the ML pipeline: reporting. As data practitioners, our work doesn’t live in isolation, and how we share our findings and models is equally important as building them. Additionally, reporting can combat the instinct to trust AI systems without understanding the full context and inputs into the model.
However, there are some known challenges to reporting. For instance, black box models provide little insight into the data and methods used. Knowing that traditional AI systems can be difficult to audit and trace — especially when dealing with hundreds of lines of code and many people making decisions without documenting why — we must modify our data science practice to make reporting more achievable.
