
Concept | LLM guardrails#
When using large language models to benefit from the power of Generative AI, it’s crucial to understand the potential risks and implement robust guardrails to ensure these technologies are used safely, reliably, and ethically.
LLMs, as probabilistic models, can inadvertently generate outputs that may pose risks to both organizations and individuals. These risks include:
The potential exposure of sensitive or confidential information, particularly with Retrieval-Augmented Generation (RAG) as you provide your own knowledge to the LLM to enrich it in order to offer contextually relevant answers.
The generation of incorrect information that may sound plausible (often referred to as hallucinations).
The generation of inappropriate or offensive responses.
Connection-level guardrails#
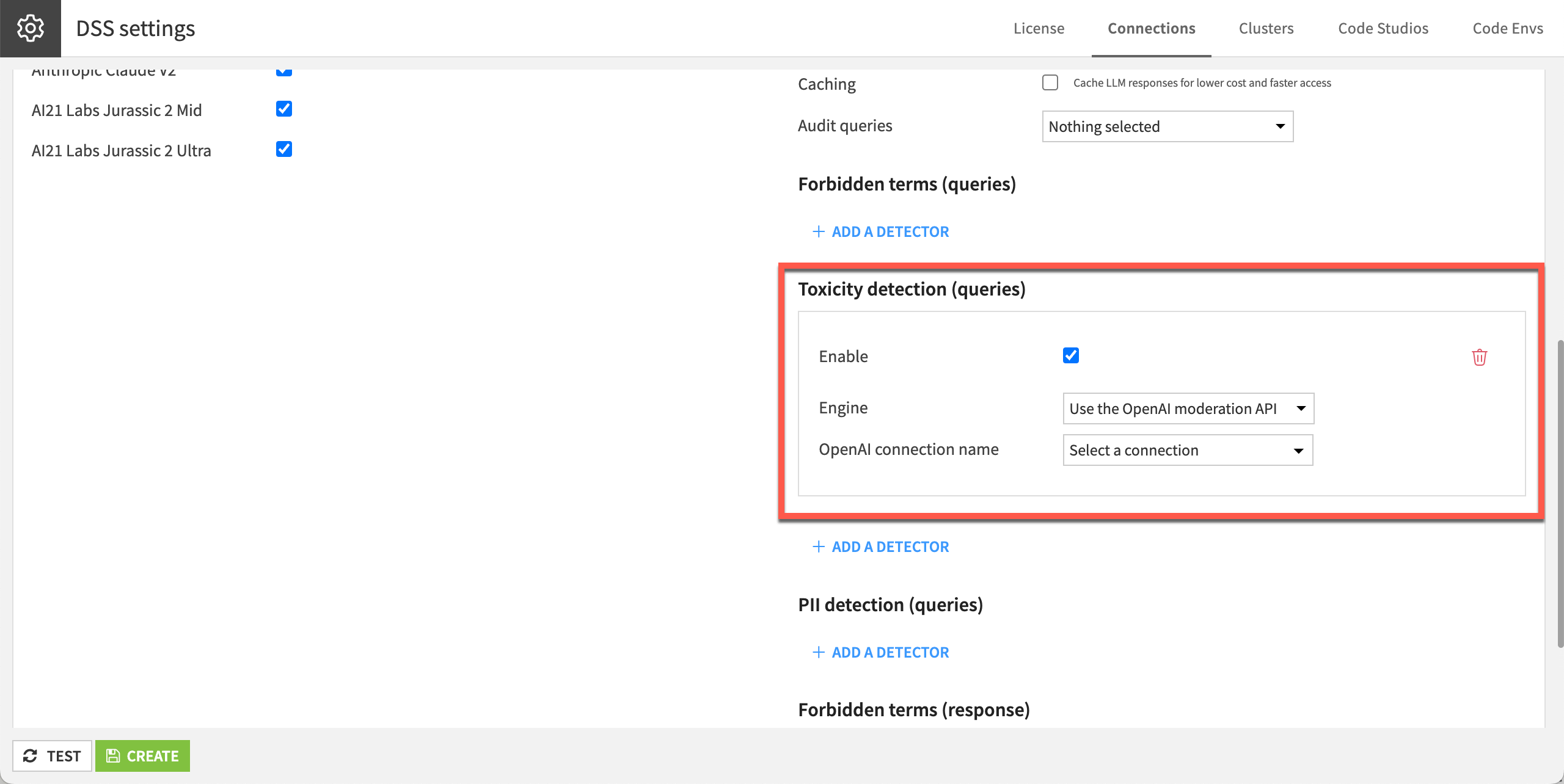
In Dataiku, the LLM Mesh provides five main filters to moderate the content and detect potentially risky responses.
Guardrail |
Description |
|---|---|
Toxicity Detector |
Ensures that the model’s input or output doesn’t contain inappropriate or offensive content, and defines appropriate remedies if they do. |
Forbidden Terms Detector |
Filters out provided terms from both queries and responses, ensuring that sensitive or prohibited content is excluded. |
PII (Personally Identifiable Information) Detector |
Filters every query for PII and defines an action to take, such as rejecting the query or replacing the PII with a placeholder. Leverages the presidio library. |
Prompt Injection Detector |
Blocks prompt injections, which are attempts to override the intended behavior of an LLM. |
Response Format Checker |
Checks whether the LLM’s responses are in a specified format, such as JSON array or JSON object. |
Administrators can configure guardrails in the settings for each LLM connection. This sets up guardrails at the instance level.
Object-level guardrails#
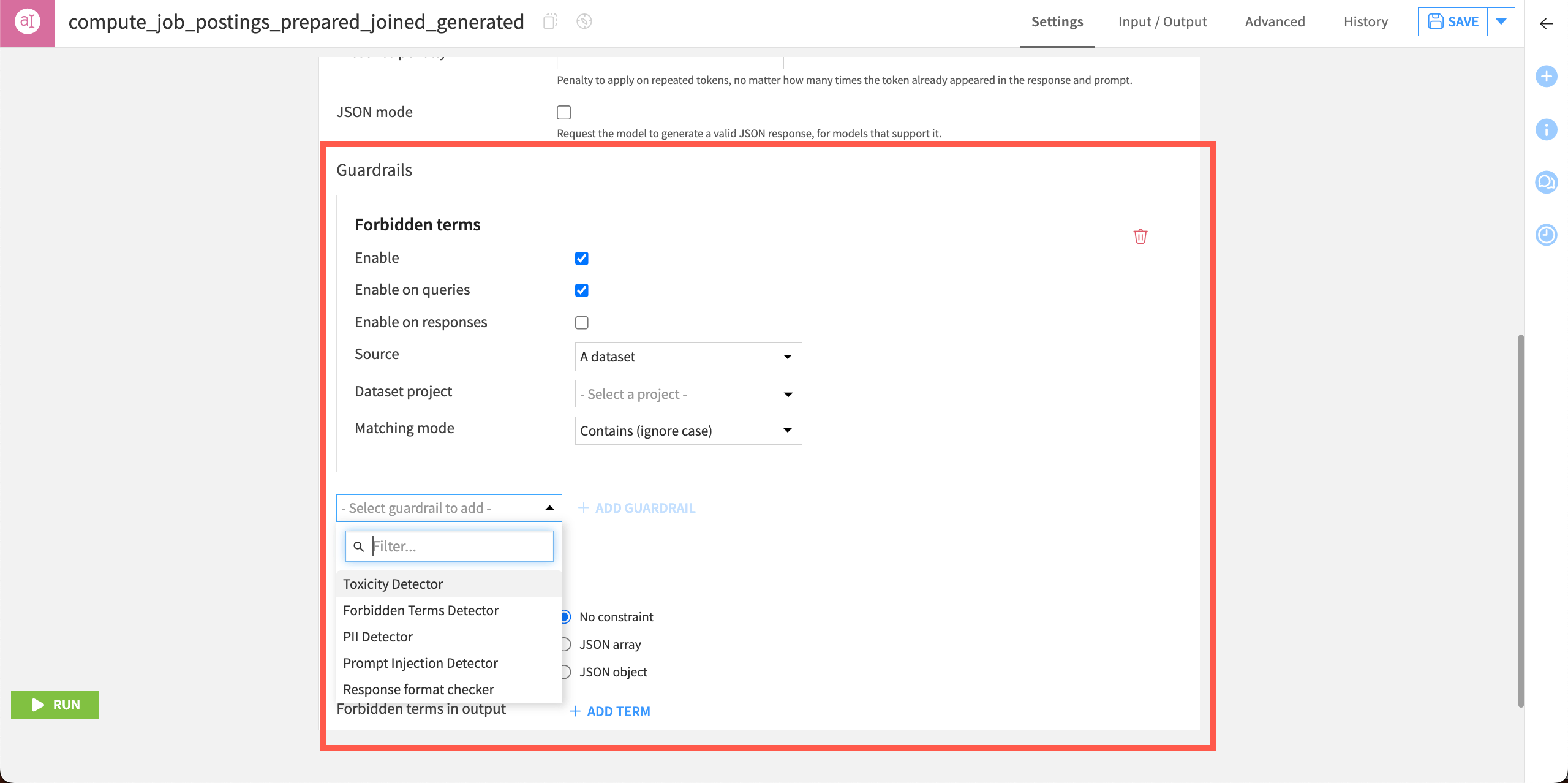
Users can also configure guardrails in the settings of some visual LLM recipes, such as the Prompt recipe, or in agents.
This adds guardrails only within queries associated with that recipe or agent.
RAG guardrails#
Users also can set guardrails on Retrieval-Augmented Generation (RAG) use cases to ensure that the selected context and answer make sense given the question and knowledge bank.
Important
This feature requires the Advanced LLM Mesh add-on.
Guardrail |
Description |
|---|---|
Relevancy |
How much the response addresses the user query. |
Faithfulness |
How consistent the response is with the retrieved excerpt. |
Custom guardrails#
Users can add custom guardrails by developing plugins.
Custom guardrails could, for example, rewrite responses from an LLM or add information to an audit log.
See also
For more details about guardrails and instructions to set them up, see the reference documentation.