
Concept | Monitoring model performance and drift in production#
Watch the video or read the summary below.

When you deploy a machine learning model in production, it can start degrading in quality fast and without warning. Therefore, you need to monitor models in production in a way that alerts you to potential problems and lets you reassure stakeholders that your AI project is under control.
For example, let’s say you have a credit card fraud analysis project where you’ve designed a model to predict fraud and deployed it into production.
Initially, the model’s performance satisfied you. Later on, you noticed drops in the active model’s performance metrics like AUC, precision, and recall. However, monitoring models in production should include more than reviewing a metrics dashboard.
Ideally, you want to monitor models in a way that gives control over your AI projects and lets you deploy new model versions with confidence. Therefore, you want to answer the following questions:
Does new incoming data reflect the same patterns as the data on which the model was originally trained?
Is the model performing as well as during the design phase?
If not, why?

Tracking model degradation#
How well a model performs is a reflection of the data used to train it. A significant change in the distribution or composition of values for input variables or the target variable could lead to data drift. The drift could cause the model to degrade. Model degradation can lead to inaccurate predictions and insights.
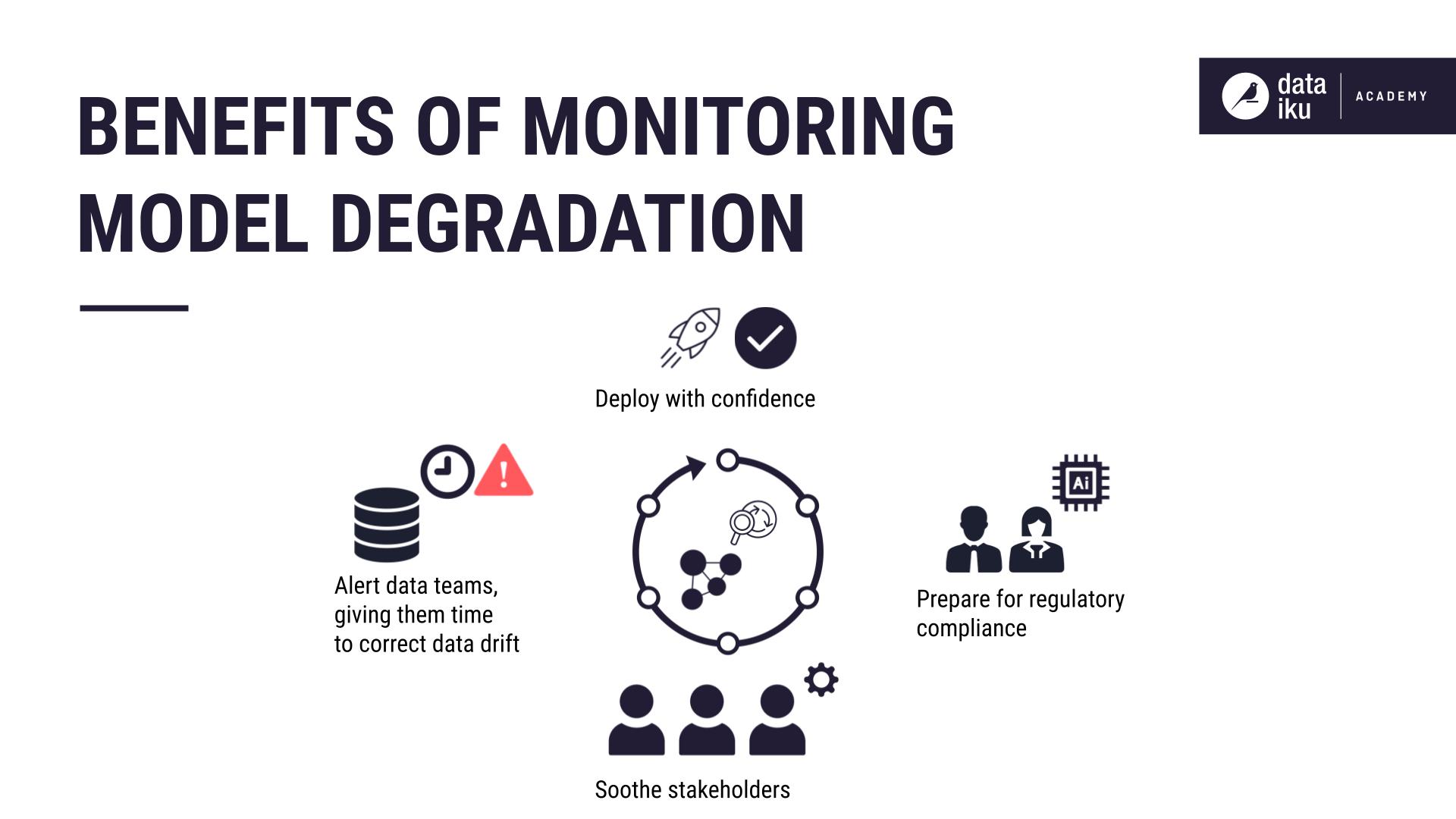
Monitoring model degradation has the following benefits:
Alert data teams before model performance drops significantly (giving them time to correct data drift).
Deploy AI projects with confidence.
Prepare for compliance in regulatory frameworks around AI.
Show stakeholders that the AI project remains under control.
Two approaches to model monitoring#
To track model degradation, there are two approaches to consider: one based on ground truth and the other on input drift.

Ground truth monitoring#
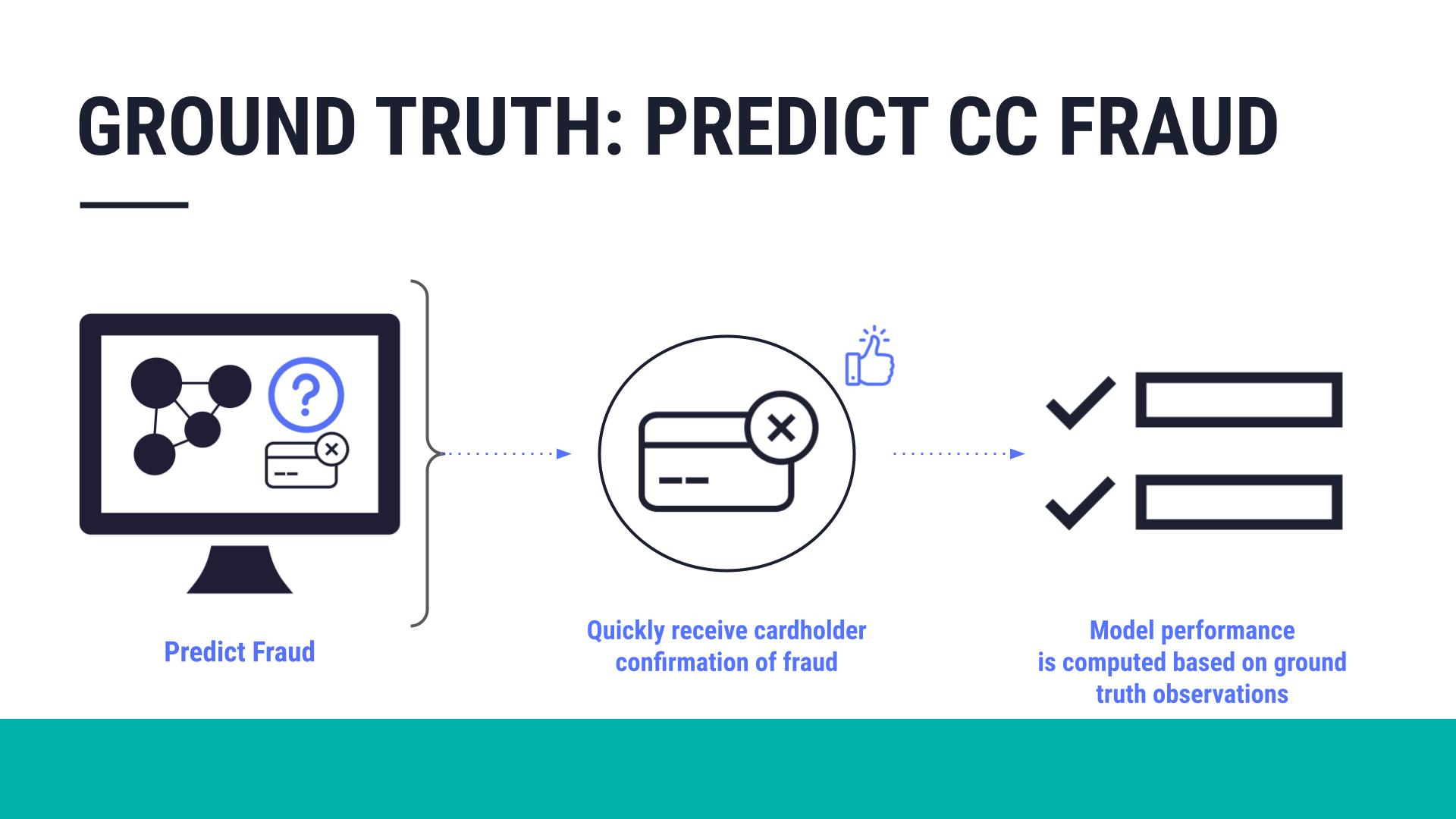
The ground truth is the correct answer to the question that the model was asked to solve. For example, in the case of predicting credit card fraud, the ground truth is the correct answer to the question, “Was this transaction actually fraudulent?” When you know the ground truth for all predictions a model has made, you can judge with certainty how well the model is performing.
Ground truth monitoring requires waiting for the label event, such as whether a specific transaction was actually fraudulent. Based on the label event observations, you can compute the performance of the model.
When it’s available, the ground truth is the best answer to monitor model degradation.
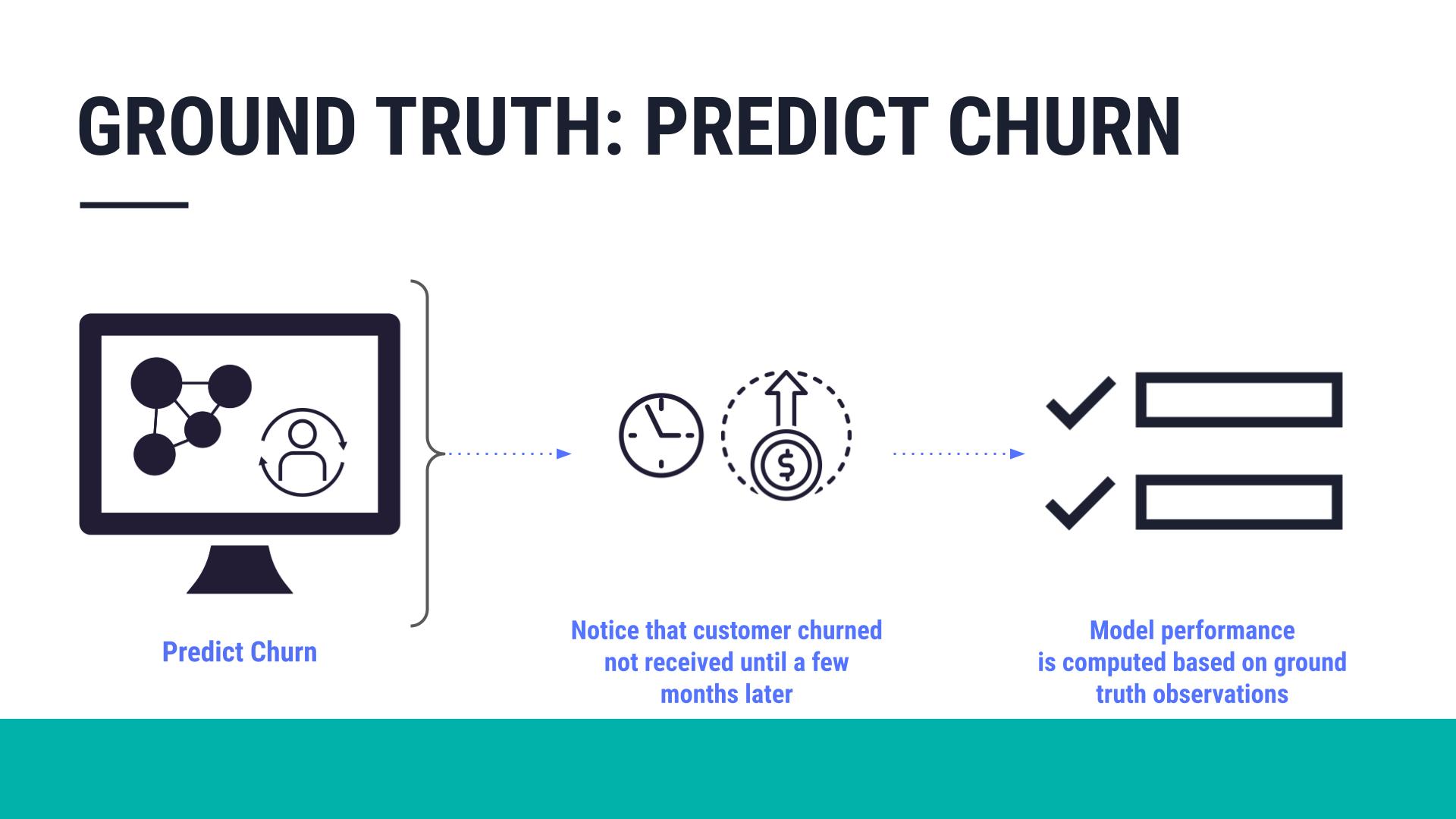
However, obtaining the ground truth can be slow and costly. For example, take the case of predicting customer churn. You may not know the ground truth — whether the customer actually churned or not — until a few months after the model scored the record.
Input drift monitoring#
Input drift monitoring can also be a valuable warning sign — particularly for use cases requiring rapid feedback or if the ground truth isn’t available.
The basis for input drift is that a model will only predict accurately if its training data is an accurate reflection of the real world. If a comparison of recent requests to a deployed model against the training data shows distinct differences, then there is a strong chance that the model performance may be compromised.
Unlike with ground truth evaluation, the data required for input drift evaluation already exists. There is no need to wait for any other information.
In summary, ground truth is the cornerstone, but input drift monitoring can provide early warning signs.
Works Cited
Mark Treveil and the Dataiku team. Introducing MLOps: How to Scale Machine Learning in the Enterprise. O’Reilly, 2020.
Next steps#
You’ll have a chance to implement strategies for both ground truth and input drift monitoring in Tutorial | Model monitoring with a model evaluation store.