
Prepare the usage dataset#
The usage dataset tracks the mileage for cars, identified by their Asset ID, at a given point in Time.
The Use variable records the total number of miles a car has driven at the specified Time.
The units of the Time variable aren’t clear. Perhaps days from a particular date? You could start a discussion with the data’s owner to find out.
Here Asset ID isn’t unique, that is, the same car might have more than a single row of data.
After importing the CSV file, from the Explore tab, we can see that the columns are stored as “string” type (the gray text beneath the column header), even though Dataiku can infer from the sample the meanings to be Text, Integer, and Decimal (the blue text beneath the storage type).
Note
For more on the distinction between storage types and meanings, please see the reference documentation or the concept lessons on schema, storage type and meanings.
Accordingly, with data stored as strings, we won’t be able to perform any mathematical operations on seemingly numeric columns, such as Use. Let’s fix this.
Navigate to the Settings > Schema tab, which shows the storage types and meanings for all columns.
Click Check Now to determine that the schema and data are consistent.
Then click Infer Types from Data to allow Dataiku to assign new storage types and high-level classifications.
Save the changes.
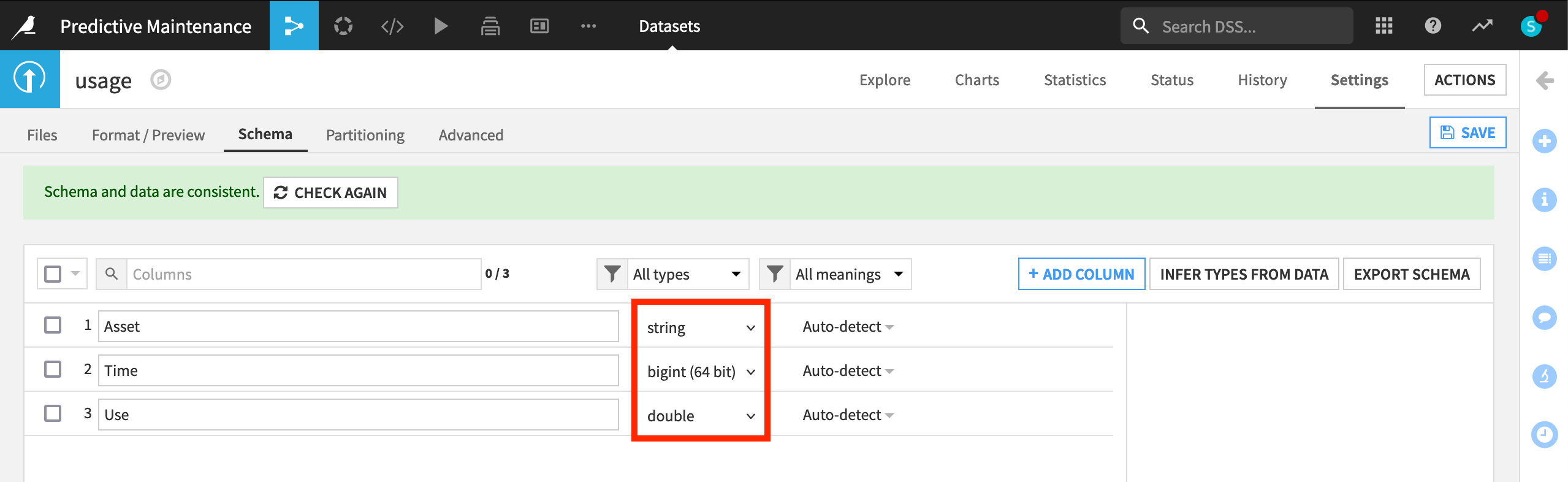
Returning to the Explore tab, note that although the meanings (written in blue) haven’t changed, the storage types in gray have updated to “string”, “bigint”, and “double”.
Note
As noted in the UI, this action only takes into account the current sample, and so should be used cautiously. There are a number of different ways to perform type inference in Dataiku, each with their own pros and cons, depending on your objectives. Initiating a Prepare recipe, for example, is another way to instruct Dataiku to perform type inference. For more information, see the reference documentation on creating schemas of datasets.
For most individual cars, we have many Use readings at many different times. However, we want the data to reflect the individual car so that we can model outcomes at the vehicle-level. Now with the correct storage types in place, we can process the dataset with a Group By recipe.
From the usage dataset, initiate a Group By recipe from the Actions menu.
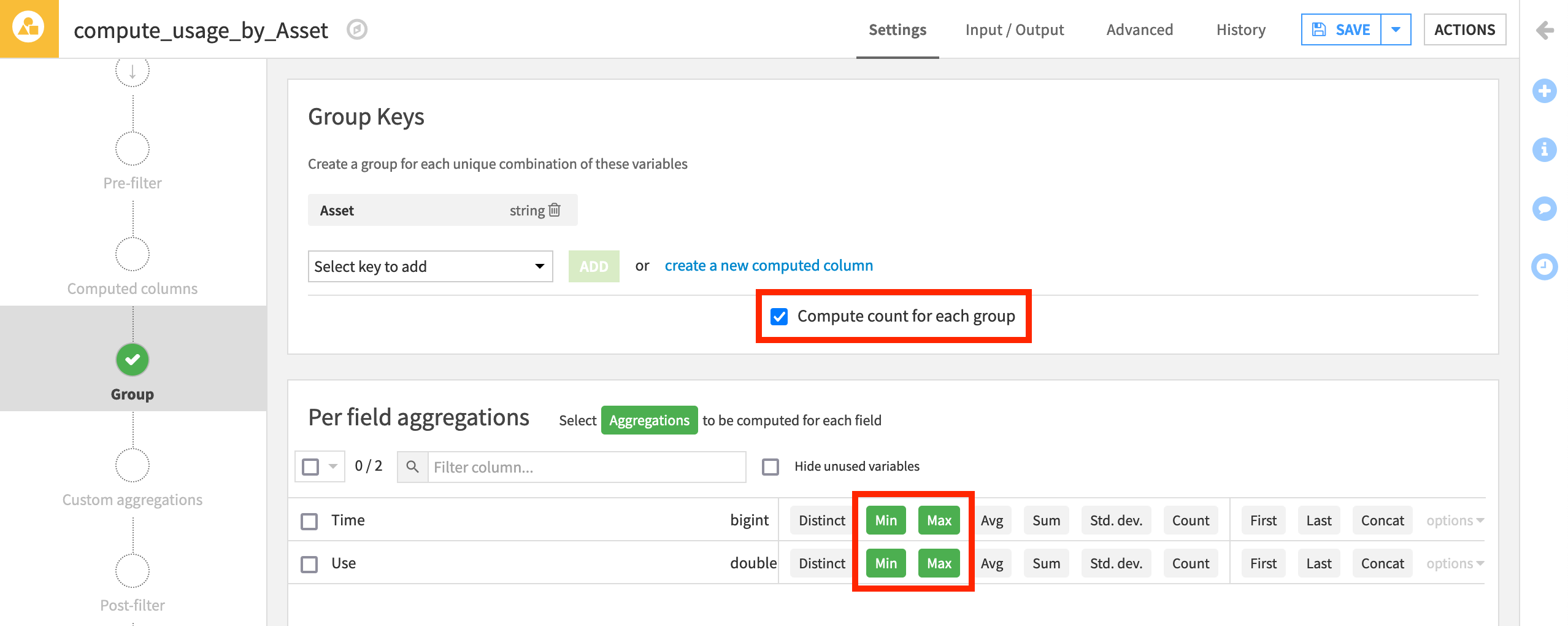
Choose to Group By Asset in the dropdown menu.
Keep the default output dataset name
usage_by_Asset.In the Group step, we want the count for each group (selected by default).
Add to this the Min and Max for both Time and Use.
Run the recipe.
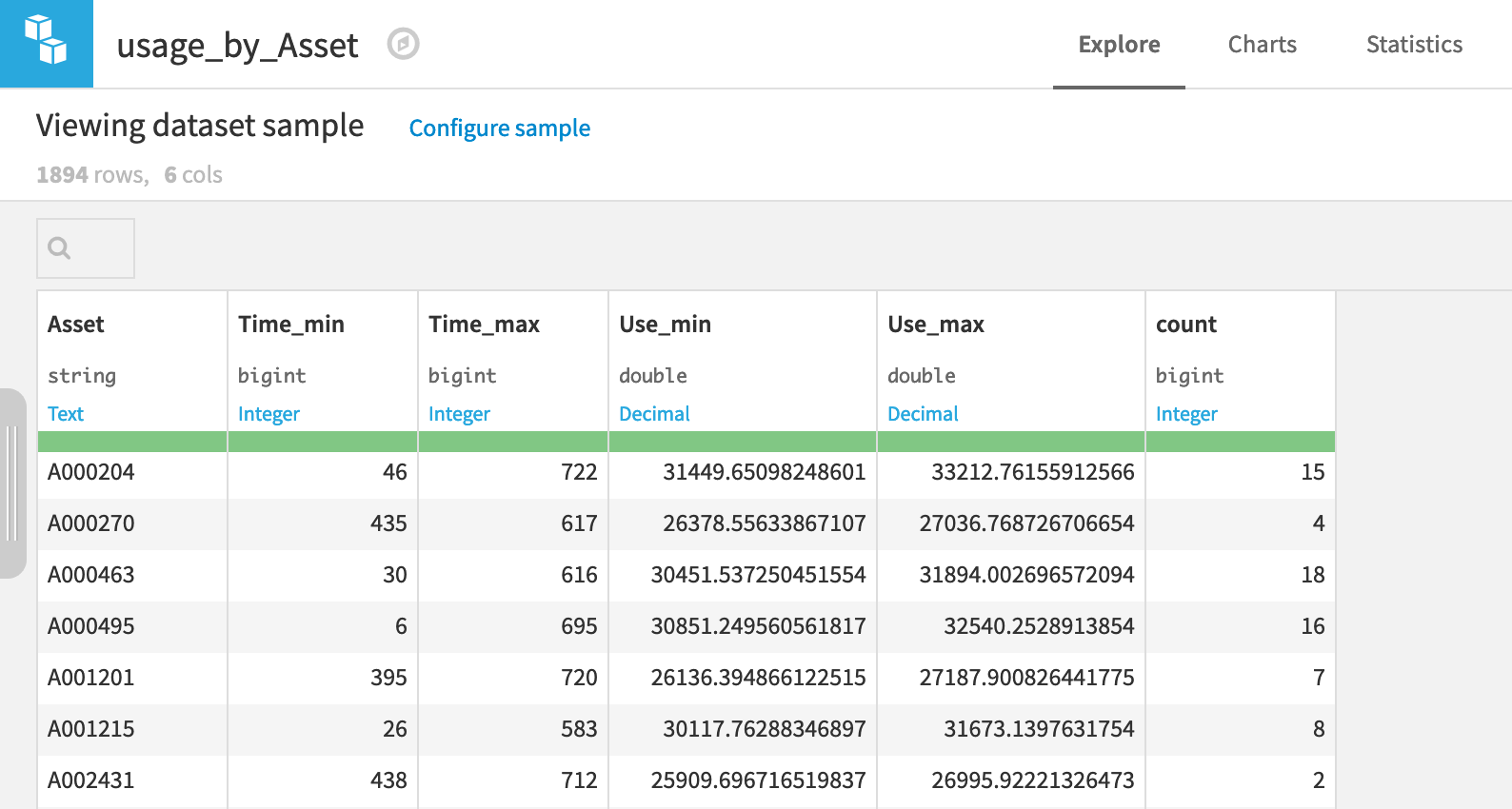
Now aggregated at the level of a unique car, the output dataset is fit for our purposes.
Let’s see if the maintenance dataset can be brought to the same level.