
Understand the project#
See a screencast covering this section’s steps.

Before rushing to deployment, take a moment to understand the goals for this quick start and the data at hand.
Objectives#
In this quick start, you’ll:
Create an API endpoint from a prediction model.
Deploy a version of the API endpoint to a production environment.
Automate the building of a data pipeline.
Tip
To check your work, you can review a completed version of this entire project from data preparation through MLOps on the Dataiku gallery.
Review the Flow#
One of the first concepts a user needs to understand about Dataiku is the Flow. The Flow is the visual representation of how datasets, recipes (steps for data transformation), models, and agents work together to move data through an analytics pipeline.
Dataiku has its own visual grammar to organize AI and analytics projects in a collaborative way.
Shape |
Item |
Icon |
|---|---|---|

|
Dataset |
The icon on the square represents the dataset’s storage location, such as Amazon S3, Snowflake, PostgreSQL, etc. |

|
Recipe |
The icon on the circle represents the type of data transformation, such as a broom for a Prepare recipe or coiled snakes for a Python recipe. |

|
Model or Agent |
The icon on a diamond represents the type of modeling task (such as prediction, clustering, time series forecasting, etc.) or the type of agent (such as visual or code). |
Tip
In addition to shape, color has meaning too.
Datasets and folders are blue. Those shared from other projects are black.
Visual recipes are yellow.
Code elements are orange.
Machine learning elements are green.
Generative AI and agent elements are pink.
Plugins are often red.
This project begins in the Data Preparation Flow zone from a labeled dataset named job_postings composed of 95% real and 5% fake job postings. The pipeline builds a prediction model capable of classifying a job posting as real or fake. Your job will be to deploy the model found in the Machine Learning Flow zone as a real-time API endpoint.
Take a look now!
If not already there, from the (
 ) menu in the top navigation bar, select the Flow (or use the keyboard shortcut
) menu in the top navigation bar, select the Flow (or use the keyboard shortcut g+f).Starting from job_postings at the far left, review the objects in the Flow. Gain a high-level understanding of how the recipes first prepare, join, and split the data, then train a model, and finally use it score new data.
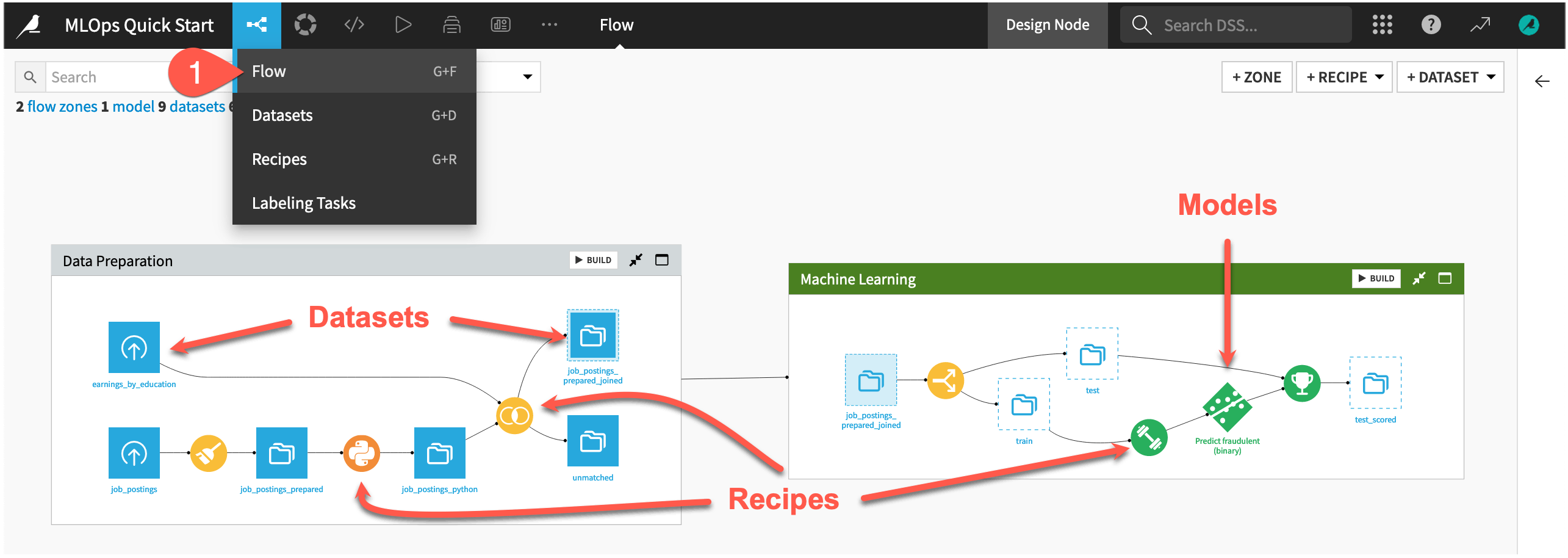
Tip
There are many other keyboard shortcuts! Type ? to pull up a menu or see the Accessibility page in the reference documentation.
Build the Flow#
Unlike the initial uploaded datasets, the downstream datasets appear as outlines. This is because you haven’t built them yet. However, this isn’t a problem because the Flow contains the recipes required to create these outputs at any time.
Open the Flow Actions menu.
Click Build all.
Leaving the default options, click Build to run the recipes necessary to create the items furthest downstream.
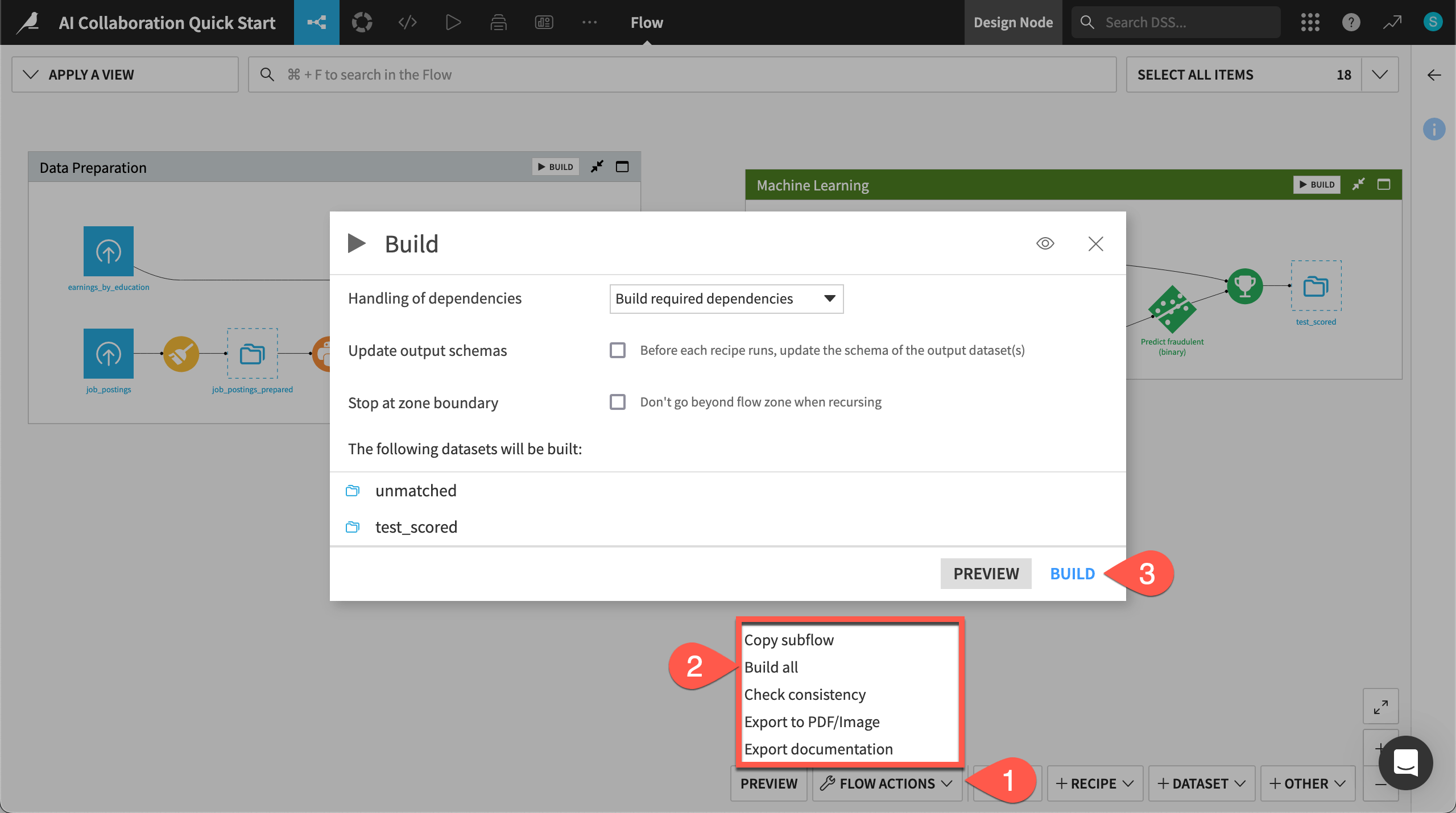
When the job completes, refresh the page to see the built Flow.
Inspect the saved model#
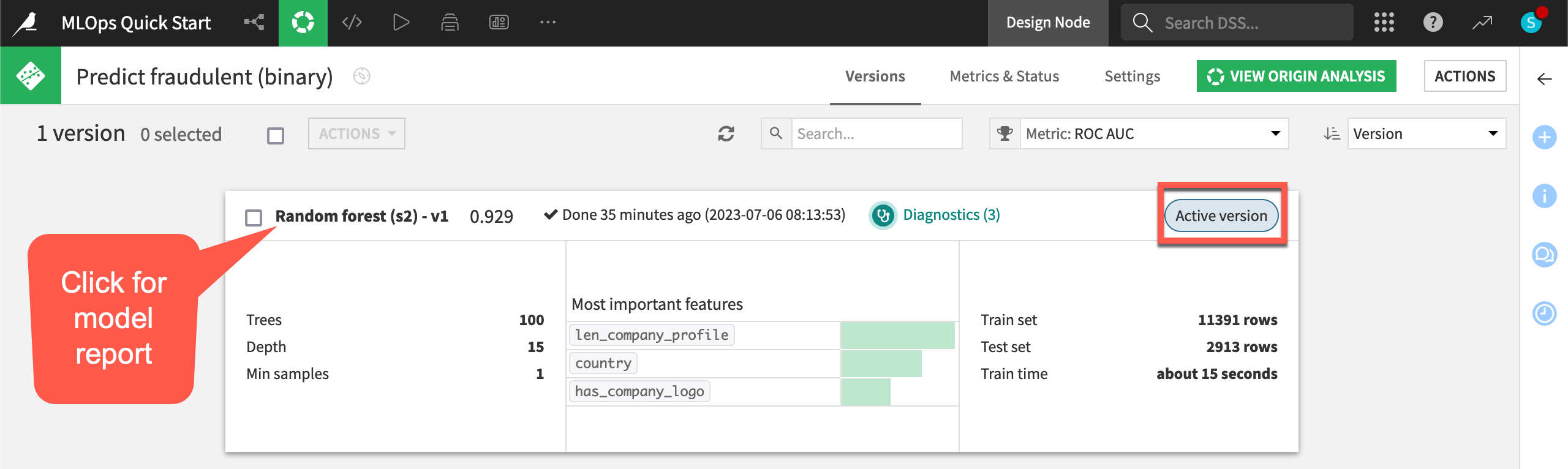
Take a closer look at the model found in the Flow.
In the Machine Learning Flow zone, double click to open the Predict fraudulent (binary) model (
 ).
).Note that the model has only one version, and so this version is also the active version. As you retrain the model and deploy new versions, the model object tracks the history of its versions — making it possible to roll back between versions.
Click the model version name Random forest (s2) - v1 to see the full report, including visualizations of its explainability and performance.
Return to the Flow (
g+f) when finished inspecting the model.
Tip
In this case, the project’s builder used Dataiku’s visual AutoML to create the saved model in the Flow. However, it’s also possible to import models packaged with MLflow as saved models into Dataiku. See the reference documentation on MLflow Models to learn more.
See also
To learn more about creating this model, see the Machine Learning Quick Start.