
Automate the Flow#
Once you’ve mastered the basics, you can begin automating your MLOps processes with Dataiku’s system of scenarios. A scenario in Dataiku is a set of actions to run, along with conditions for when they should execute and who should receive a notification of the results.
Start small by designing a scenario that rebuilds the furthest downstream dataset only if an upstream dataset satisfies certain conditions. You’ll later see how to use the same tools for retraining models or deploying new versions of API services.
See also
These automation tools can be implemented visually, with code, or a mixture of both. To get started using code in your MLOps workflows, see MLOps lifecycle in the Developer Guide.
View the existing scenario#
This project already has a basic one step scenario for rebuilding the data pipeline.
Navigate back to the Design node project.
From the Jobs (
 ) menu in the top navigation bar, open the Scenarios page.
) menu in the top navigation bar, open the Scenarios page.Click to open the Score Data scenario.
On the Settings tab, note that the scenario already has a weekly trigger, but doesn’t yet have a reporter.
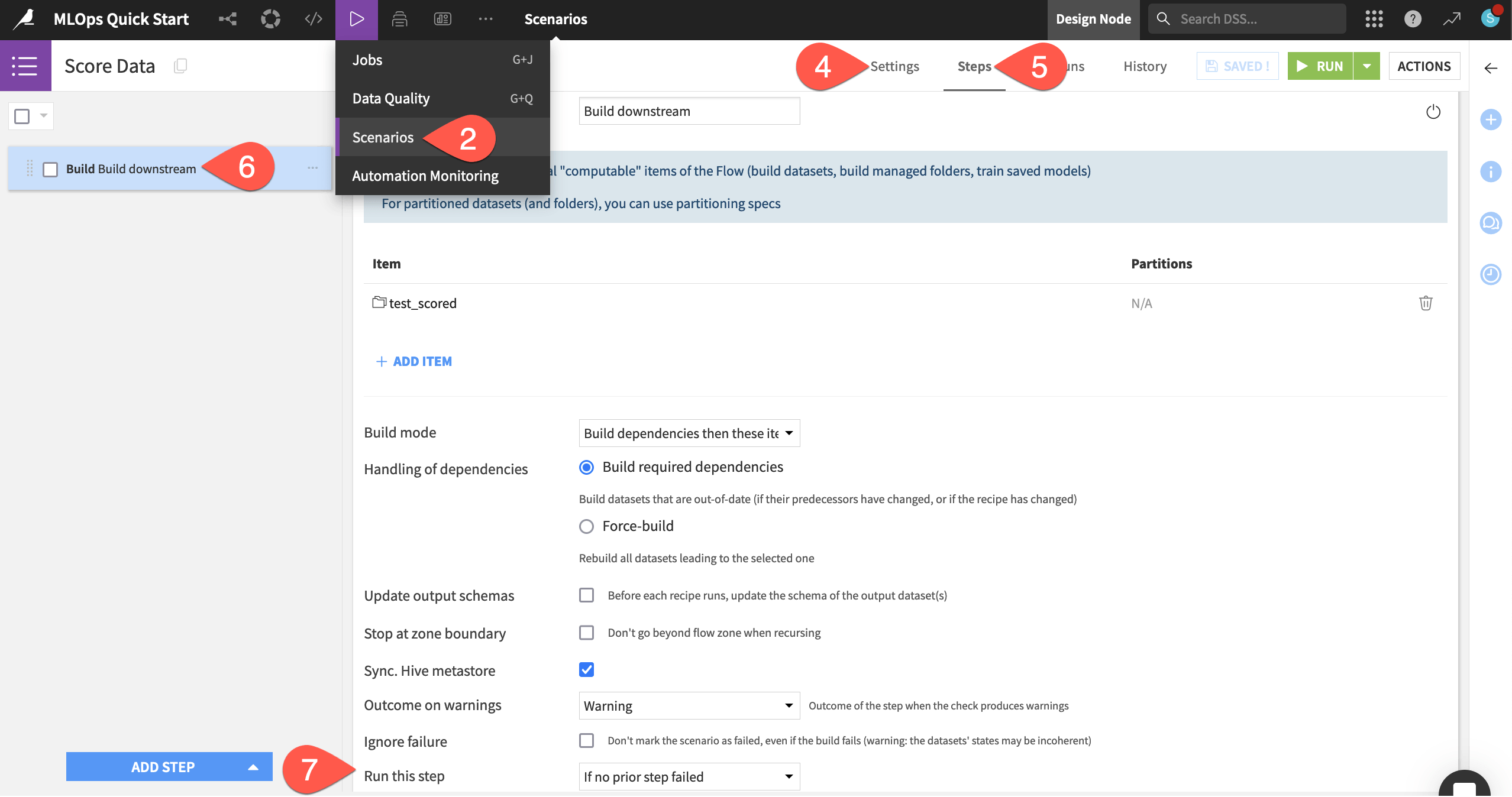
Navigate to the Steps tab.
Click on the Build step to see that this scenario will build the test_scored dataset (and its upstream dependencies, if required) whenever the scenario is triggered.
Recognize that this step will only run if no previous step in the scenario has failed.
Tip
To optimize scenario runs, you’ll learn about build modes in the Data Pipelines course of the Advanced Designer learning path.
Select a data quality rule type#
As of now, on a weekly basis, this scenario will attempt to build the test_scored dataset if its upstream dependencies have changed.
Scenarios include many options for when they should execute (such as time periods, dataset changes, or code). Additionally, they also include tools for control of how they should execute. For example, you may want to interrupt (or proceed with) a scenario’s execution if a condition occurs (or fails to occur).
Let’s demonstrate this principle by adding a data quality rule to an upstream dataset of interest.
In the Data Preparation Flow zone, open the job_postings_prepared dataset.
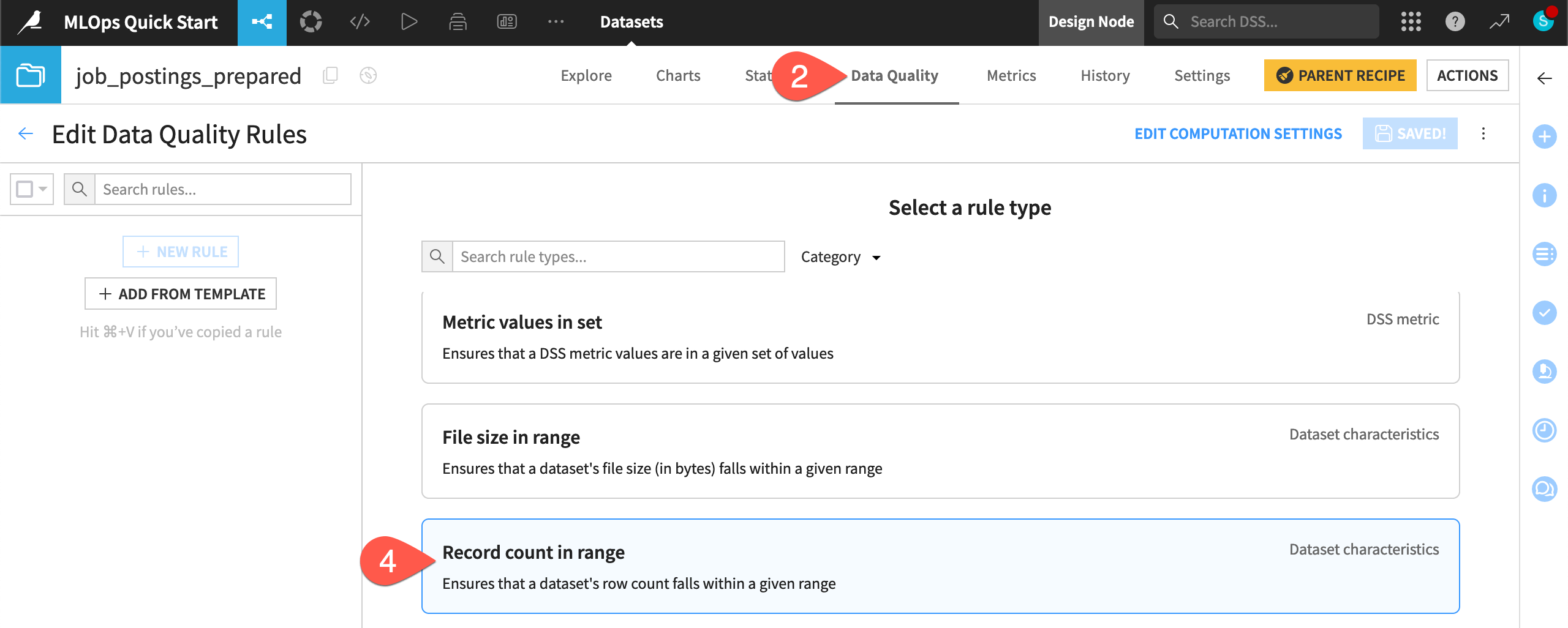
Navigate to the Data Quality tab.
Click Edit Rules.
Select the rule type Record count in range.
Configure a data quality rule#
Define this rule assuming you have expectations on the number of records at the start of the pipeline.
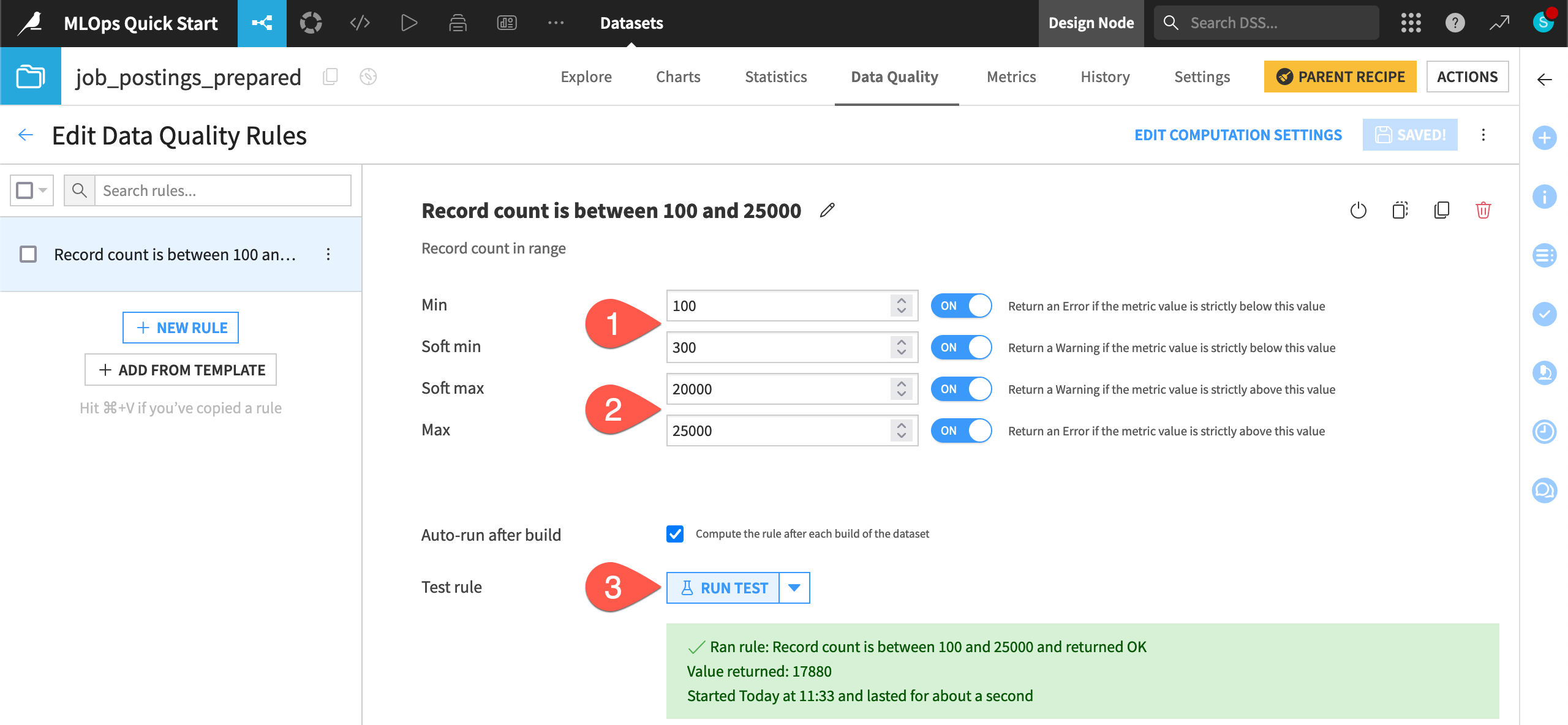
Set the min as
100and the soft min as300.Set the soft max as 20k (
20000) and the max as 25k (25000). Make sure to turn ON all conditions.Click Run Test, and confirm that the record count is within the expected range.
Tip
Feel free to adjust these values to simulate warnings or errors on your own!
Verify a data quality rule in a scenario#
Imagine this rule were to fail: the number of upstream records is greater than or less than expected. You could avoid computing the downstream pipeline, while also sending a notification about the unexpected result.
Make the scenario verify this rule before building the pipeline.
From the Jobs (
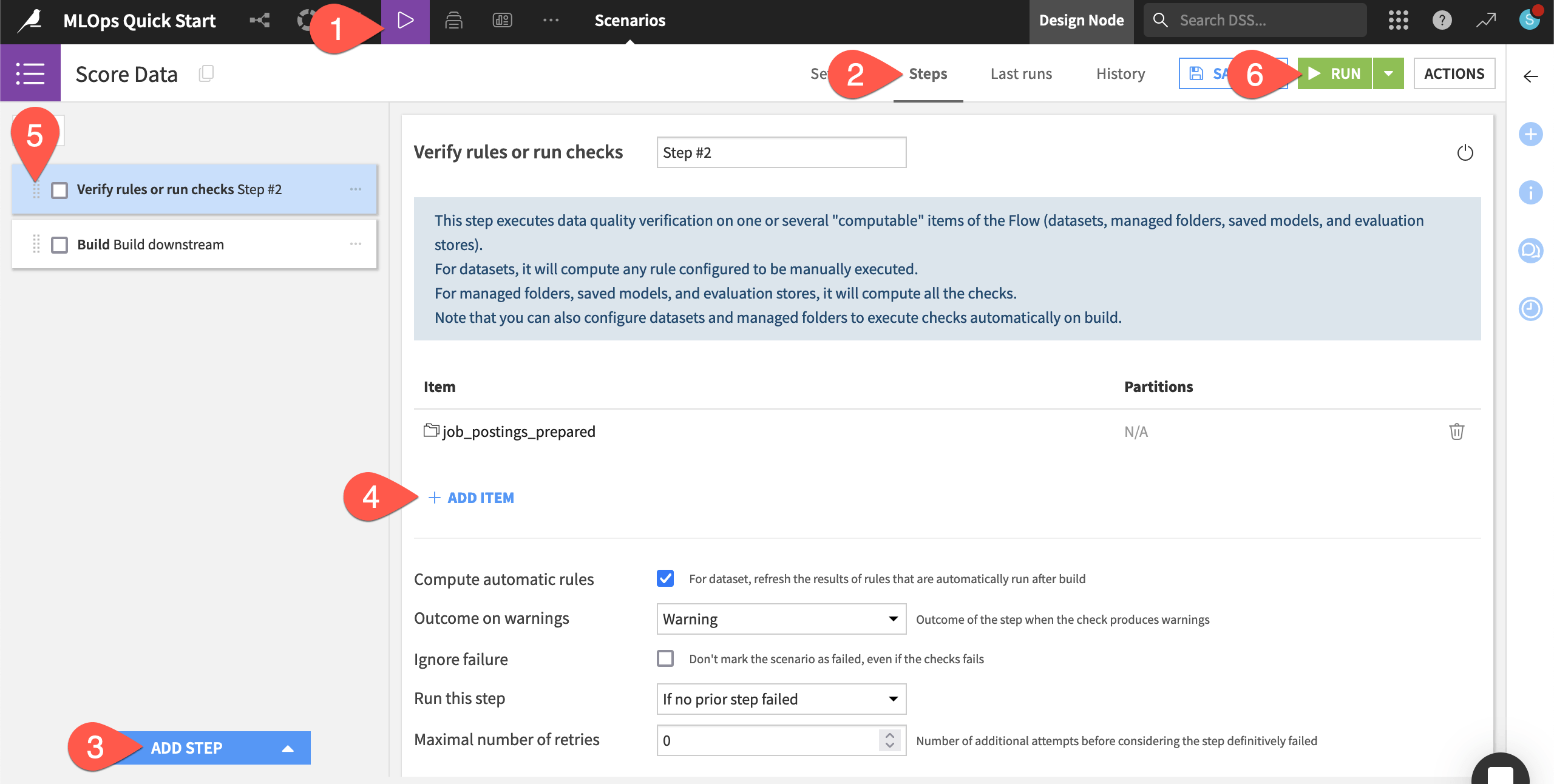
) menu in the top navigation bar, return to the Scenarios page, and open the Score Data scenario.Navigate to the Steps tab.
Click Add Step to view the available steps, and choose Verify rules or run checks.
Click + Add Item > Dataset > job_postings_prepared > Add.
Using the handle (
 ) on the left side of the step, drag the verification step to the first position.
) on the left side of the step, drag the verification step to the first position.Click Run to manually trigger the scenario’s execution.
Inspect the scenario run#
Take a closer look at what should be a successful scenario run.
Navigate to the Last runs tab of the scenario.
Click on the most recent run to view its details.
The scenario’s build step triggered a job. Click on the job for the build step, and see that There was nothing to do for this job.
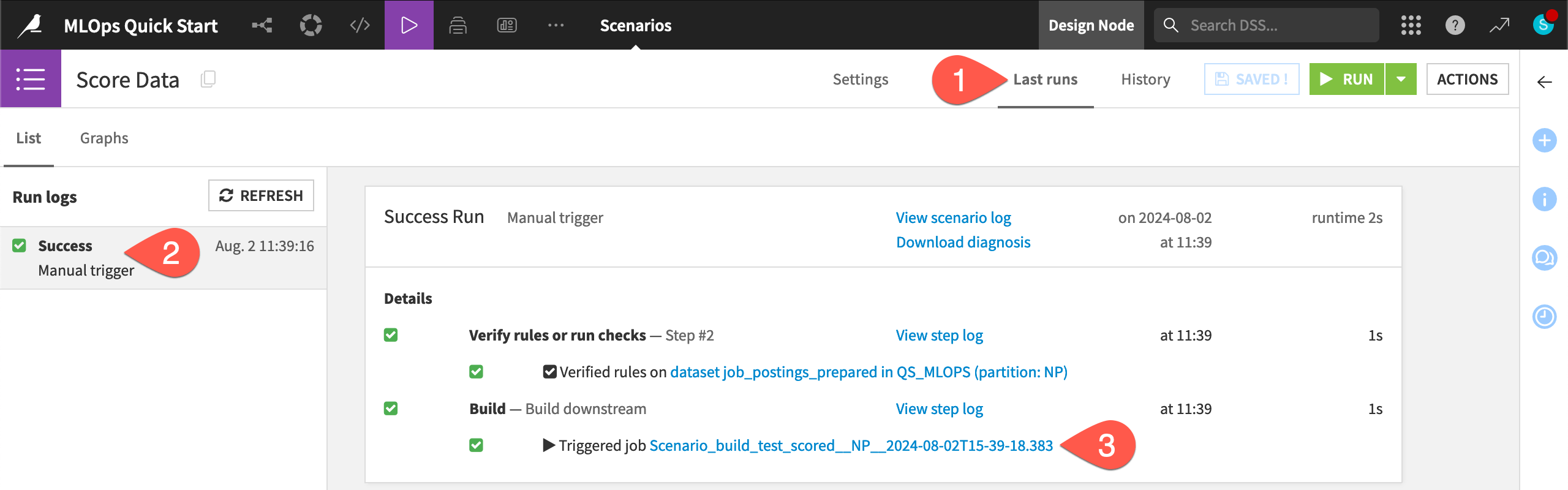
All that for nothing? What happened?
The data in the Flow hasn’t changed. The scenario was first able to successfully verify the Record count in range rule. This is the same result as when you directly tested the rule on the dataset. With this verification step done, the scenario could proceed to the build step.
The build step on the downstream test_scored dataset was set to build required dependencies. As this dataset wasn’t out of date, Dataiku didn’t waste resources rebuilding it.
See also
To see this job do some actual work, try the AI Collaboration Quick Start, where you’ll execute the same scenario via a reusable Dataiku app!