
Concept | Automation node preparation#
You may deploy a project to production within a batch processing framework. If so, you’ll also need to ensure that the Automation node is ready to receive the project bundle from the Design node.
Setting up the Automation node itself is typically the job of an instance administrator:
Administrators of self-managed instances should consult the reference documentation on Production deployments and bundles.
Dataiku Cloud users should review How-to | Install the Automation node.
On top of this, there are a few additional criteria to check that are specific to the project you want to deploy. Here is a sample of components concerning the Automation node that may require further attention before a successful batch deployment can occur.
Plugins#
A well-documented project includes a list of all plugins used in the project (likely in a wiki). An administrator must also install these plugins on the Automation node for the bundle to run successfully.
When deploying the bundle from the Deployer to the Automation node, you’ll see warnings during the bundle activation check about plugin differences between the Design and Automation nodes.
In the image below, many plugins found on the bundle’s Design node aren’t present in the Automation node. This, by itself, isn’t a problem. However, if the project uses any of these missing plugins, that will prevent the bundle from running successfully on the Automation node.
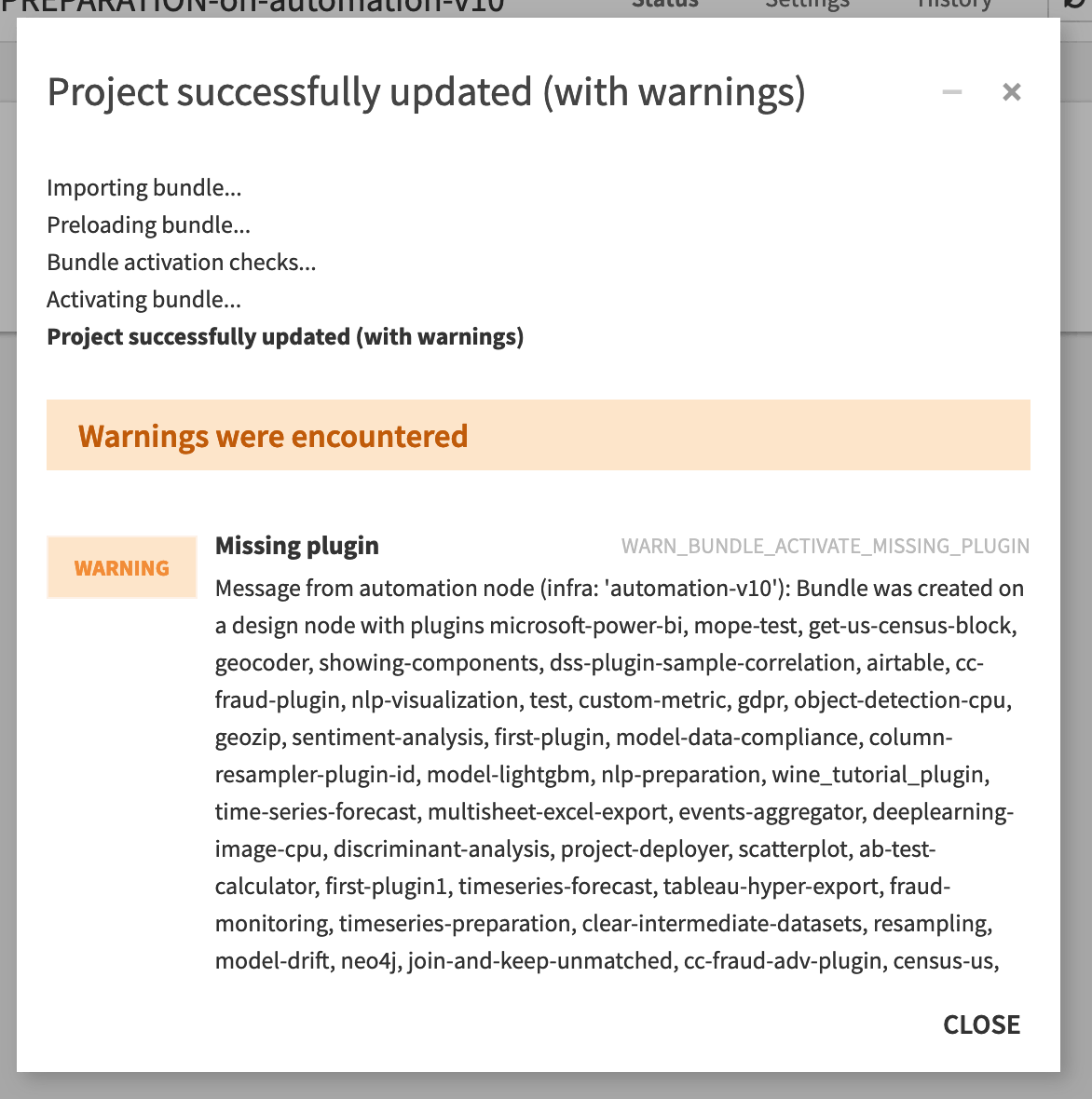
Connections#
Many organizations maintain separate data sources for the development and production stages of a project. Accordingly, it’s often necessary to remap connections in a project from the development sources on the Design node to the production sources on the Automation node.
However, to be able to do the actual remapping, the desired connections to production databases must exist on the Automation node. You may need to check with your instance administrators that the correct production connections are available.
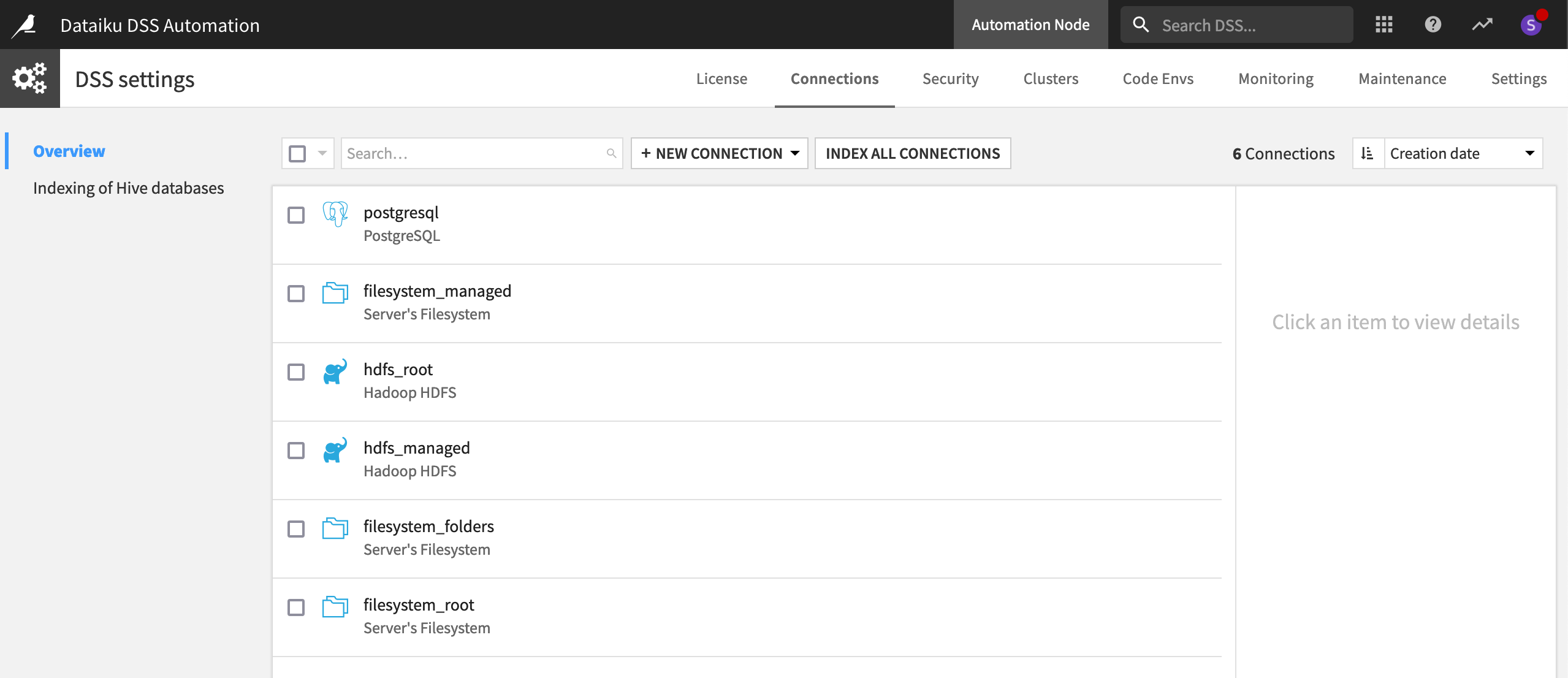
Code environments#
Any code environment used by a project should exist on the Automation node. In most cases, the code environment import setting on the Deployer will be to create a new code environment if it finds one in the project that doesn’t yet exist on the Automation node. As long as this is the case, there is no further action required from the user.
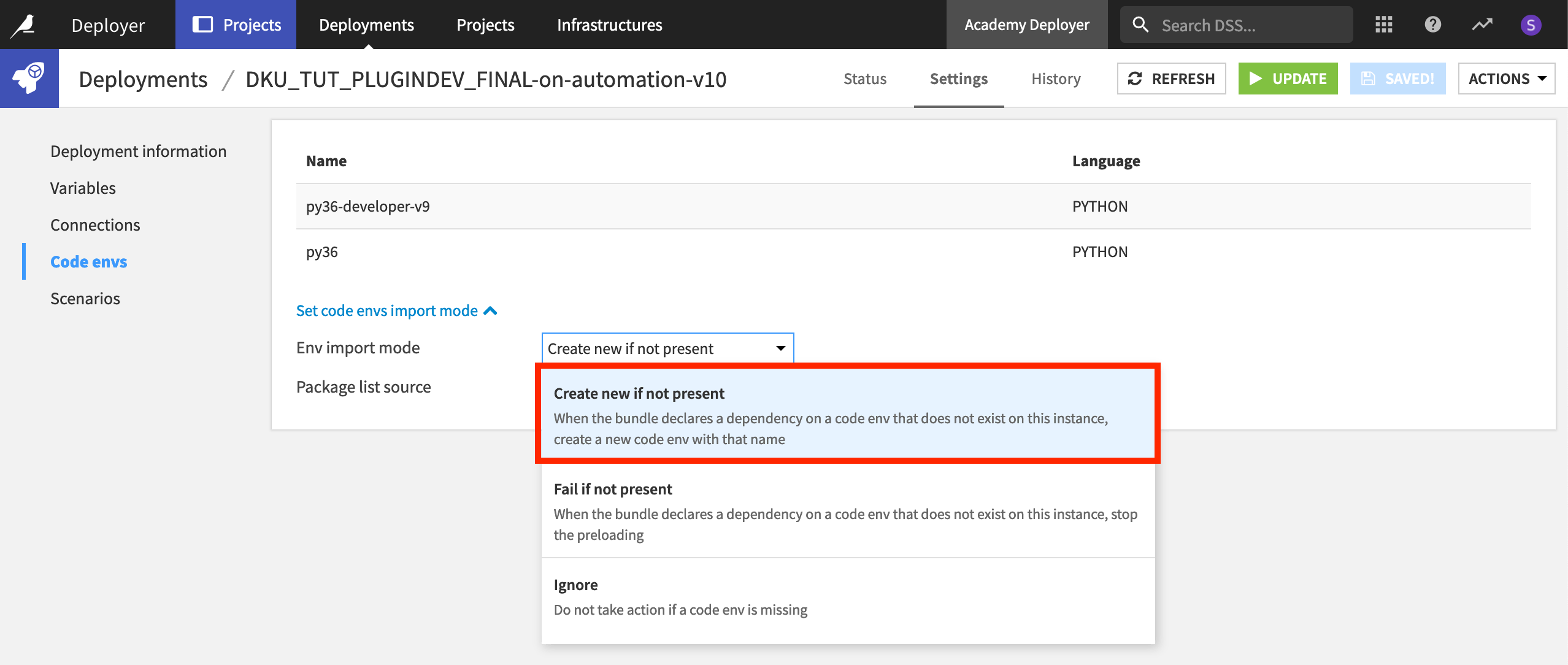
See also
Learn more about code environments on Automation nodes in the reference documentation.
Dataiku apps-as-recipes#
Plugin recipes won’t run on the Automation node without having installed the plugin. Similarly, consider a project that you are pushing to the Automation node uses a Dataiku app-as-recipe. Then, the parent project that’s used to create the Dataiku app-as-recipe must also be on the Automation node.
See also
Follow Tutorial | Build a Dataiku app-as-recipe for creating a Dataiku app-as-recipe.
Git#
You may be importing code from Git into project libraries on the Design node. If so, you need to ensure that the bundle on the Automation node will have access to the same code repositories.
See also
The reference documentation provides more details about Importing code from Git in project libraries.
Next steps#
Now that you’ve learned about how to prepare an Automation node to receive a project bundle, you might want to read about the actual process for creating, deploying, and versioning project bundles using a batch method of deployment.
See also
When preparing for a project deployment, you may also want to be aware of test scenarios. See Tutorial | Test scenarios to get started.