
Concept | How partitioning adds value#
Watch the video.
Partitioning in Dataiku is useful for processing sections (or partitions) of data independently, rather than in parallel. There are many ways that this independent processing of partitions can add value to a Flow.
Let’s see how the use of partitioning can:
Optimize the performance of time-based computations.
Create discrete, targeted features for a machine learning model.
Optimize Performance with Time-Based Dimensions#
We can use time-based partitioning to optimize the performance of our Flow.
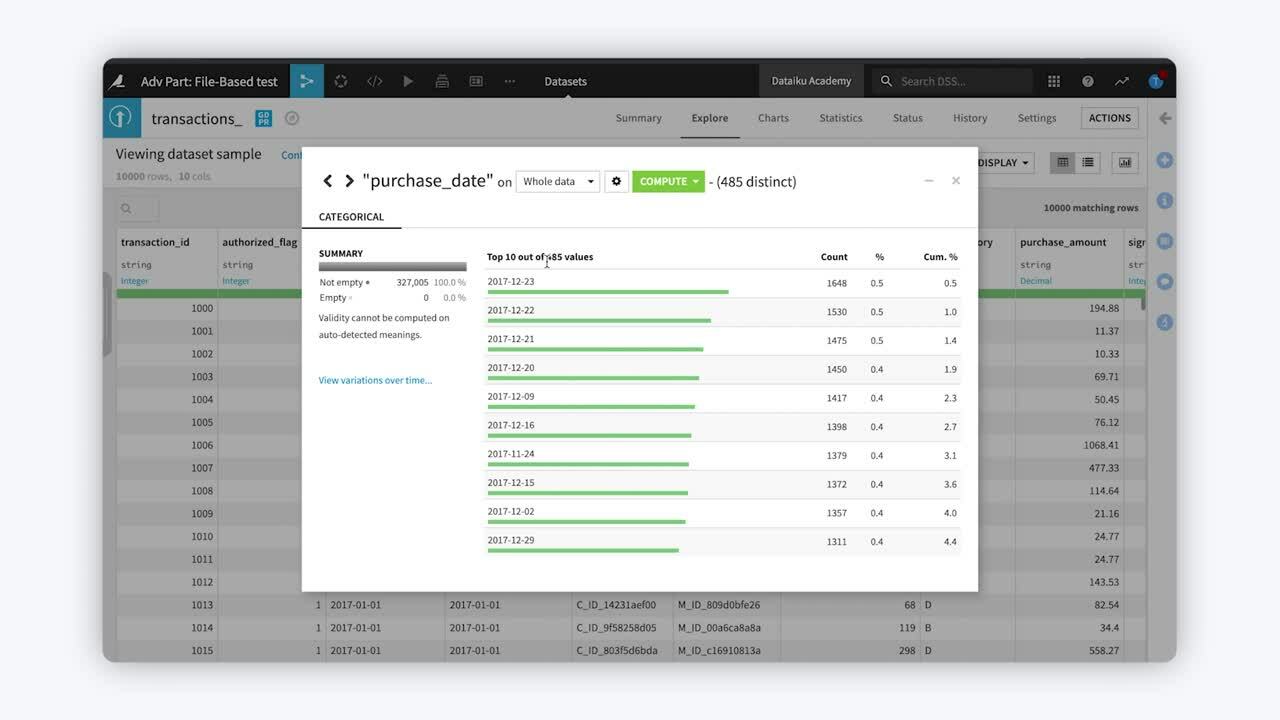
In this example, the purchase date column of our dataset contains 485 distinct values. Suppose we want to run the computations in the Flow on a subset of the dataset, for instance, on data occurring in a specific time period, such as a “Day.”
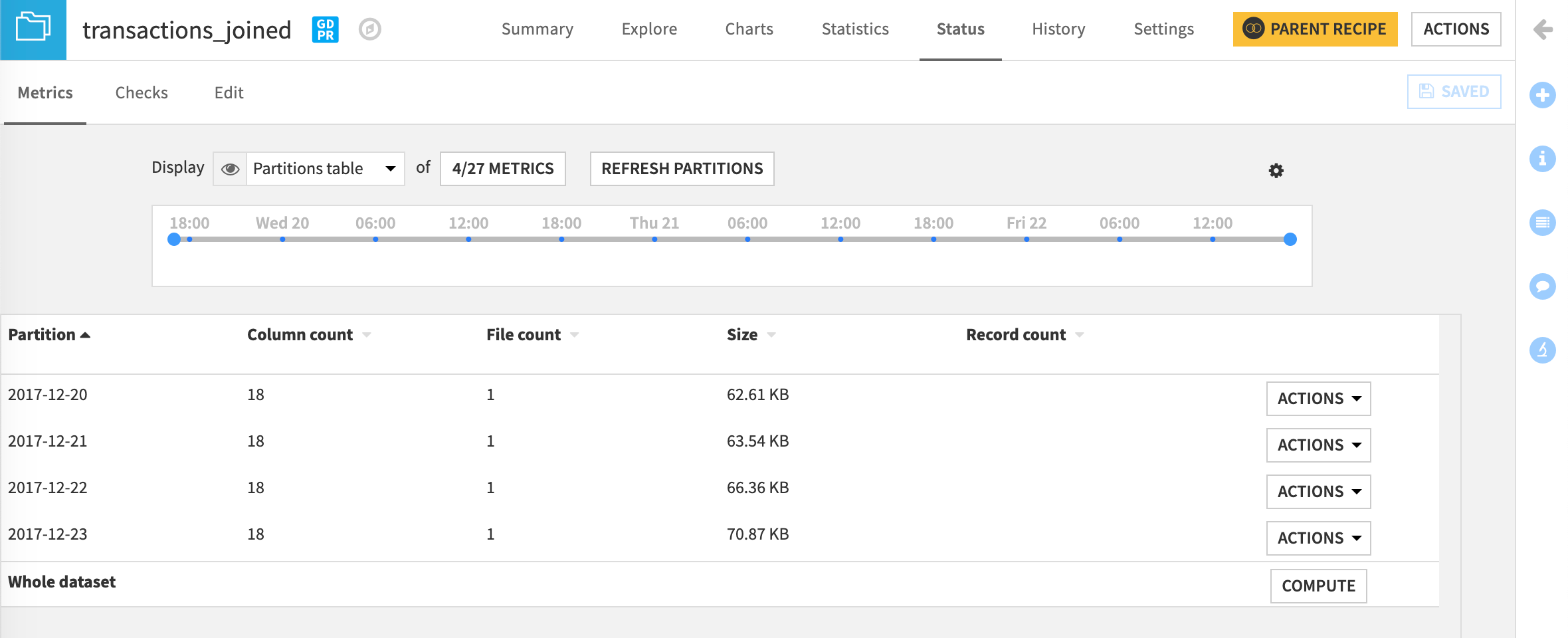
With this dataset partitioned by day, we could target a date or a range of dates, such as 2017-12-20 to 2017-12-23.
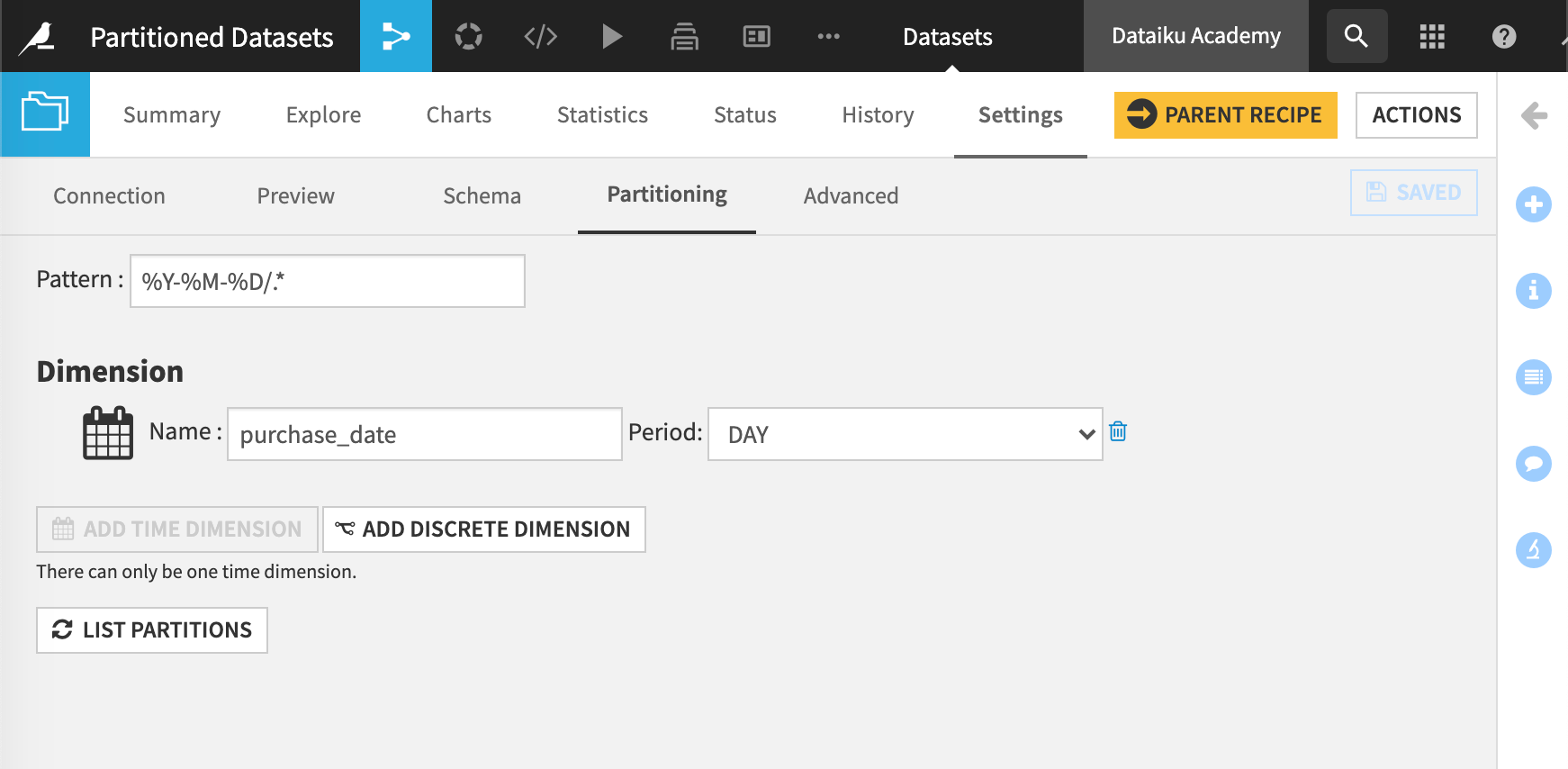
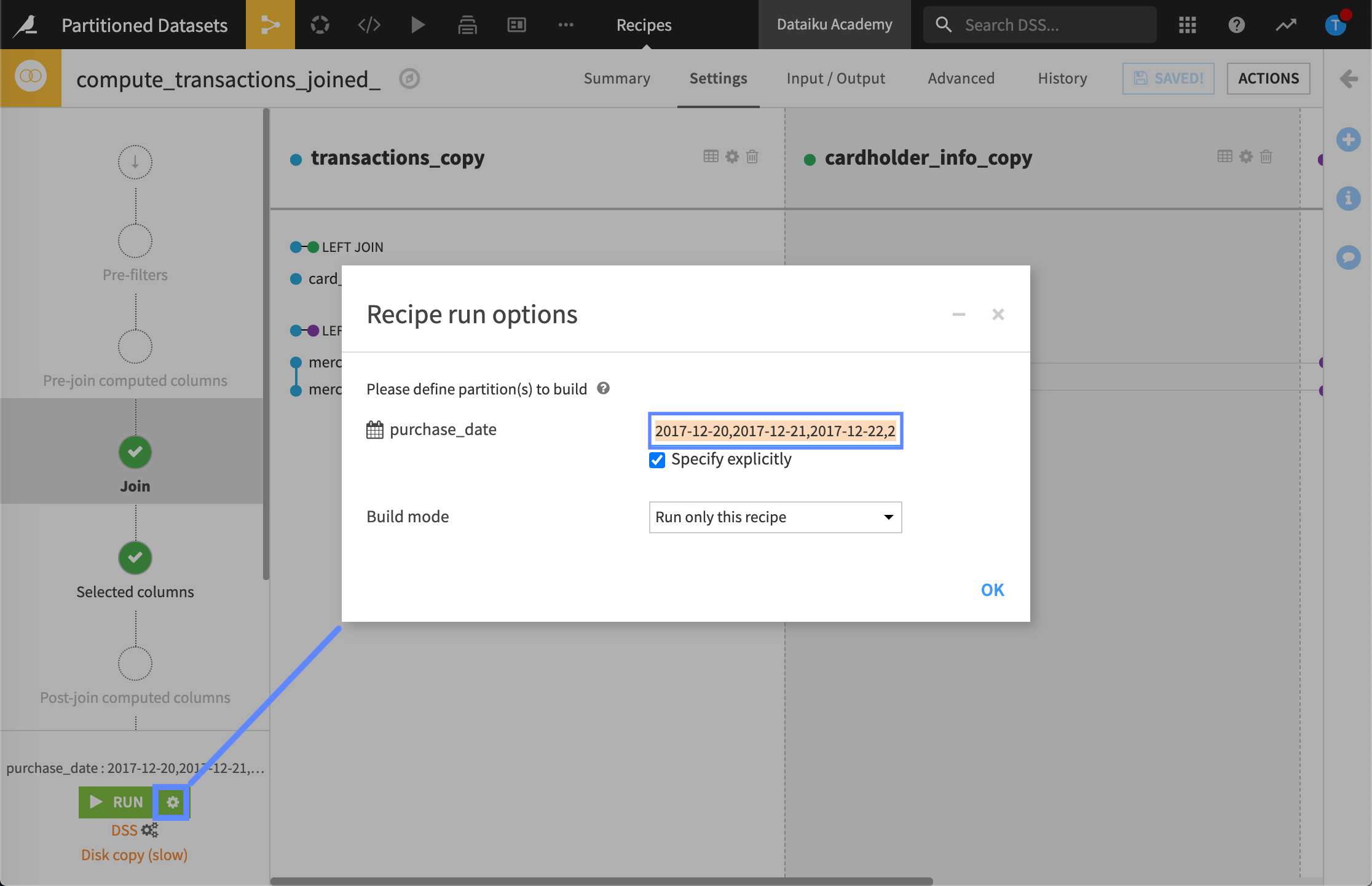
In our example, we’re using a Join recipe to create a new, partitioned, output dataset. To specify what partition we want to build in the output dataset, we configure the target identifier, 2017-12-20,2017-12-21,2017-12-22,2017-12-23 in the Recipe run options of the Settings tab.
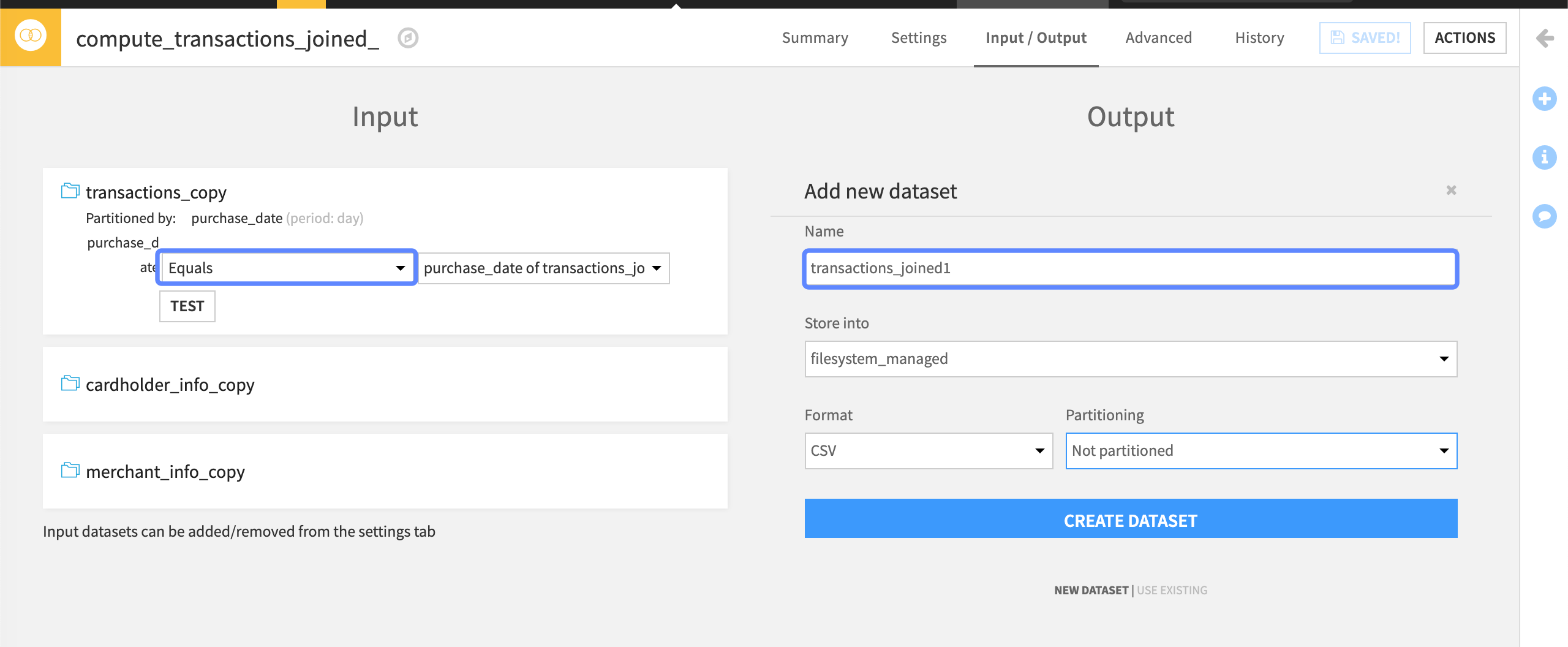
In the Input / Output tab of the recipe, we can set the partition dependency function type to Equals and name our output dataset.
We now have four partitions on which to apply computations independently. Working with these partitions can help to optimize the performance of our Flow.
Create Targeted Features for a Machine Learning Model using Discrete-Based Dimensions#
Let’s look at adding another partitioning dimension, a discrete dimension, to the data in our Flow.
Our goal is to target data making up specific merchant subsectors, such as gas, internet, or insurance. We can then specify one or more subsectors to use in computations in our Flow. Once we have the partitions available to us, we can also use the different subsectors as features in our machine learning model.
The merchant subsector column in our non-partitioned joined dataset contains 38 distinct values.
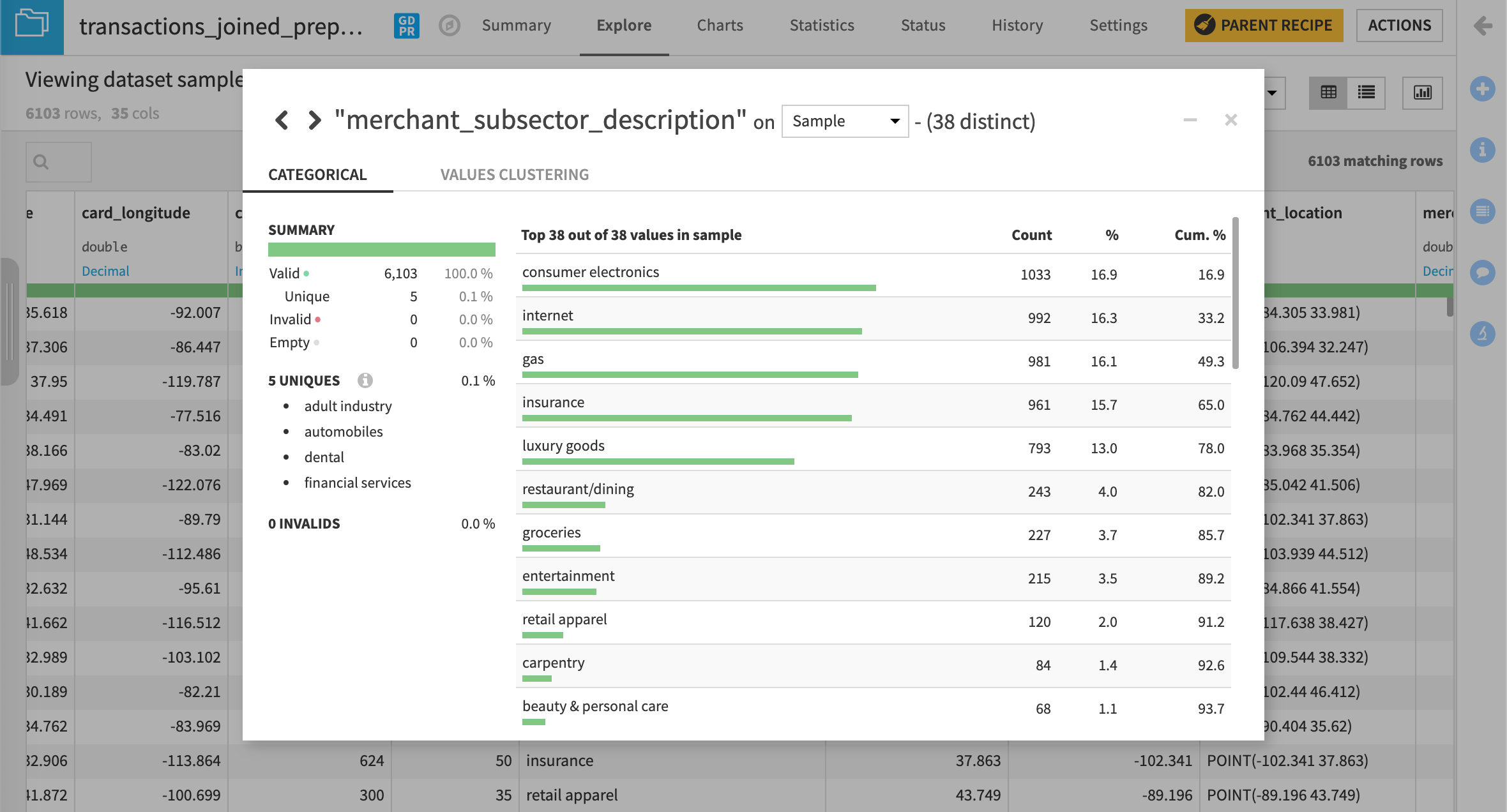
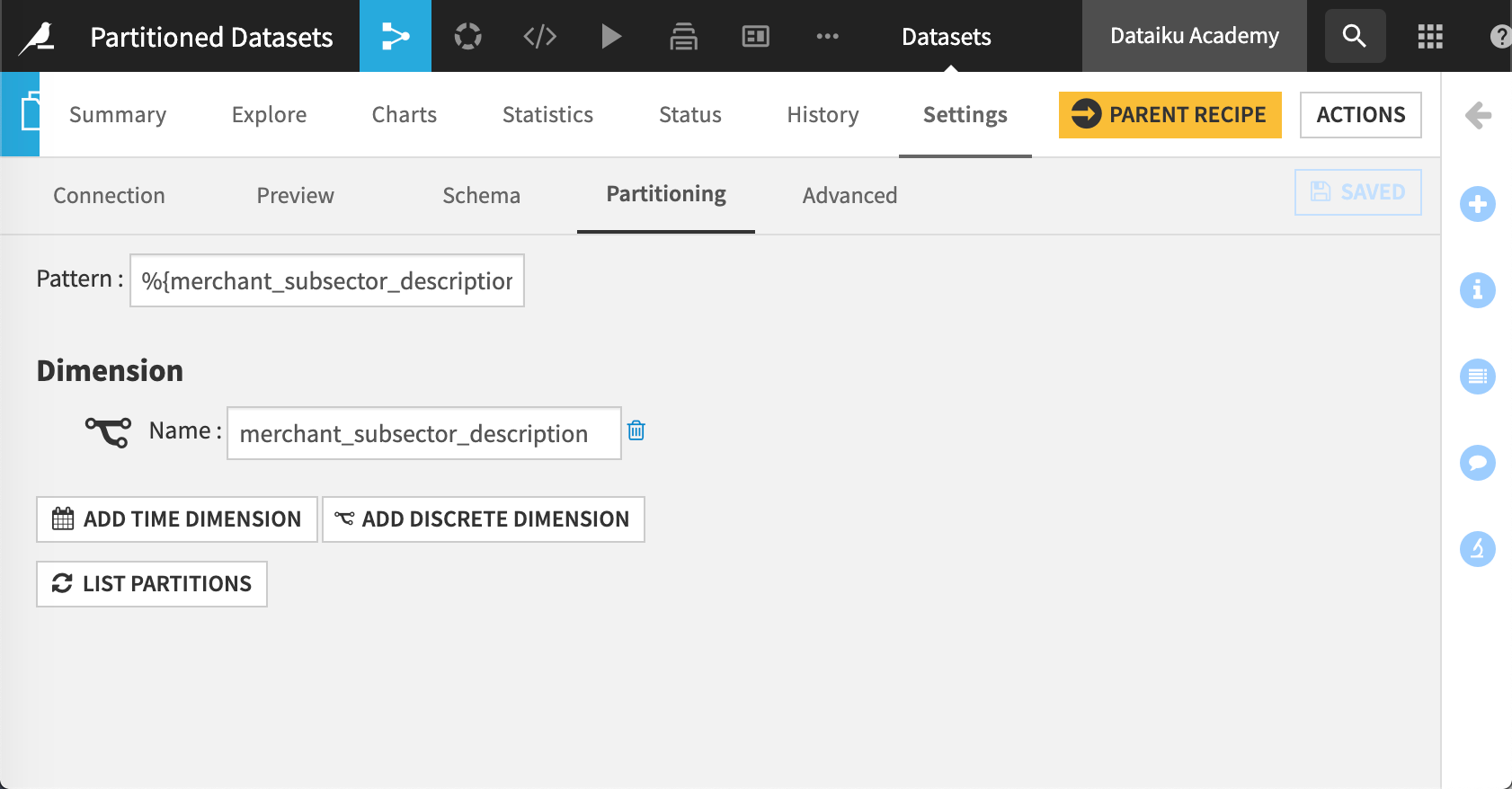
By partitioning this dataset using merchant_subsector, we can target a specific subsector or several subsectors.
We can now train our machine learning model on the targeted subsectors, or even a specific subsector, such as internet.
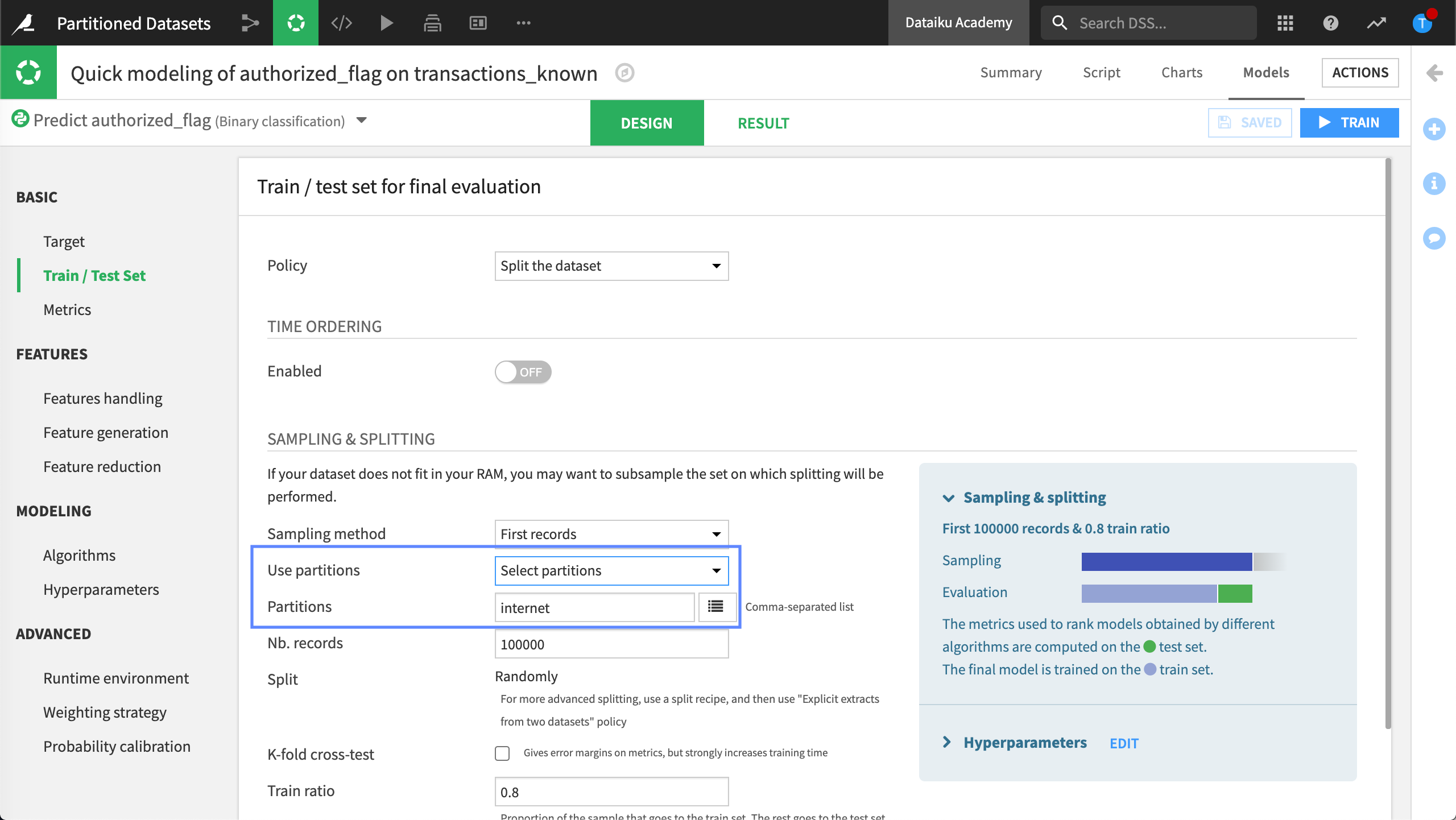
As a result, we can now make predictions on credit card transactions by subsector.
Next steps#
In this lesson, we talked about two important use cases of partitioning and how it adds value to the Flow. You can try building partitions in the tutorials in the Partitioning course. Visit the Dataiku reference documentation on partitions to find out more about working with partitions.