
Concept | Partitioning in a scenario#
Watch the video
Using scenarios, we can automate the build of our partitioned datasets. We can even define schedules, such as daily or monthly, and use keywords or variables to identify which partition to build.
Example: Time-based dimension#
One benefit of using a scenario is the ability to schedule tasks triggered by fixed time periods. For example, we can create a scenario to run a daily scheduled task to build all partitions in a date range.
Note
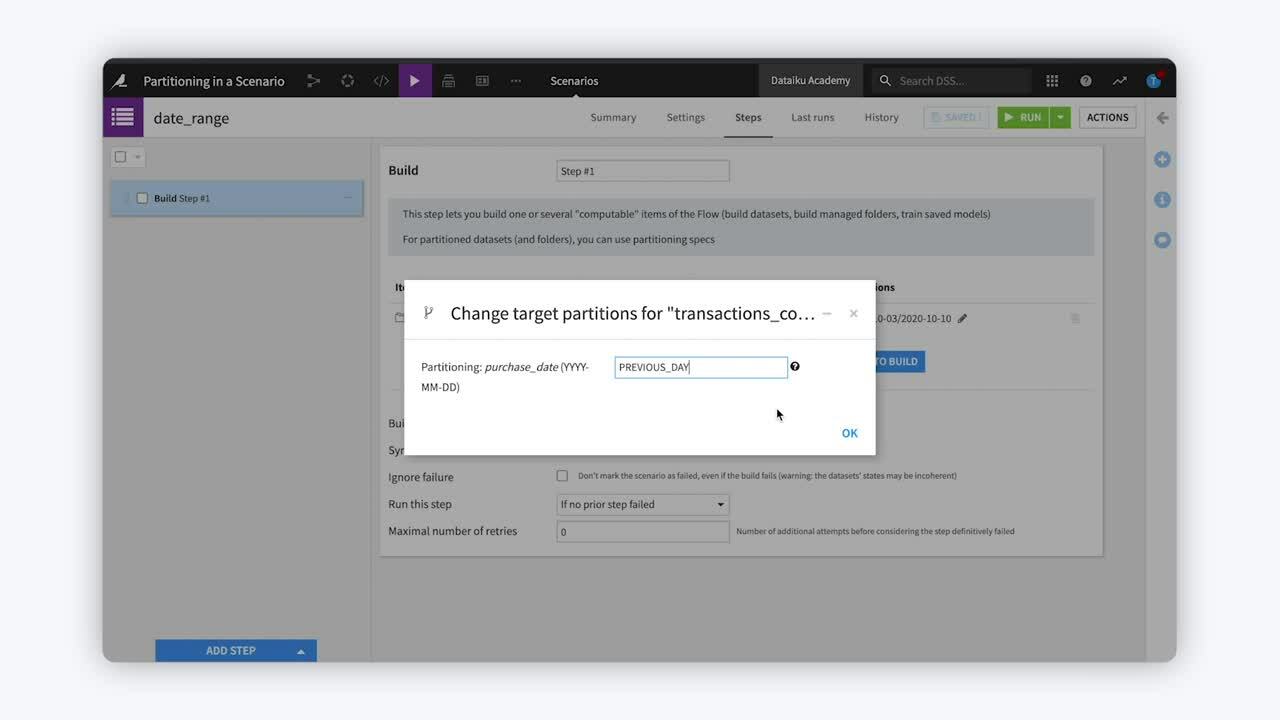
To tell Dataiku to select all partitions in a date range, use the “/” character between the two dates.
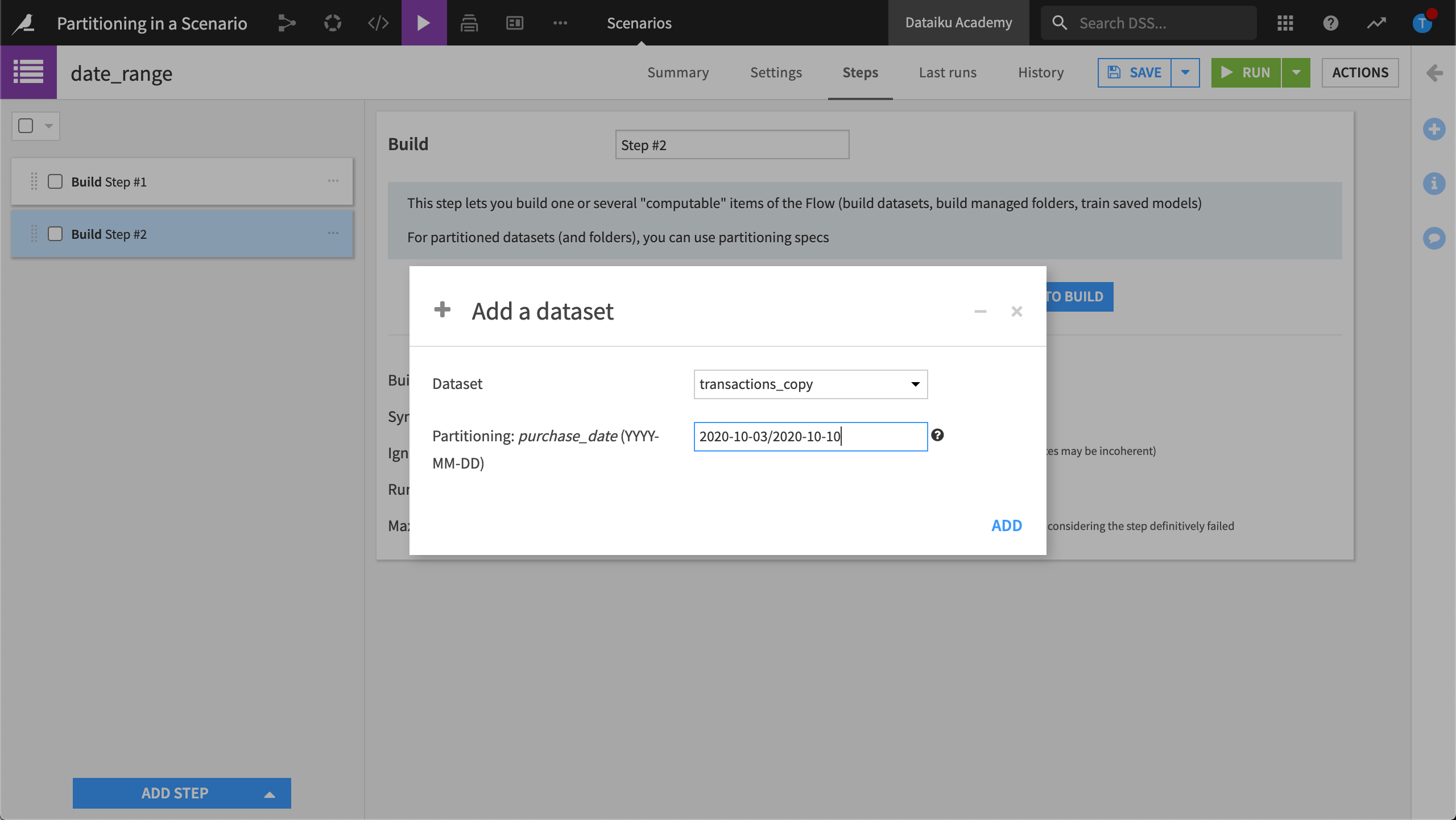
With this scenario scheduled to run on a daily trigger, Dataiku will build every partition in this date range, every day.
Keywords#
For time-based partitioning, we can also use special keywords. For example, for a daily scheduled task, we could use PREVIOUS_DAY to build the partition corresponding to the previous day, every day.
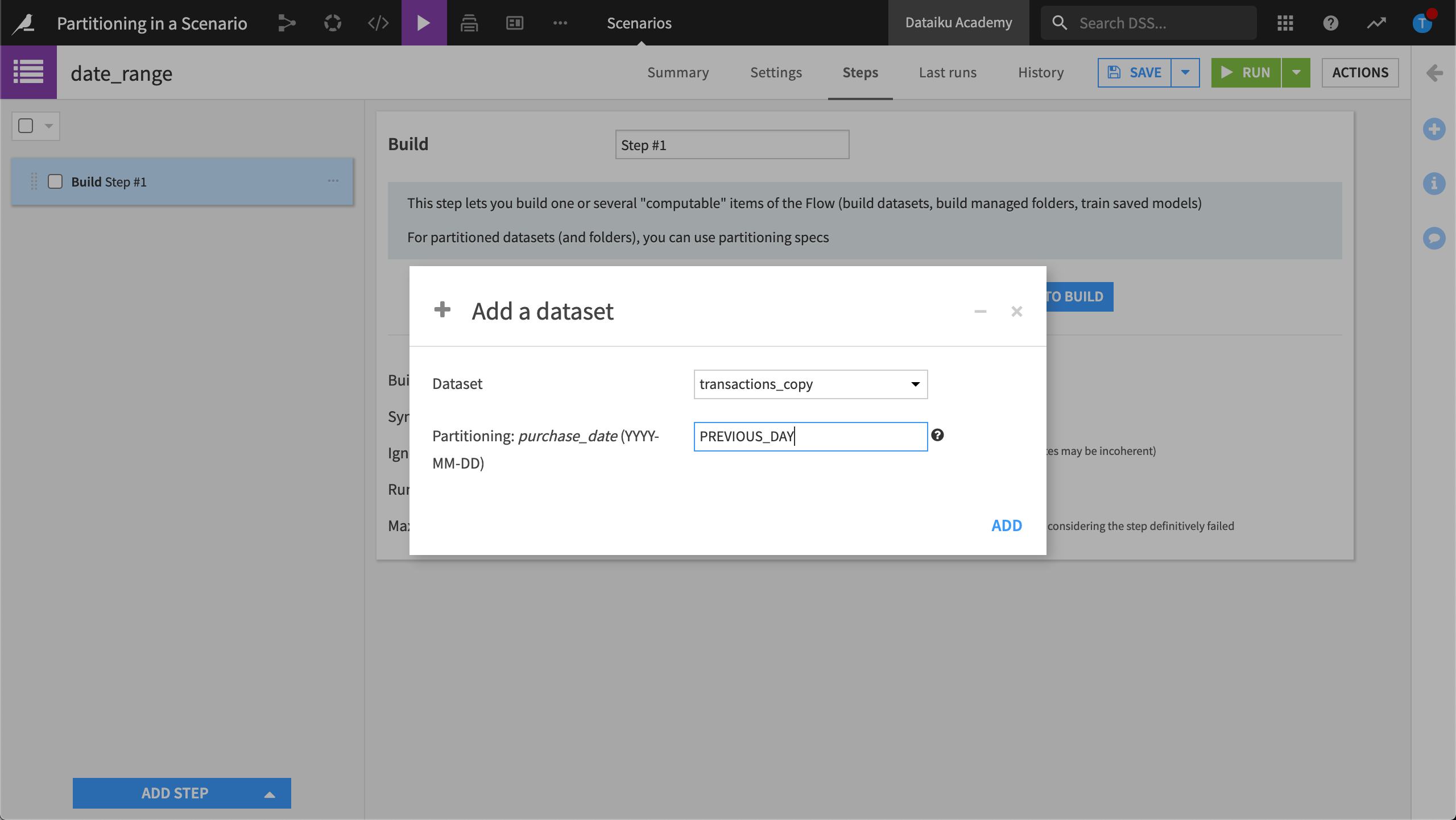
This way, we can automatically select the partition corresponding to the previous day without having to edit the parent recipe in the Flow.

For more examples of ways to use keywords, visit the Variables in scenarios in the in the reference documentation.
Variables in scenarios#
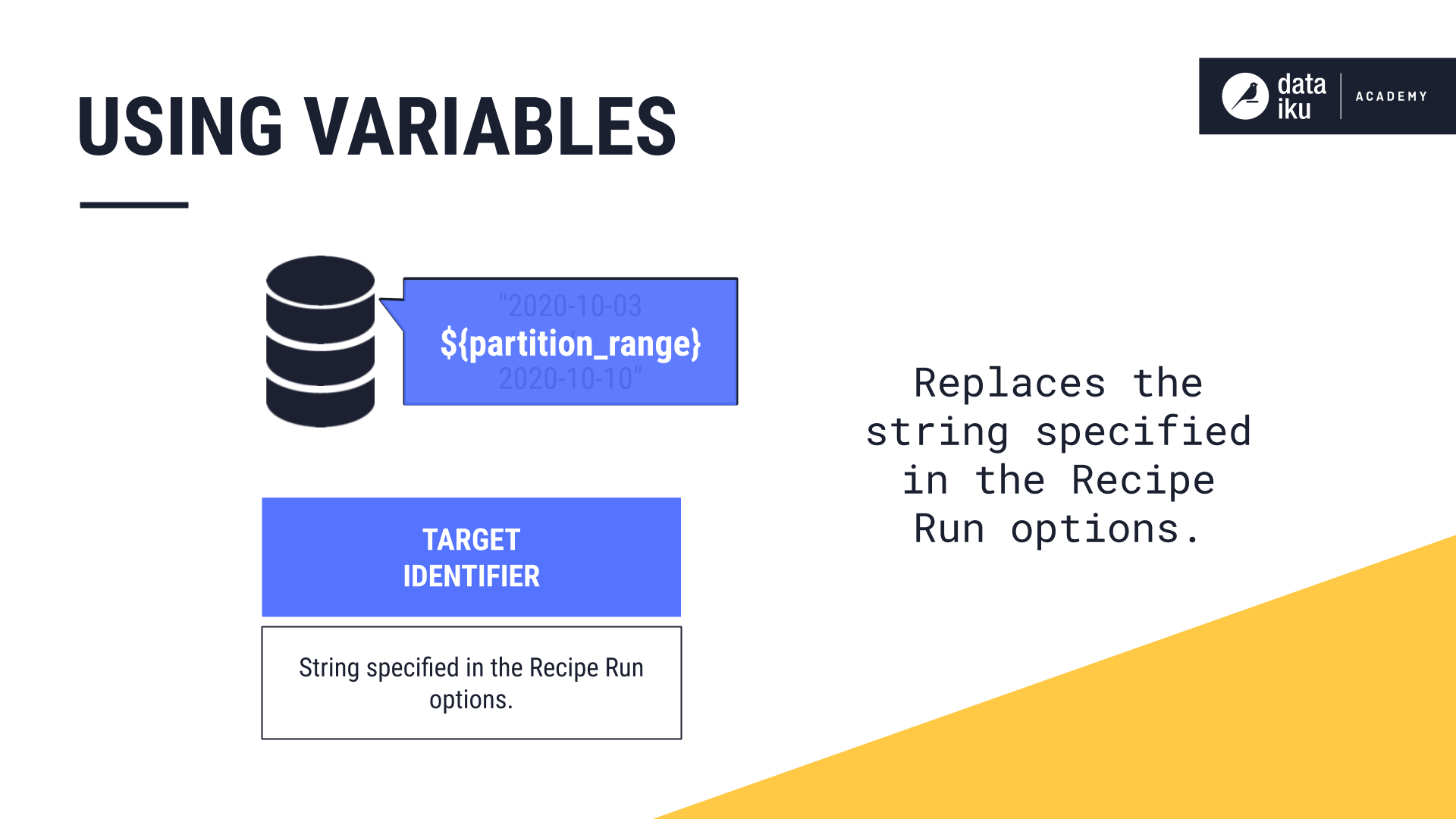
To make this process more flexible, we can use variables to specify the target identifier, or the partition identifier. The variable replaces the string that identifies what partitions we want in the output dataset.
Build partition corresponding to last week#
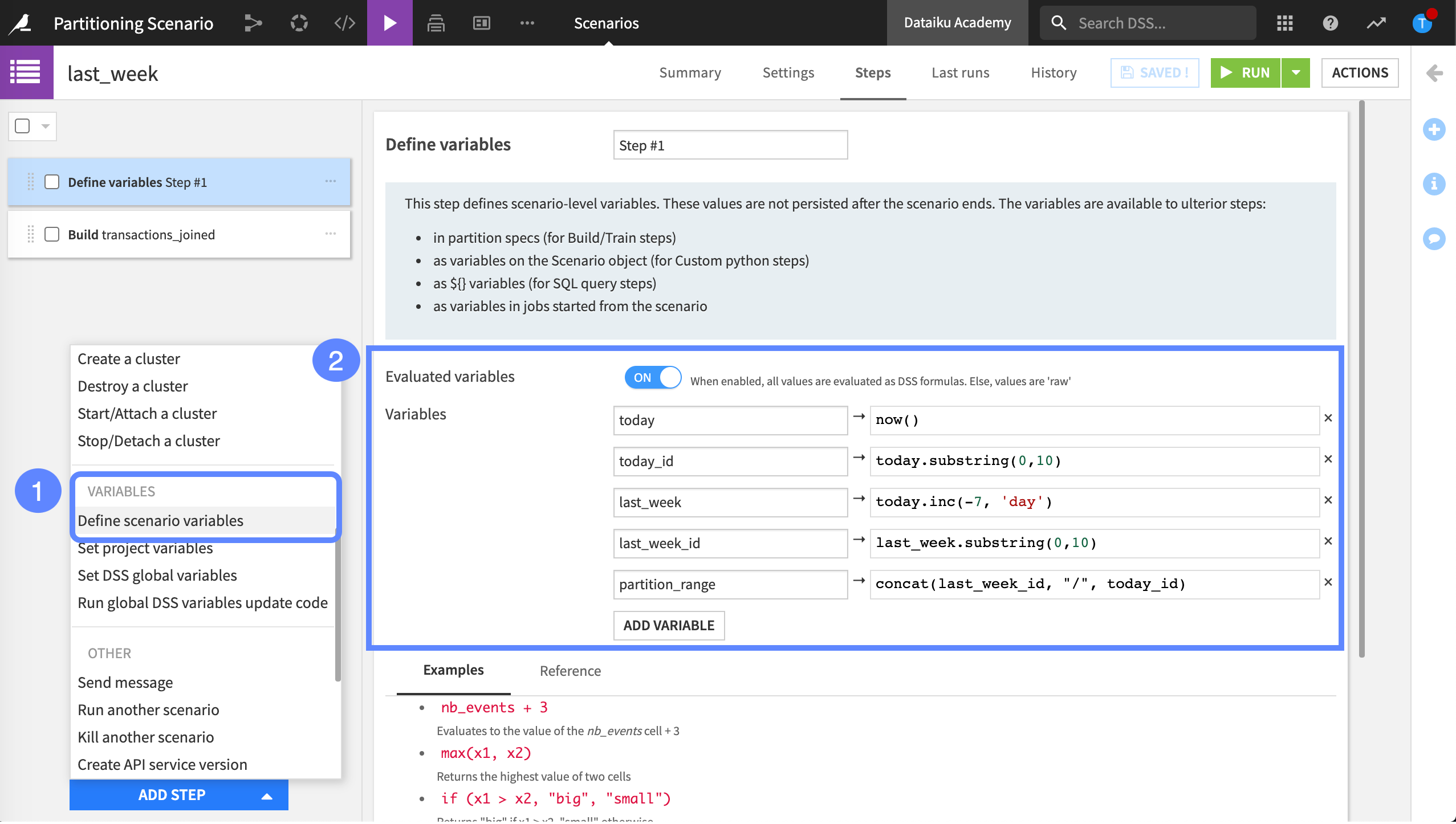
To build a partition corresponding to last week, we can use the Define scenario variables step.
In this example, we’ve created five variables:
todayuses the expressionnowand is the end of our date range.today_idlets us referencetoday.last_weekuses an expression that looks back seven days, and is the beginning of our date range.last_week_idlets us referencelast_week.partition_rangelinks the variables,todayandlast_week, together.
Finally, with our variables defined, we add another Build step to set our target identifier to the third variable we created, partition_range. Applying the proper syntax, we wrap the name of the variable in curly braces and add a “dollar sign” to the front, resulting in ${partition_range}.
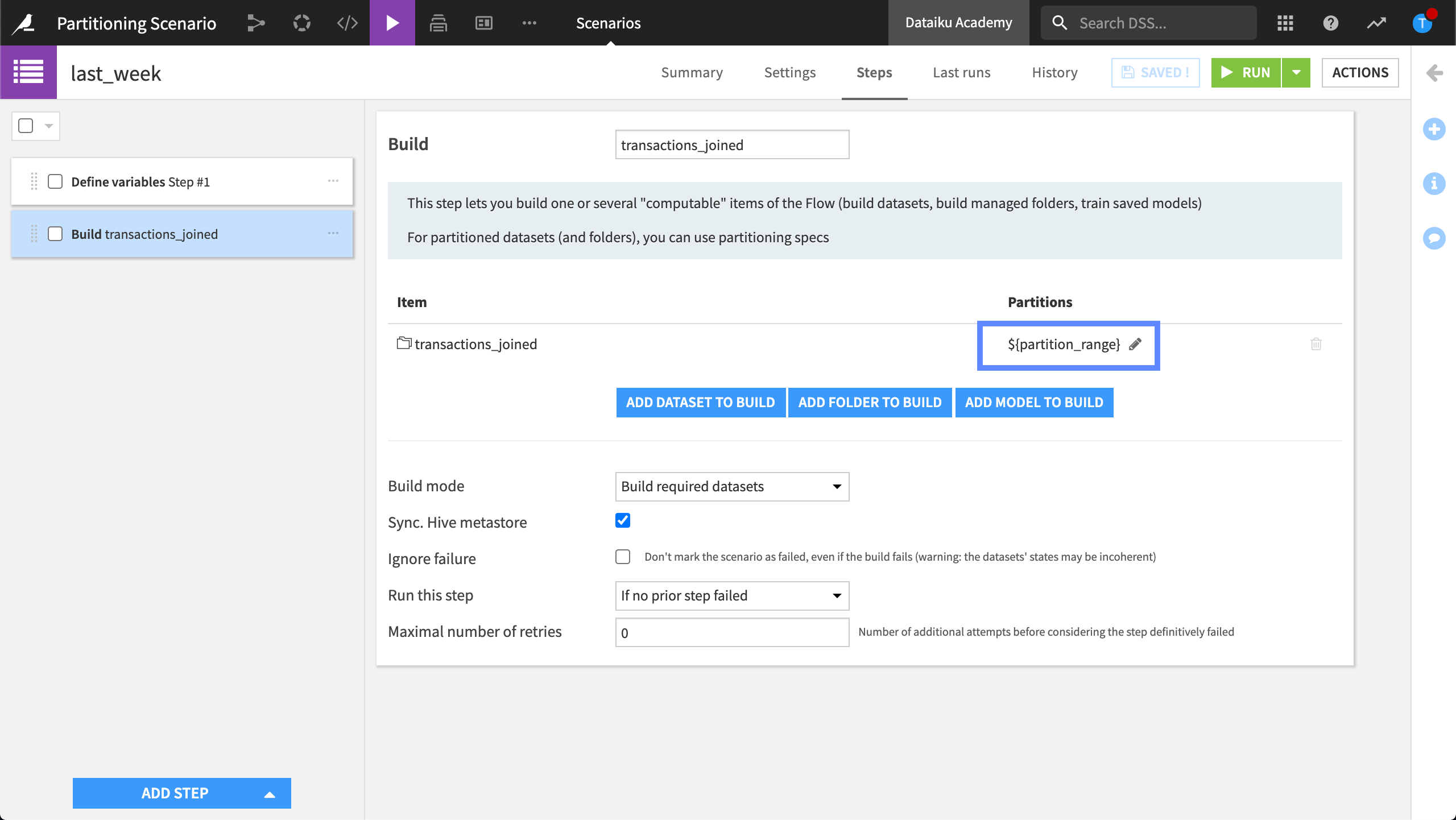
When we run this scenario, Dataiku will compute the partitions corresponding to the dates in the partition range.
Example: Discrete-based dimension#
We can also use scenarios to build partitions along a discrete-based dimension. In this example, we’ll create a custom Python script instead of a sequence of steps.
In the Script tab, we’ve defined the dataset and the discrete partition that we want to build.
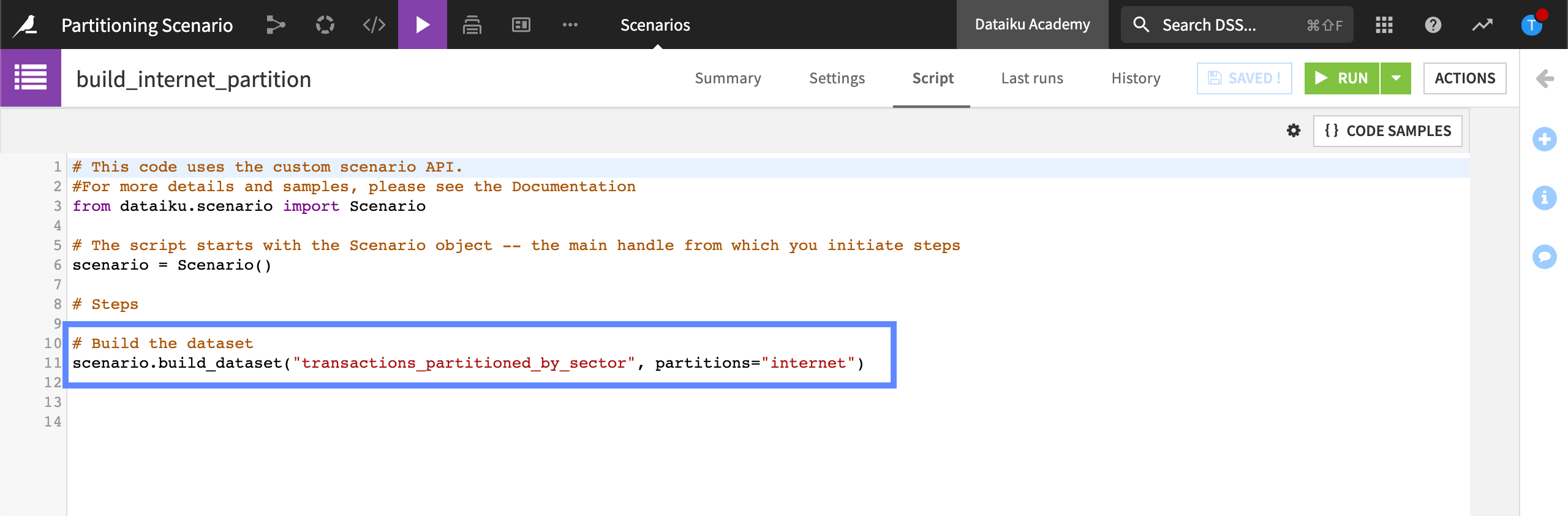
When we run this scenario, Dataiku will compute the “internet” partition.
Next steps#
In this lesson, we discovered different ways we can use scenarios to automate the build of our partitioned datasets. You can visit the Dataiku reference documentation to find out more about working with Variables in Scenarios.