
Deploying the model#
The model being created and trained, we may now want to be able to use it to “score” potential churners on a regular basis (every month for example). To make sure the model will remain robust over time, and to replicate what’s going to happen when using it (new records arrive on a regular basis), we can create the “test” set to score.
This is where the modeling process, and notably the train/test split strategy, gets a little bit more tricky.
Let’s say our current timestamp is T, then all the features created for the test set must depend on times t <= T. Since we need to keep 4 months worth of future data to create the target variable in our training set (did the customer repurchase?), the target will be generated from the data in the [T, T + 4 months] time interval, and the train features will use values in the [T - 4 months, T] interval, this way data “from the future” won’t leak in the features. Since we originally choose the reference date to be 2014-08-01, let’s choose T as 2014-12-01 for our test set to stay aligned with what we have already done. To sum up:
train set target is based on data between 2014-08-01 and 2014-12-01
train set features are based on data before 2014-08-01
test set features are based on data before 2014-12-01
test set optional target can be computed with data between 2014-12-01 and 2015-03-01
Also, to make our scripts more flexible, we will set these train and test reference dates as Dataiku global parameters, as described here. Click on the Administration menu on the top right of your screen, then select Settings on the top right and Variables on the top left:
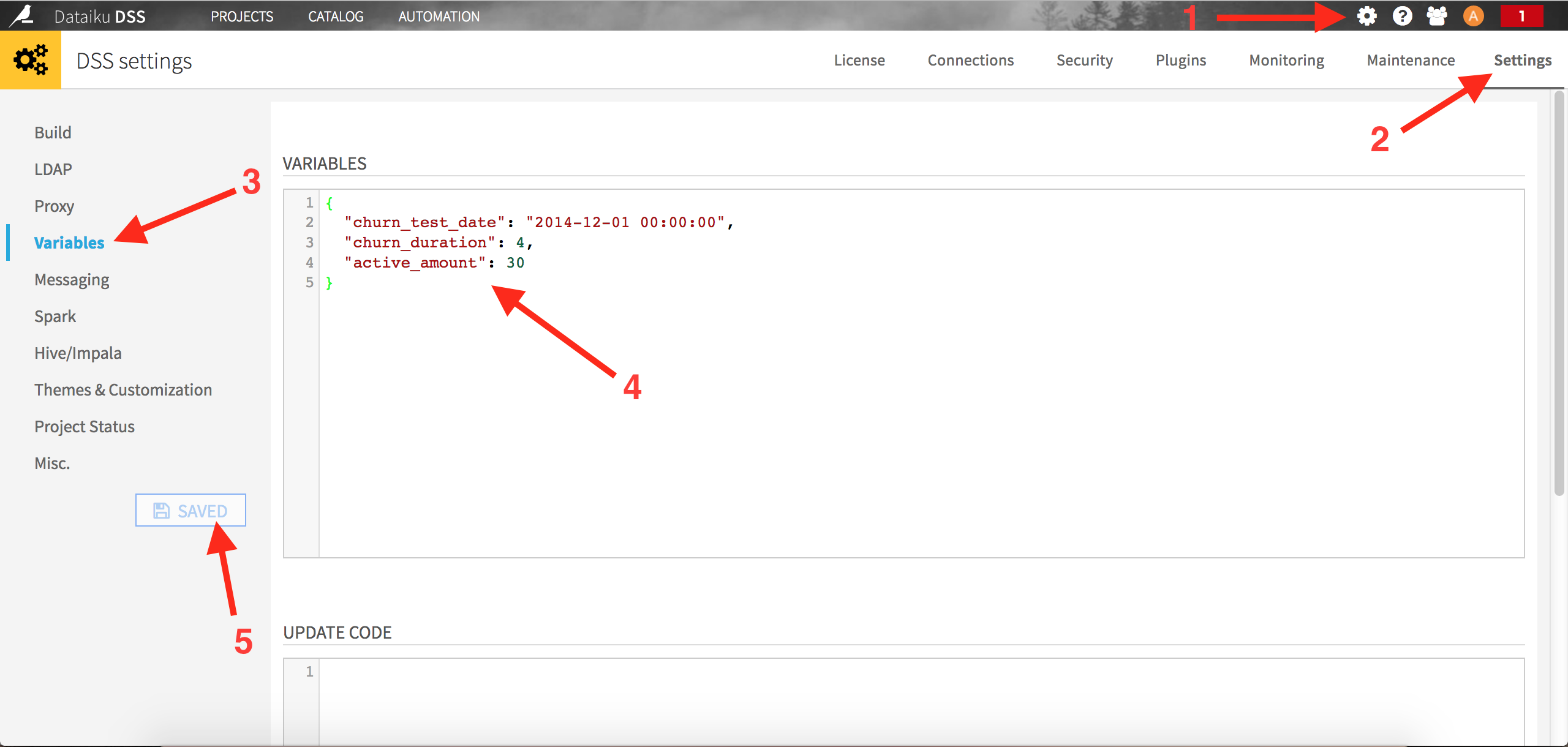
The content of the variables editor is the following:
{
"churn_test_date": "2014-12-01 00:00:00",
"churn_duration" : 4,
"active_amount" : 30
}
The first parameter is our reference date, when we want to actually score our clients. In a production setting, this could be replaced by “today” for example (we refresh the churn model to predict what’s going to happen everyday). The second parameter defines the number of months to use to build our features. The last parameters is the threshold we used for our “best” client definition.
Now let’s update our 3 SQL recipes using these new global variables. For example the first one (selecting the customers to use for our training set) becomes:
SELECT * -- select customers with total >= active_amount
FROM (
-- select active users and calculate total bought in the period
SELECT
user_id ,
SUM(price::numeric) AS total_bought
FROM
events_complete events
WHERE
event_timestamp < TIMESTAMP '${churn_test_date}'
- INTERVAL '${churn_duration} months'
AND event_timestamp >= TIMESTAMP '${churn_test_date}'
- 2 * INTERVAL '${churn_duration} months'
AND event_type = 'buy_order'
GROUP BY
user_id
) customers
WHERE
total_bought >= '${active_amount}'
;
Modify the two others recipes accordingly.
Moving to the test set, you should also be able to create the 3 required datasets using these SQL recipes:
-- Test set population
SELECT
*
FROM (
SELECT
user_id,
SUM(price::numeric) AS total_bought
FROM
events_complete events
WHERE event_timestamp < TIMESTAMP '${churn_test_date}'
AND event_timestamp >= TIMESTAMP '${churn_test_date}'
- INTERVAL '${churn_duration} months'
AND event_type = 'buy_order'
GROUP BY
user_id
) customers
WHERE
total_bought >= '${active_amount}'
-- Test set target variable
SELECT
client.user_id,
CASE
WHEN loyal.user_id IS NULL THEN 1
ELSE 0
END as target
FROM
test_active_clients client
LEFT JOIN (
SELECT DISTINCT user_id
FROM events_complete
WHERE event_timestamp >= TIMESTAMP '${churn_test_date}'
AND event_timestamp < TIMESTAMP '${churn_test_date}'
+ INTERVAL '${churn_duration} months'
AND event_type = 'buy_order'
) loyal ON client.user_id = loyal.user_id
-- Complete test set
SELECT
test.*,
nb_products_seen,
nb_distinct_product,
nb_dist_0,
nb_dist_1,
nb_dist_2,
amount_bought,
nb_product_bought,
active_time
FROM
test
LEFT JOIN (
SELECT
user_id,
COUNT(product_id) as nb_products_seen,
COUNT(distinct product_id) as nb_distinct_product,
COUNT(distinct category_id_0) as nb_dist_0,
COUNT(distinct category_id_1) as nb_dist_1,
COUNT(distinct category_id_2) as nb_dist_2,
SUM(price::numeric * (event_type = 'buy_order')::int ) as amount_bought,
SUM((event_type = 'buy_order')::int ) as nb_product_bought,
EXTRACT(
EPOCH FROM (
TIMESTAMP '${churn_test_date}' - MIN(event_timestamp)
)
) / (3600*24) as active_time
FROM
events_complete
WHERE
event_timestamp < TIMESTAMP '${churn_test_date}'
GROUP BY
user_id
) features ON test.user_id = features.user_id
Once this is done, you just have to go back to your model and use it to score the test dataset. In the end, your Dataiku Flow should look like this:
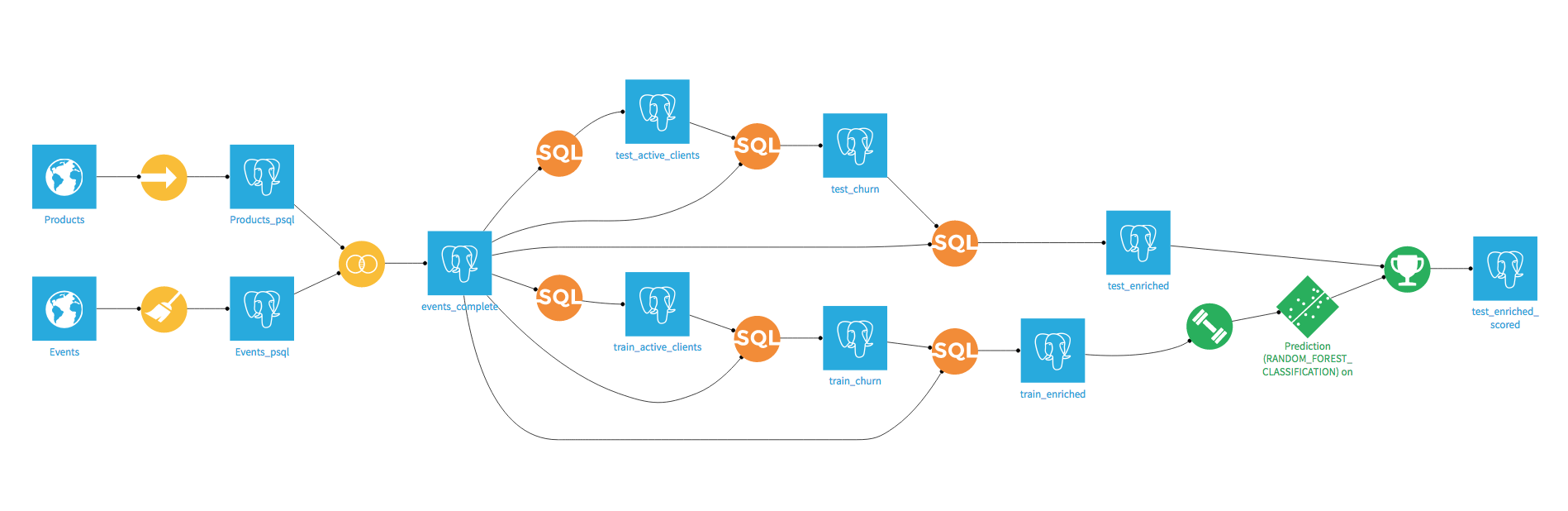
Even though we made great progress, we still have work to do. The major problem is that we didn’t take time into account to separate (by design of churn) our train and test sets, neither in the evaluation of our model, nor in the features engineering. Let’s see why this can be a big mistake.